 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJanus-LoRA: A Balanced Low-Rank Adaptation for Continual Learning
May 27, 2026Low-Rank Adaptation (LoRA) has emerged as a promising paradigm for Continual Learning. It independently updates its low-rank factors ($A$ and $B$), creating a composite update to the full weight matrix through their interaction. To prevent catastrophic forgetting, this update should remain orthogonal to the task-specific subspace that contains previously learned knowledge. However, we identify that this composite update systematically violates this orthogonality, reintroducing interference and undermining stability. Furthermore, naively enforcing this orthogonality compromises plasticity, disrupting the delicate stability-plasticity trade-off. To resolve these issues, we propose \textbf{Janus-LoRA}, a framework that restores this balance through two novel components. Specifically, we first introduce Gradient Rectification, a closed-form solution that mathematically decouples LoRA's factor updates, enforcing orthogonality against the historical knowledge subspace identified by an efficient Online Estimation. Next, to enhance plasticity, we introduce a Decoupled Margin Loss that promotes feature-level separation by pushing new feature representations away from old ones, thus creating distinct, low-interference regions for new learning. Comprehensive experiments on challenging benchmarks demonstrate that by harmonizing parameter-level orthogonality with feature-level separation, Janus-LoRA achieves a superior balance and establishes new state-of-the-art performance.
Structure-aware Prompt Adaptation from Seen to Unseen for Open-Vocabulary Compositional Zero-Shot Learning
Mar 04, 2026The goal of Open-Vocabulary Compositional Zero-Shot Learning (OV-CZSL) is to recognize attribute-object compositions in the open-vocabulary setting, where compositions of both seen and unseen attributes and objects are evaluated. Recently, prompt tuning methods have demonstrated strong generalization capabilities in the closed setting, where only compositions of seen attributes and objects are evaluated, i.e., Compositional Zero-Shot Learning (CZSL). However, directly applying these methods to OV-CZSL may not be sufficient to generalize to unseen attributes, objects and their compositions, as it is limited to seen attributes and objects. Normally, when faced with unseen concepts, humans adopt analogies with seen concepts that have the similar semantics thereby inferring their meaning (e.g., "wet" and "damp", "shirt" and "jacket"). In this paper, we experimentally show that the distribution of semantically related attributes or objects tends to form consistent local structures in the embedding space. Based on the above structures, we propose Structure-aware Prompt Adaptation (SPA) method, which enables models to generalize from seen to unseen attributes and objects. Specifically, in the training stage, we design a Structure-aware Consistency Loss (SCL) that encourages the local structure's consistency of seen attributes and objects in each iteration. In the inference stage, we devise a Structure-guided Adaptation Strategy (SAS) that adaptively aligns the structures of unseen attributes and objects with those of trained seen attributes and objects with similar semantics. Notably, SPA is a plug-and-play method that can be seamlessly integrated into existing CZSL prompt tuning methods. Extensive experiments on OV-CZSL benchmarks demonstrate that SPA achieves competitive closed-set performance while significantly improving open-vocabulary results.
TIMI: Training-Free Image-to-3D Multi-Instance Generation with Spatial Fidelity
Mar 02, 2026Precise spatial fidelity in Image-to-3D multi-instance generation is critical for downstream real-world applications. Recent work attempts to address this by fine-tuning pre-trained Image-to-3D (I23D) models on multi-instance datasets, which incurs substantial training overhead and struggles to guarantee spatial fidelity. In fact, we observe that pre-trained I23D models already possess meaningful spatial priors, which remain underutilized as evidenced by instance entanglement issues. Motivated by this, we propose TIMI, a novel Training-free framework for Image-to-3D Multi-Instance generation that achieves high spatial fidelity. Specifically, we first introduce an Instance-aware Separation Guidance (ISG) module, which facilitates instance disentanglement during the early denoising stage. Next, to stabilize the guidance introduced by ISG, we devise a Spatial-stabilized Geometry-adaptive Update (SGU) module that promotes the preservation of the geometric characteristics of instances while maintaining their relative relationships. Extensive experiments demonstrate that our method yields better performance in terms of both global layout and distinct local instances compared to existing multi-instance methods, without requiring additional training and with faster inference speed.
