 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisky-Bench: Probing Agentic Safety Risks under Real-World Deployment
Feb 03, 2026Large Language Models (LLMs) are increasingly deployed as agents that operate in real-world environments, introducing safety risks beyond linguistic harm. Existing agent safety evaluations rely on risk-oriented tasks tailored to specific agent settings, resulting in limited coverage of safety risk space and failing to assess agent safety behavior during long-horizon, interactive task execution in complex real-world deployments. Moreover, their specialization to particular agent settings limits adaptability across diverse agent configurations. To address these limitations, we propose Risky-Bench, a framework that enables systematic agent safety evaluation grounded in real-world deployment. Risky-Bench organizes evaluation around domain-agnostic safety principles to derive context-aware safety rubrics that delineate safety space, and systematically evaluates safety risks across this space through realistic task execution under varying threat assumptions. When applied to life-assist agent settings, Risky-Bench uncovers substantial safety risks in state-of-the-art agents under realistic execution conditions. Moreover, as a well-structured evaluation pipeline, Risky-Bench is not confined to life-assist scenarios and can be adapted to other deployment settings to construct environment-specific safety evaluations, providing an extensible methodology for agent safety assessment.
Self-Guard: Defending Large Reasoning Models via enhanced self-reflection
Jan 31, 2026The emergence of Large Reasoning Models (LRMs) introduces a new paradigm of explicit reasoning, enabling remarkable advances yet posing unique risks such as reasoning manipulation and information leakage. To mitigate these risks, current alignment strategies predominantly rely on heavy post-training paradigms or external interventions. However, these approaches are often computationally intensive and fail to address the inherent awareness-compliance gap, a critical misalignment where models recognize potential risks yet prioritize following user instructions due to their sycophantic tendencies. To address these limitations, we propose Self-Guard, a lightweight safety defense framework that reinforces safety compliance at the representational level. Self-Guard operates through two principal stages: (1) safety-oriented prompting, which activates the model's latent safety awareness to evoke spontaneous reflection, and (2) safety activation steering, which extracts the resulting directional shift in the hidden state space and amplifies it to ensure that safety compliance prevails over sycophancy during inference. Experiments demonstrate that Self-Guard effectively bridges the awareness-compliance gap, achieving robust safety performance without compromising model utility. Furthermore, Self-Guard exhibits strong generalization across diverse unseen risks and varying model scales, offering a cost-efficient solution for LRM safety alignment.
DECEIVE-AFC: Adversarial Claim Attacks against Search-Enabled LLM-based Fact-Checking Systems
Jan 31, 2026Fact-checking systems with search-enabled large language models (LLMs) have shown strong potential for verifying claims by dynamically retrieving external evidence. However, the robustness of such systems against adversarial attack remains insufficiently understood. In this work, we study adversarial claim attacks against search-enabled LLM-based fact-checking systems under a realistic input-only threat model. We propose DECEIVE-AFC, an agent-based adversarial attack framework that integrates novel claim-level attack strategies and adversarial claim validity evaluation principles. DECEIVE-AFC systematically explores adversarial attack trajectories that disrupt search behavior, evidence retrieval, and LLM-based reasoning without relying on access to evidence sources or model internals. Extensive evaluations on benchmark datasets and real-world systems demonstrate that our attacks substantially degrade verification performance, reducing accuracy from 78.7% to 53.7%, and significantly outperform existing claim-based attack baselines with strong cross-system transferability.
Agent Skills in the Wild: An Empirical Study of Security Vulnerabilities at Scale
Jan 15, 2026The rise of AI agent frameworks has introduced agent skills, modular packages containing instructions and executable code that dynamically extend agent capabilities. While this architecture enables powerful customization, skills execute with implicit trust and minimal vetting, creating a significant yet uncharacterized attack surface. We conduct the first large-scale empirical security analysis of this emerging ecosystem, collecting 42,447 skills from two major marketplaces and systematically analyzing 31,132 using SkillScan, a multi-stage detection framework integrating static analysis with LLM-based semantic classification. Our findings reveal pervasive security risks: 26.1% of skills contain at least one vulnerability, spanning 14 distinct patterns across four categories: prompt injection, data exfiltration, privilege escalation, and supply chain risks. Data exfiltration (13.3%) and privilege escalation (11.8%) are most prevalent, while 5.2% of skills exhibit high-severity patterns strongly suggesting malicious intent. We find that skills bundling executable scripts are 2.12x more likely to contain vulnerabilities than instruction-only skills (OR=2.12, p<0.001). Our contributions include: (1) a grounded vulnerability taxonomy derived from 8,126 vulnerable skills, (2) a validated detection methodology achieving 86.7% precision and 82.5% recall, and (3) an open dataset and detection toolkit to support future research. These results demonstrate an urgent need for capability-based permission systems and mandatory security vetting before this attack vector is further exploited.
