 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIMI: Training-Free Image-to-3D Multi-Instance Generation with Spatial Fidelity
Mar 02, 2026Precise spatial fidelity in Image-to-3D multi-instance generation is critical for downstream real-world applications. Recent work attempts to address this by fine-tuning pre-trained Image-to-3D (I23D) models on multi-instance datasets, which incurs substantial training overhead and struggles to guarantee spatial fidelity. In fact, we observe that pre-trained I23D models already possess meaningful spatial priors, which remain underutilized as evidenced by instance entanglement issues. Motivated by this, we propose TIMI, a novel Training-free framework for Image-to-3D Multi-Instance generation that achieves high spatial fidelity. Specifically, we first introduce an Instance-aware Separation Guidance (ISG) module, which facilitates instance disentanglement during the early denoising stage. Next, to stabilize the guidance introduced by ISG, we devise a Spatial-stabilized Geometry-adaptive Update (SGU) module that promotes the preservation of the geometric characteristics of instances while maintaining their relative relationships. Extensive experiments demonstrate that our method yields better performance in terms of both global layout and distinct local instances compared to existing multi-instance methods, without requiring additional training and with faster inference speed.
Towards Generalized and Training-Free Text-Guided Semantic Manipulation
Apr 24, 2025



Text-guided semantic manipulation refers to semantically editing an image generated from a source prompt to match a target prompt, enabling the desired semantic changes (e.g., addition, removal, and style transfer) while preserving irrelevant contents. With the powerful generative capabilities of the diffusion model, the task has shown the potential to generate high-fidelity visual content. Nevertheless, existing methods either typically require time-consuming fine-tuning (inefficient), fail to accomplish multiple semantic manipulations (poorly extensible), and/or lack support for different modality tasks (limited generalizability). Upon further investigation, we find that the geometric properties of noises in the diffusion model are strongly correlated with the semantic changes. Motivated by this, we propose a novel $\textit{GTF}$ for text-guided semantic manipulation, which has the following attractive capabilities: 1) $\textbf{Generalized}$: our $\textit{GTF}$ supports multiple semantic manipulations (e.g., addition, removal, and style transfer) and can be seamlessly integrated into all diffusion-based methods (i.e., Plug-and-play) across different modalities (i.e., modality-agnostic); and 2) $\textbf{Training-free}$: $\textit{GTF}$ produces high-fidelity results via simply controlling the geometric relationship between noises without tuning or optimization. Our extensive experiments demonstrate the efficacy of our approach, highlighting its potential to advance the state-of-the-art in semantics manipulation.
GT23D-Bench: A Comprehensive General Text-to-3D Generation Benchmark
Dec 13, 2024Recent advances in General Text-to-3D (GT23D) have been significant. However, the lack of a benchmark has hindered systematic evaluation and progress due to issues in datasets and metrics: 1) The largest 3D dataset Objaverse suffers from omitted annotations, disorganization, and low-quality. 2) Existing metrics only evaluate textual-image alignment without considering the 3D-level quality. To this end, we are the first to present a comprehensive benchmark for GT23D called GT23D-Bench consisting of: 1) a 400k high-fidelity and well-organized 3D dataset that curated issues in Objaverse through a systematical annotation-organize-filter pipeline; and 2) comprehensive 3D-aware evaluation metrics which encompass 10 clearly defined metrics thoroughly accounting for multi-dimension of GT23D. Notably, GT23D-Bench features three properties: 1) Multimodal Annotations. Our dataset annotates each 3D object with 64-view depth maps, normal maps, rendered images, and coarse-to-fine captions. 2) Holistic Evaluation Dimensions. Our metrics are dissected into a) Textual-3D Alignment measures textual alignment with multi-granularity visual 3D representations; and b) 3D Visual Quality which considers texture fidelity, multi-view consistency, and geometry correctness. 3) Valuable Insights. We delve into the performance of current GT23D baselines across different evaluation dimensions and provide insightful analysis. Extensive experiments demonstrate that our annotations and metrics are aligned with human preferences.
Skill-LLM: Repurposing General-Purpose LLMs for Skill Extraction
Oct 15, 2024
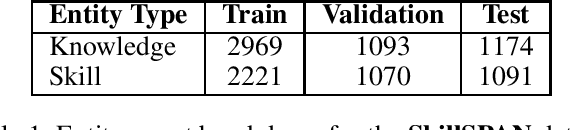

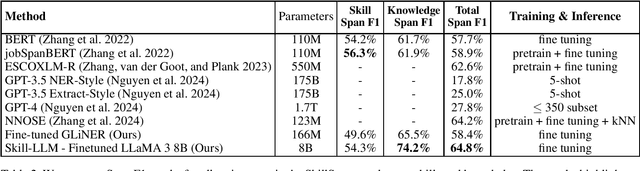
Accurate skill extraction from job descriptions is crucial in the hiring process but remains challenging. Named Entity Recognition (NER) is a common approach used to address this issue. With the demonstrated success of large language models (LLMs) in various NLP tasks, including NER, we propose fine-tuning a specialized Skill-LLM and a light weight model to improve the precision and quality of skill extraction. In our study, we evaluated the fine-tuned Skill-LLM and the light weight model using a benchmark dataset and compared its performance against state-of-the-art (SOTA) methods. Our results show that this approach outperforms existing SOTA techniques.
