 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEPOCH: An Agentic Protocol for Multi-Round System Optimization
Mar 10, 2026Autonomous agents are increasingly used to improve prompts, code, and machine learning systems through iterative execution and feedback. Yet existing approaches are usually designed as task-specific optimization loops rather than as a unified protocol for establishing baselines and managing tracked multi-round self-improvement. We introduce EPOCH, an engineering protocol for multi-round system optimization in heterogeneous environments. EPOCH organizes optimization into two phases: baseline construction and iterative self-improvement. It further structures each round through role-constrained stages that separate planning, implementation, and evaluation, and standardizes execution through canonical command interfaces and round-level tracking. This design enables coordinated optimization across prompts, model configurations, code, and rule-based components while preserving stability, reproducibility, traceability, and integrity of evaluation. Empirical studies in various tasks illustrate the practicality of EPOCH for production-oriented autonomous improvement workflows.
Skill-LLM: Repurposing General-Purpose LLMs for Skill Extraction
Oct 15, 2024
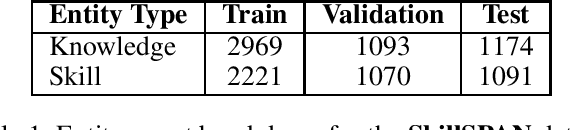

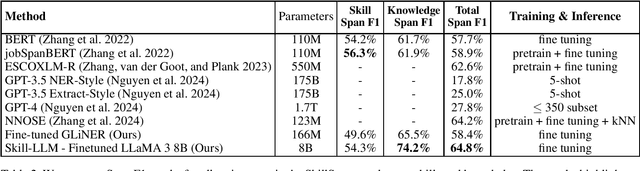
Accurate skill extraction from job descriptions is crucial in the hiring process but remains challenging. Named Entity Recognition (NER) is a common approach used to address this issue. With the demonstrated success of large language models (LLMs) in various NLP tasks, including NER, we propose fine-tuning a specialized Skill-LLM and a light weight model to improve the precision and quality of skill extraction. In our study, we evaluated the fine-tuned Skill-LLM and the light weight model using a benchmark dataset and compared its performance against state-of-the-art (SOTA) methods. Our results show that this approach outperforms existing SOTA techniques.
MGS-SLAM: Monocular Sparse Tracking and Gaussian Mapping with Depth Smooth Regularization
May 10, 2024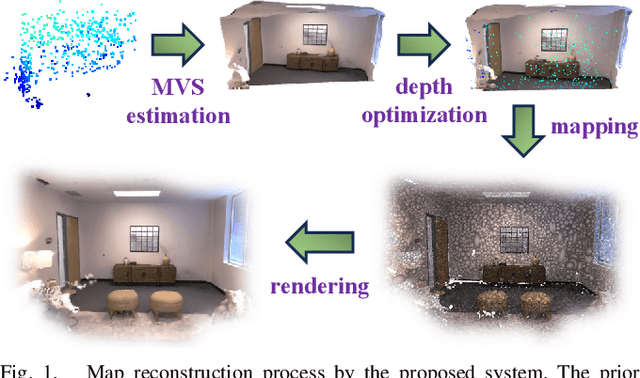
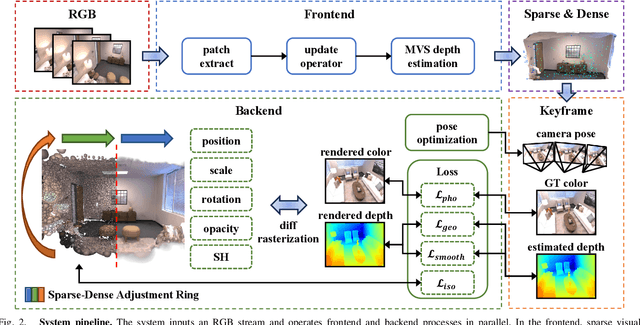
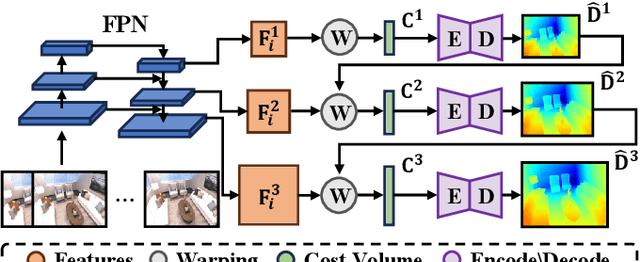
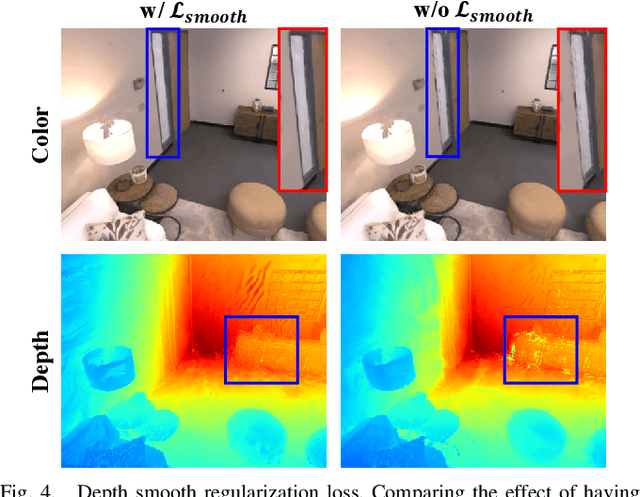
This letter introduces a novel framework for dense Visual Simultaneous Localization and Mapping (VSLAM) based on Gaussian Splatting. Recently Gaussian Splatting-based SLAM has yielded promising results, but rely on RGB-D input and is weak in tracking. To address these limitations, we uniquely integrates advanced sparse visual odometry with a dense Gaussian Splatting scene representation for the first time, thereby eliminating the dependency on depth maps typical of Gaussian Splatting-based SLAM systems and enhancing tracking robustness. Here, the sparse visual odometry tracks camera poses in RGB stream, while Gaussian Splatting handles map reconstruction. These components are interconnected through a Multi-View Stereo (MVS) depth estimation network. And we propose a depth smooth loss to reduce the negative effect of estimated depth maps. Furthermore, the consistency in scale between the sparse visual odometry and the dense Gaussian map is preserved by Sparse-Dense Adjustment Ring (SDAR). We have evaluated our system across various synthetic and real-world datasets. The accuracy of our pose estimation surpasses existing methods and achieves state-of-the-art performance. Additionally, it outperforms previous monocular methods in terms of novel view synthesis fidelity, matching the results of neural SLAM systems that utilize RGB-D input.
Amos-SLAM: An Anti-Dynamics Two-stage SLAM Approach
Feb 23, 2023



The traditional Simultaneous Localization And Mapping (SLAM) systems rely on the assumption of a static environment and fail to accurately estimate the system's location when dynamic objects are present in the background. While learning-based dynamic SLAM systems have difficulties in handling unknown moving objects, geometry-based methods have limited success in addressing the residual effects of unidentified dynamic objects on location estimation. To address these issues, we propose an anti-dynamics two-stage SLAM approach. Firstly, the potential motion regions of both prior and non-prior dynamic objects are extracted and pose estimates for dynamic discrimination are quickly obtained using optical flow tracking and model generation methods. Secondly, dynamic points in each frame are removed through dynamic judgment. For non-prior dynamic objects, we present a approach that uses super-pixel extraction and geometric clustering to determine the potential motion regions based on color and geometric information in the image. Evaluations on multiple low and high dynamic sequences in a public RGB-D dataset show that our proposed method outperforms state-of-the-art dynamic SLAM methods.