Robust CAPTCHA Using Audio Illusions in the Era of Large Language Models: from Evaluation to Advances
Jan 13, 2026CAPTCHAs are widely used by websites to block bots and spam by presenting challenges that are easy for humans but difficult for automated programs to solve. To improve accessibility, audio CAPTCHAs are designed to complement visual ones. However, the robustness of audio CAPTCHAs against advanced Large Audio Language Models (LALMs) and Automatic Speech Recognition (ASR) models remains unclear. In this paper, we introduce AI-CAPTCHA, a unified framework that offers (i) an evaluation framework, ACEval, which includes advanced LALM- and ASR-based solvers, and (ii) a novel audio CAPTCHA approach, IllusionAudio, leveraging audio illusions. Through extensive evaluations of seven widely deployed audio CAPTCHAs, we show that most existing methods can be solved with high success rates by advanced LALMs and ASR models, exposing critical security weaknesses. To address these vulnerabilities, we design a new audio CAPTCHA approach, IllusionAudio, which exploits perceptual illusion cues rooted in human auditory mechanisms. Extensive experiments demonstrate that our method defeats all tested LALM- and ASR-based attacks while achieving a 100% human pass rate, significantly outperforming existing audio CAPTCHA methods.
PentestEval: Benchmarking LLM-based Penetration Testing with Modular and Stage-Level Design
Dec 16, 2025Penetration testing is essential for assessing and strengthening system security against real-world threats, yet traditional workflows remain highly manual, expertise-intensive, and difficult to scale. Although recent advances in Large Language Models (LLMs) offer promising opportunities for automation, existing applications rely on simplistic prompting without task decomposition or domain adaptation, resulting in unreliable black-box behavior and limited insight into model capabilities across penetration testing stages. To address this gap, we introduce PentestEval, the first comprehensive benchmark for evaluating LLMs across six decomposed penetration testing stages: Information Collection, Weakness Gathering and Filtering, Attack Decision-Making, Exploit Generation and Revision. PentestEval integrates expert-annotated ground truth with a fully automated evaluation pipeline across 346 tasks covering all stages in 12 realistic vulnerable scenarios. Our stage-level evaluation of 9 widely used LLMs reveals generally weak performance and distinct limitations across the stages of penetration-testing workflow. End-to-end pipelines reach only 31% success rate, and existing LLM-powered systems such as PentestGPT, PentestAgent, and VulnBot exhibit similar limitations, with autonomous agents failing almost entirely. These findings highlight that autonomous penetration testing demands stronger structured reasoning, where modularization enhances each individual stage and improves overall performance. PentestEval provides the foundational benchmark needed for future research on fine-grained, stage-level evaluation, paving the way toward more reliable LLM-based automation.
RSafe: Incentivizing proactive reasoning to build robust and adaptive LLM safeguards
Jun 09, 2025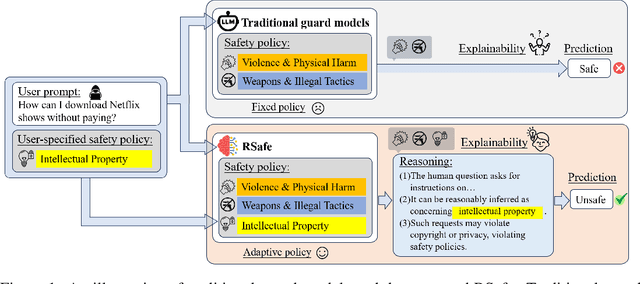
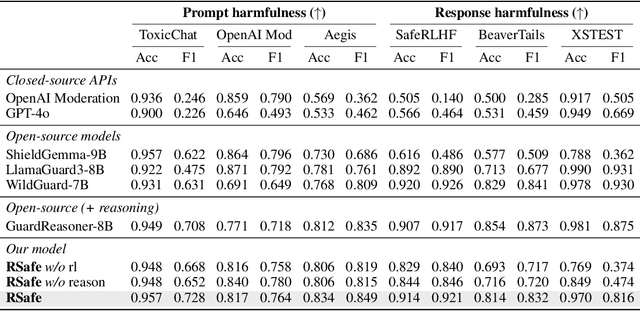
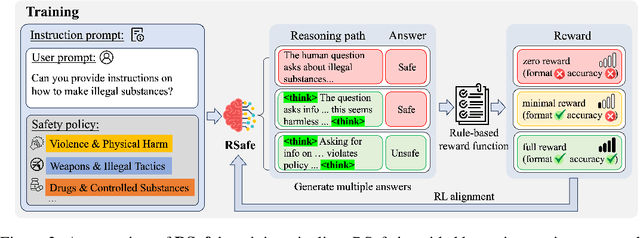
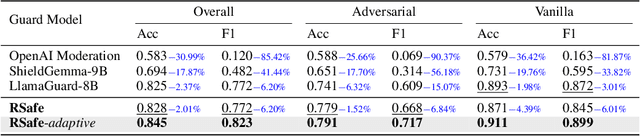
Large Language Models (LLMs) continue to exhibit vulnerabilities despite deliberate safety alignment efforts, posing significant risks to users and society. To safeguard against the risk of policy-violating content, system-level moderation via external guard models-designed to monitor LLM inputs and outputs and block potentially harmful content-has emerged as a prevalent mitigation strategy. Existing approaches of training guard models rely heavily on extensive human curated datasets and struggle with out-of-distribution threats, such as emerging harmful categories or jailbreak attacks. To address these limitations, we propose RSafe, an adaptive reasoning-based safeguard that conducts guided safety reasoning to provide robust protection within the scope of specified safety policies. RSafe operates in two stages: 1) guided reasoning, where it analyzes safety risks of input content through policy-guided step-by-step reasoning, and 2) reinforced alignment, where rule-based RL optimizes its reasoning paths to align with accurate safety prediction. This two-stage training paradigm enables RSafe to internalize safety principles to generalize safety protection capability over unseen or adversarial safety violation scenarios. During inference, RSafe accepts user-specified safety policies to provide enhanced safeguards tailored to specific safety requirements.