SeMv-3D: Towards Semantic and Mutil-view Consistency simultaneously for General Text-to-3D Generation with Triplane Priors
Oct 10, 2024Recent advancements in generic 3D content generation from text prompts have been remarkable by fine-tuning text-to-image diffusion (T2I) models or employing these T2I models as priors to learn a general text-to-3D model. While fine-tuning-based methods ensure great alignment between text and generated views, i.e., semantic consistency, their ability to achieve multi-view consistency is hampered by the absence of 3D constraints, even in limited view. In contrast, prior-based methods focus on regressing 3D shapes with any view that maintains uniformity and coherence across views, i.e., multi-view consistency, but such approaches inevitably compromise visual-textual alignment, leading to a loss of semantic details in the generated objects. To achieve semantic and multi-view consistency simultaneously, we propose SeMv-3D, a novel framework for general text-to-3d generation. Specifically, we propose a Triplane Prior Learner (TPL) that learns triplane priors with 3D spatial features to maintain consistency among different views at the 3D level, e.g., geometry and texture. Moreover, we design a Semantic-aligned View Synthesizer (SVS) that preserves the alignment between 3D spatial features and textual semantics in latent space. In SVS, we devise a simple yet effective batch sampling and rendering strategy that can generate arbitrary views in a single feed-forward inference. Extensive experiments present our SeMv-3D's superiority over state-of-the-art performances with semantic and multi-view consistency in any view. Our code and more visual results are available at https://anonymous.4open.science/r/SeMv-3D-6425.
A Closed Form Solution to Multi-View Low-Rank Regression
Oct 14, 2016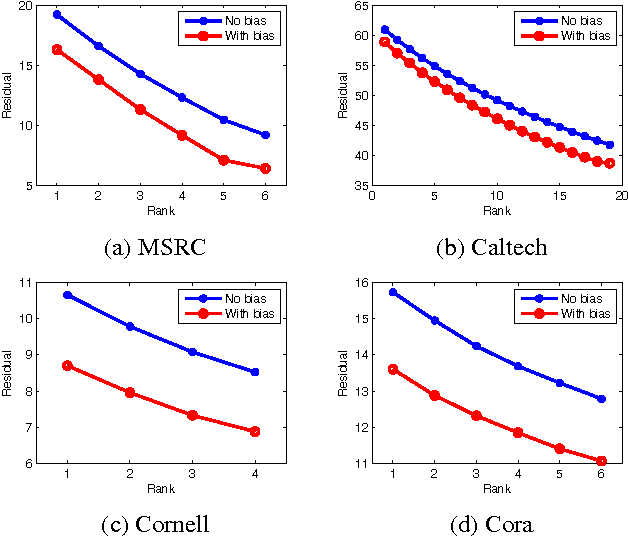
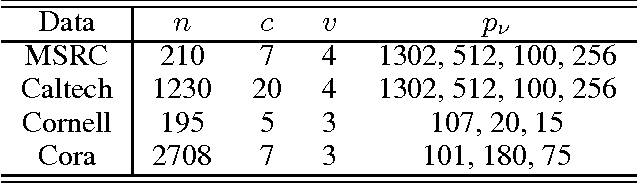
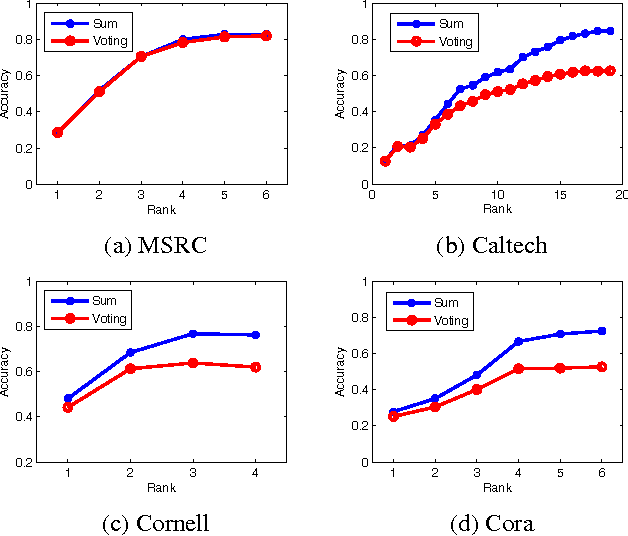
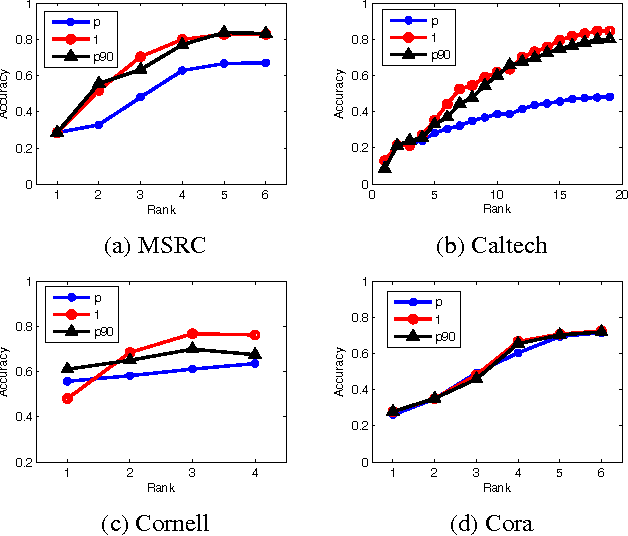
Real life data often includes information from different channels. For example, in computer vision, we can describe an image using different image features, such as pixel intensity, color, HOG, GIST feature, SIFT features, etc.. These different aspects of the same objects are often called multi-view (or multi-modal) data. Low-rank regression model has been proved to be an effective learning mechanism by exploring the low-rank structure of real life data. But previous low-rank regression model only works on single view data. In this paper, we propose a multi-view low-rank regression model by imposing low-rank constraints on multi-view regression model. Most importantly, we provide a closed-form solution to the multi-view low-rank regression model. Extensive experiments on 4 multi-view datasets show that the multi-view low-rank regression model outperforms single-view regression model and reveals that multi-view low-rank structure is very helpful.