 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMGS-SLAM: Monocular Sparse Tracking and Gaussian Mapping with Depth Smooth Regularization
May 10, 2024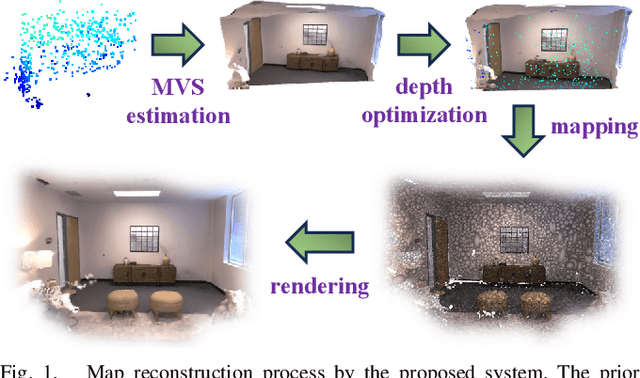
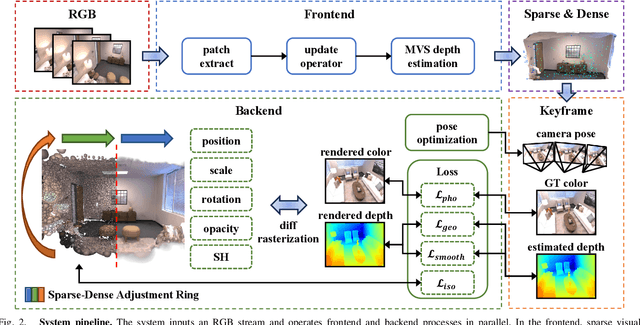
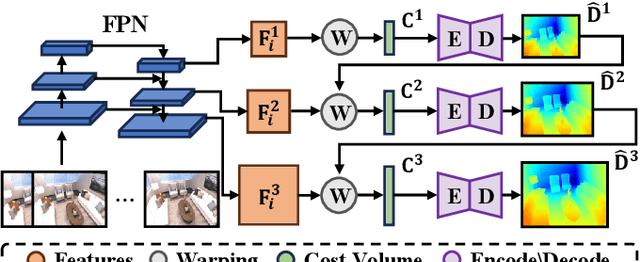
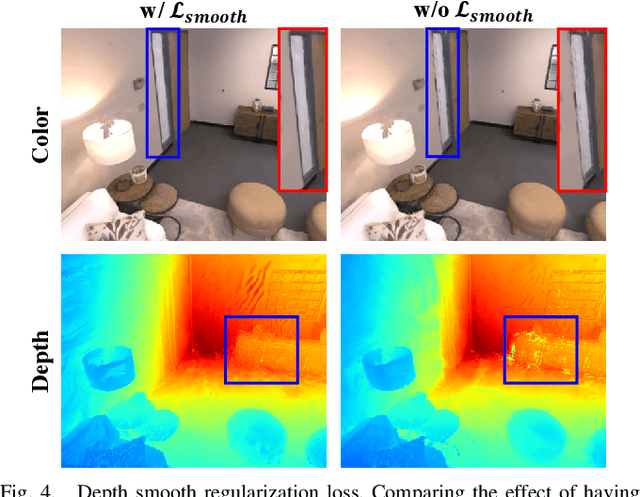
This letter introduces a novel framework for dense Visual Simultaneous Localization and Mapping (VSLAM) based on Gaussian Splatting. Recently Gaussian Splatting-based SLAM has yielded promising results, but rely on RGB-D input and is weak in tracking. To address these limitations, we uniquely integrates advanced sparse visual odometry with a dense Gaussian Splatting scene representation for the first time, thereby eliminating the dependency on depth maps typical of Gaussian Splatting-based SLAM systems and enhancing tracking robustness. Here, the sparse visual odometry tracks camera poses in RGB stream, while Gaussian Splatting handles map reconstruction. These components are interconnected through a Multi-View Stereo (MVS) depth estimation network. And we propose a depth smooth loss to reduce the negative effect of estimated depth maps. Furthermore, the consistency in scale between the sparse visual odometry and the dense Gaussian map is preserved by Sparse-Dense Adjustment Ring (SDAR). We have evaluated our system across various synthetic and real-world datasets. The accuracy of our pose estimation surpasses existing methods and achieves state-of-the-art performance. Additionally, it outperforms previous monocular methods in terms of novel view synthesis fidelity, matching the results of neural SLAM systems that utilize RGB-D input.
Amos-SLAM: An Anti-Dynamics Two-stage SLAM Approach
Feb 23, 2023



The traditional Simultaneous Localization And Mapping (SLAM) systems rely on the assumption of a static environment and fail to accurately estimate the system's location when dynamic objects are present in the background. While learning-based dynamic SLAM systems have difficulties in handling unknown moving objects, geometry-based methods have limited success in addressing the residual effects of unidentified dynamic objects on location estimation. To address these issues, we propose an anti-dynamics two-stage SLAM approach. Firstly, the potential motion regions of both prior and non-prior dynamic objects are extracted and pose estimates for dynamic discrimination are quickly obtained using optical flow tracking and model generation methods. Secondly, dynamic points in each frame are removed through dynamic judgment. For non-prior dynamic objects, we present a approach that uses super-pixel extraction and geometric clustering to determine the potential motion regions based on color and geometric information in the image. Evaluations on multiple low and high dynamic sequences in a public RGB-D dataset show that our proposed method outperforms state-of-the-art dynamic SLAM methods.
A Novel Underwater Image Enhancement and Improved Underwater Biological Detection Pipeline
May 20, 2022For aquaculture resource evaluation and ecological environment monitoring, automatic detection and identification of marine organisms is critical. However, due to the low quality of underwater images and the characteristics of underwater biological, a lack of abundant features may impede traditional hand-designed feature extraction approaches or CNN-based object detection algorithms, particularly in complex underwater environment. Therefore, the goal of this paper is to perform object detection in the underwater environment. This paper proposed a novel method for capturing feature information, which adds the convolutional block attention module (CBAM) to the YOLOv5 backbone. The interference of underwater creature characteristics on object characteristics is decreased, and the output of the backbone network to object information is enhanced. In addition, the self-adaptive global histogram stretching algorithm (SAGHS) is designed to eliminate the degradation problems such as low contrast and color loss caused by underwater environmental information to better restore image quality. Extensive experiments and comprehensive evaluation on the URPC2021 benchmark dataset demonstrate the effectiveness and adaptivity of our methods. Beyond that, this paper conducts an exhaustive analysis of the role of training data on performance.