Benchmarking Few-shot Transferability of Pre-trained Models with Improved Evaluation Protocols
Feb 28, 2026Few-shot transfer has been revolutionized by stronger pre-trained models and improved adaptation algorithms.However, there lacks a unified, rigorous evaluation protocol that is both challenging and realistic for real-world usage. In this work, we establish FEWTRANS, a comprehensive benchmark containing 10 diverse datasets, and propose the Hyperparameter Ensemble (HPE) protocol to overcome the "validation set illusion" in data-scarce regimes. Our empirical findings demonstrate that the choice of pre-trained model is the dominant factor for performance, while many sophisticated transfer methods offer negligible practical advantages over a simple full-parameter fine-tuning baseline. To explain this surprising effectiveness, we provide an in-depth mechanistic analysis showing that full fine-tuning succeeds via distributed micro-adjustments and more flexible reshaping of high-level semantic presentations without suffering from overfitting. Additionally, we quantify the performance collapse of multimodal models in specialized domains as a result of linguistic rarity using adjusted Zipf frequency scores. By releasing FEWTRANS, we aim to provide a rigorous "ruler" to streamline reproducible advances in few-shot transfer learning research. We make the FEWTRANS benchmark publicly available at https://github.com/Frankluox/FewTrans.
Beyond the Majority: Long-tail Imitation Learning for Robotic Manipulation
Feb 06, 2026While generalist robot policies hold significant promise for learning diverse manipulation skills through imitation, their performance is often hindered by the long-tail distribution of training demonstrations. Policies learned on such data, which is heavily skewed towards a few data-rich head tasks, frequently exhibit poor generalization when confronted with the vast number of data-scarce tail tasks. In this work, we conduct a comprehensive analysis of the pervasive long-tail challenge inherent in policy learning. Our analysis begins by demonstrating the inefficacy of conventional long-tail learning strategies (e.g., re-sampling) for improving the policy's performance on tail tasks. We then uncover the underlying mechanism for this failure, revealing that data scarcity on tail tasks directly impairs the policy's spatial reasoning capability. To overcome this, we introduce Approaching-Phase Augmentation (APA), a simple yet effective scheme that transfers knowledge from data-rich head tasks to data-scarce tail tasks without requiring external demonstrations. Extensive experiments in both simulation and real-world manipulation tasks demonstrate the effectiveness of APA. Our code and demos are publicly available at: https://mldxy.github.io/Project-VLA-long-tail/.
Sim-and-Human Co-training for Data-Efficient and Generalizable Robotic Manipulation
Jan 27, 2026Synthetic simulation data and real-world human data provide scalable alternatives to circumvent the prohibitive costs of robot data collection. However, these sources suffer from the sim-to-real visual gap and the human-to-robot embodiment gap, respectively, which limits the policy's generalization to real-world scenarios. In this work, we identify a natural yet underexplored complementarity between these sources: simulation offers the robot action that human data lacks, while human data provides the real-world observation that simulation struggles to render. Motivated by this insight, we present SimHum, a co-training framework to simultaneously extract kinematic prior from simulated robot actions and visual prior from real-world human observations. Based on the two complementary priors, we achieve data-efficient and generalizable robotic manipulation in real-world tasks. Empirically, SimHum outperforms the baseline by up to $\mathbf{40\%}$ under the same data collection budget, and achieves a $\mathbf{62.5\%}$ OOD success with only 80 real data, outperforming the real only baseline by $7.1\times$. Videos and additional information can be found at \href{https://kaipengfang.github.io/sim-and-human}{project website}.