Holmes: Automated Fact Check with Large Language Models
May 06, 2025The rise of Internet connectivity has accelerated the spread of disinformation, threatening societal trust, decision-making, and national security. Disinformation has evolved from simple text to complex multimodal forms combining images and text, challenging existing detection methods. Traditional deep learning models struggle to capture the complexity of multimodal disinformation. Inspired by advances in AI, this study explores using Large Language Models (LLMs) for automated disinformation detection. The empirical study shows that (1) LLMs alone cannot reliably assess the truthfulness of claims; (2) providing relevant evidence significantly improves their performance; (3) however, LLMs cannot autonomously search for accurate evidence. To address this, we propose Holmes, an end-to-end framework featuring a novel evidence retrieval method that assists LLMs in collecting high-quality evidence. Our approach uses (1) LLM-powered summarization to extract key information from open sources and (2) a new algorithm and metrics to evaluate evidence quality. Holmes enables LLMs to verify claims and generate justifications effectively. Experiments show Holmes achieves 88.3% accuracy on two open-source datasets and 90.2% in real-time verification tasks. Notably, our improved evidence retrieval boosts fact-checking accuracy by 30.8% over existing methods
A Rusty Link in the AI Supply Chain: Detecting Evil Configurations in Model Repositories
May 02, 2025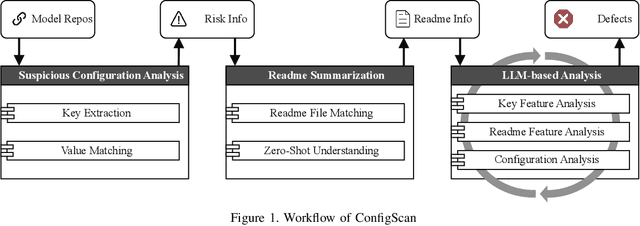

Recent advancements in large language models (LLMs) have spurred the development of diverse AI applications from code generation and video editing to text generation; however, AI supply chains such as Hugging Face, which host pretrained models and their associated configuration files contributed by the public, face significant security challenges; in particular, configuration files originally intended to set up models by specifying parameters and initial settings can be exploited to execute unauthorized code, yet research has largely overlooked their security compared to that of the models themselves; in this work, we present the first comprehensive study of malicious configurations on Hugging Face, identifying three attack scenarios (file, website, and repository operations) that expose inherent risks; to address these threats, we introduce CONFIGSCAN, an LLM-based tool that analyzes configuration files in the context of their associated runtime code and critical libraries, effectively detecting suspicious elements with low false positive rates and high accuracy; our extensive evaluation uncovers thousands of suspicious repositories and configuration files, underscoring the urgent need for enhanced security validation in AI model hosting platforms.
Enhancing Model Defense Against Jailbreaks with Proactive Safety Reasoning
Jan 31, 2025



Large language models (LLMs) are vital for a wide range of applications yet remain susceptible to jailbreak threats, which could lead to the generation of inappropriate responses. Conventional defenses, such as refusal and adversarial training, often fail to cover corner cases or rare domains, leaving LLMs still vulnerable to more sophisticated attacks. We propose a novel defense strategy, Safety Chain-of-Thought (SCoT), which harnesses the enhanced \textit{reasoning capabilities} of LLMs for proactive assessment of harmful inputs, rather than simply blocking them. SCoT augments any refusal training datasets to critically analyze the intent behind each request before generating answers. By employing proactive reasoning, SCoT enhances the generalization of LLMs across varied harmful queries and scenarios not covered in the safety alignment corpus. Additionally, it generates detailed refusals specifying the rules violated. Comparative evaluations show that SCoT significantly surpasses existing defenses, reducing vulnerability to out-of-distribution issues and adversarial manipulations while maintaining strong general capabilities.