From One-to-One to Many-to-Many: Dynamic Cross-Layer Injection for Deep Vision-Language Fusion
Jan 15, 2026Vision-Language Models (VLMs) create a severe visual feature bottleneck by using a crude, asymmetric connection that links only the output of the vision encoder to the input of the large language model (LLM). This static architecture fundamentally limits the ability of LLMs to achieve comprehensive alignment with hierarchical visual knowledge, compromising their capacity to accurately integrate local details with global semantics into coherent reasoning. To resolve this, we introduce Cross-Layer Injection (CLI), a novel and lightweight framework that forges a dynamic many-to-many bridge between the two modalities. CLI consists of two synergistic, parameter-efficient components: an Adaptive Multi-Projection (AMP) module that harmonizes features from diverse vision layers, and an Adaptive Gating Fusion (AGF) mechanism that empowers the LLM to selectively inject the most relevant visual information based on its real-time decoding context. We validate the effectiveness and versatility of CLI by integrating it into LLaVA-OneVision and LLaVA-1.5. Extensive experiments on 18 diverse benchmarks demonstrate significant performance improvements, establishing CLI as a scalable paradigm that unlocks deeper multimodal understanding by granting LLMs on-demand access to the full visual hierarchy.
MiVLA: Towards Generalizable Vision-Language-Action Model with Human-Robot Mutual Imitation Pre-training
Dec 19, 2025While leveraging abundant human videos and simulated robot data poses a scalable solution to the scarcity of real-world robot data, the generalization capability of existing vision-language-action models (VLAs) remains limited by mismatches in camera views, visual appearance, and embodiment morphologies. To overcome this limitation, we propose MiVLA, a generalizable VLA empowered by human-robot mutual imitation pre-training, which leverages inherent behavioral similarity between human hands and robotic arms to build a foundation of strong behavioral priors for both human actions and robotic control. Specifically, our method utilizes kinematic rules with left/right hand coordinate systems for bidirectional alignment between human and robot action spaces. Given human or simulated robot demonstrations, MiVLA is trained to forecast behavior trajectories for one embodiment, and imitate behaviors for another one unseen in the demonstration. Based on this mutual imitation, it integrates the behavioral fidelity of real-world human data with the manipulative diversity of simulated robot data into a unified model, thereby enhancing the generalization capability for downstream tasks. Extensive experiments conducted on both simulation and real-world platforms with three robots (ARX, PiPer and LocoMan), demonstrate that MiVLA achieves strong improved generalization capability, outperforming state-of-the-art VLAs (e.g., $\boldsymbolπ_{0}$, $\boldsymbolπ_{0.5}$ and H-RDT) by 25% in simulation, and 14% in real-world robot control tasks.
Learning Generalizable and Efficient Image Watermarking via Hierarchical Two-Stage Optimization
Aug 12, 2025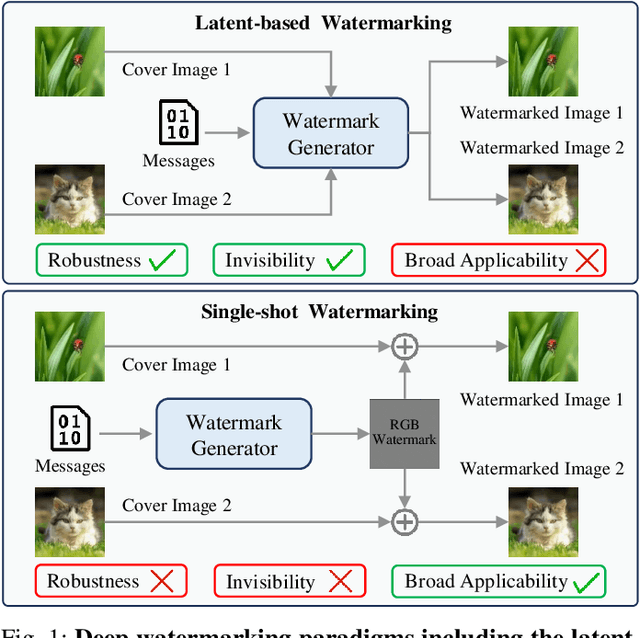

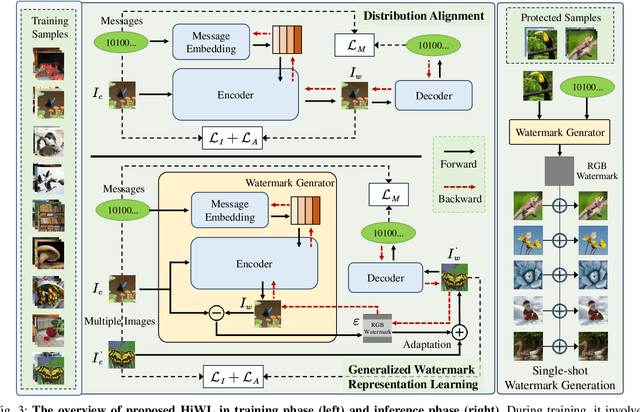

Deep image watermarking, which refers to enable imperceptible watermark embedding and reliable extraction in cover images, has shown to be effective for copyright protection of image assets. However, existing methods face limitations in simultaneously satisfying three essential criteria for generalizable watermarking: 1) invisibility (imperceptible hide of watermarks), 2) robustness (reliable watermark recovery under diverse conditions), and 3) broad applicability (low latency in watermarking process). To address these limitations, we propose a Hierarchical Watermark Learning (HiWL), a two-stage optimization that enable a watermarking model to simultaneously achieve three criteria. In the first stage, distribution alignment learning is designed to establish a common latent space with two constraints: 1) visual consistency between watermarked and non-watermarked images, and 2) information invariance across watermark latent representations. In this way, multi-modal inputs including watermark message (binary codes) and cover images (RGB pixels) can be well represented, ensuring the invisibility of watermarks and robustness in watermarking process thereby. The second stage employs generalized watermark representation learning to establish a disentanglement policy for separating watermarks from image content in RGB space. In particular, it strongly penalizes substantial fluctuations in separated RGB watermarks corresponding to identical messages. Consequently, HiWL effectively learns generalizable latent-space watermark representations while maintaining broad applicability. Extensive experiments demonstrate the effectiveness of proposed method. In particular, it achieves 7.6\% higher accuracy in watermark extraction than existing methods, while maintaining extremely low latency (100K images processed in 8s).
Dynamic Pattern Alignment Learning for Pretraining Lightweight Human-Centric Vision Models
Aug 10, 2025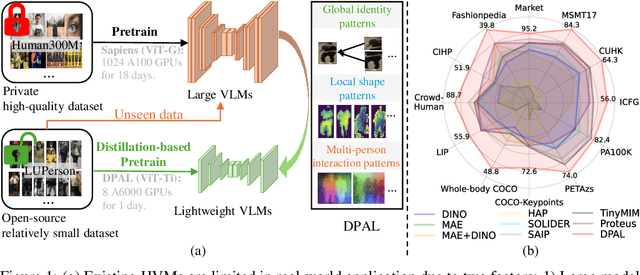
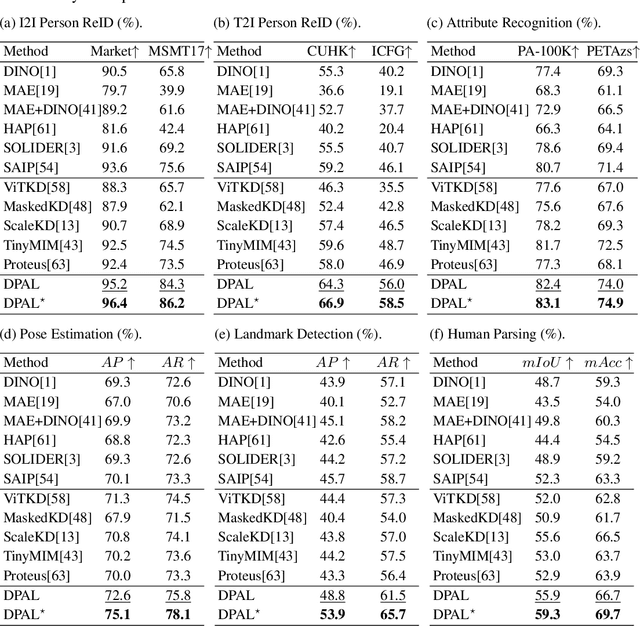
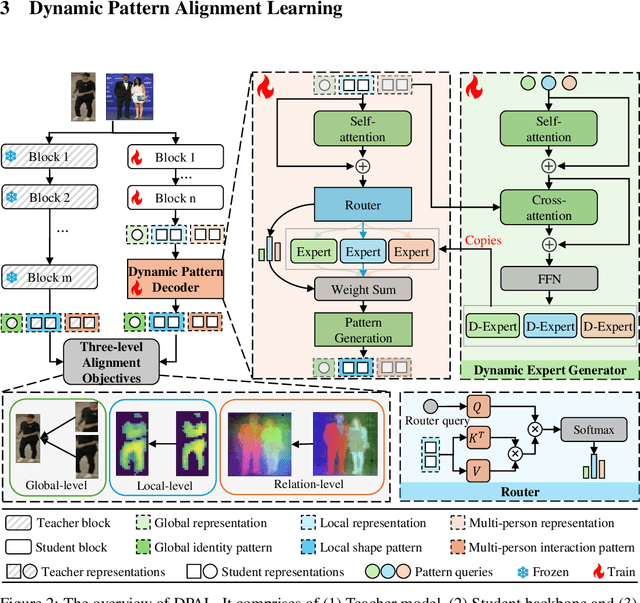
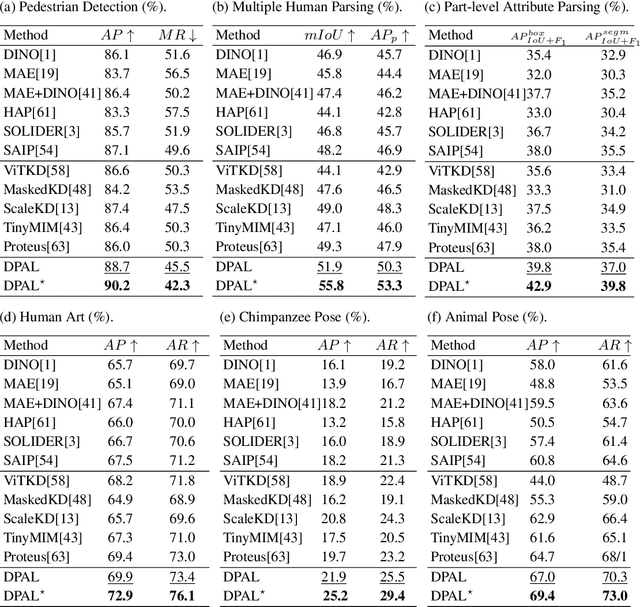
Human-centric vision models (HVMs) have achieved remarkable generalization due to large-scale pretraining on massive person images. However, their dependence on large neural architectures and the restricted accessibility of pretraining data significantly limits their practicality in real-world applications. To address this limitation, we propose Dynamic Pattern Alignment Learning (DPAL), a novel distillation-based pretraining framework that efficiently trains lightweight HVMs to acquire strong generalization from large HVMs. In particular, human-centric visual perception are highly dependent on three typical visual patterns, including global identity pattern, local shape pattern and multi-person interaction pattern. To achieve generalizable lightweight HVMs, we firstly design a dynamic pattern decoder (D-PaDe), acting as a dynamic Mixture of Expert (MoE) model. It incorporates three specialized experts dedicated to adaptively extract typical visual patterns, conditioned on both input image and pattern queries. And then, we present three levels of alignment objectives, which aims to minimize generalization gap between lightweight HVMs and large HVMs at global image level, local pixel level, and instance relation level. With these two deliberate designs, the DPAL effectively guides lightweight model to learn all typical human visual patterns from large HVMs, which can generalize to various human-centric vision tasks. Extensive experiments conducted on 15 challenging datasets demonstrate the effectiveness of the DPAL. Remarkably, when employing PATH-B as the teacher, DPAL-ViT/Ti (5M parameters) achieves surprising generalizability similar to existing large HVMs such as PATH-B (84M) and Sapiens-L (307M), and outperforms previous distillation-based pretraining methods including Proteus-ViT/Ti (5M) and TinyMiM-ViT/Ti (5M) by a large margin.