 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Code to Road: A Vehicle-in-the-Loop and Digital Twin-Based Framework for Central Car Server Testing in Autonomous Driving
Mar 05, 2026Simulation is one of the most essential parts in the development stage of automotive software. However, purely virtual simulations often struggle to accurately capture all real-world factors due to limitations in modeling. To address this challenge, this work presents a test framework for automotive software on the centralized E/E architecture, which is a central car server in our case, based on Vehicle-in-the-Loop (ViL) and digital twin technology. The framework couples a physical test vehicle on a dynamometer test bench with its synchronized virtual counterpart in a simulation environment. Our approach provides a safe, reproducible, realistic, and cost-effective platform for validating autonomous driving algorithms with a centralized architecture. This test method eliminates the need to test individual physical ECUs and their communication protocols separately. In contrast to traditional ViL methods, the proposed framework runs the full autonomous driving software directly on the vehicle hardware after the simulation process, eliminating flashing and intermediate layers while enabling seamless virtual-physical integration and accurately reflecting centralized E/E behavior. In addition, incorporating mixed testing in both simulated and physical environments reduces the need for full hardware integration during the early stages of automotive development. Experimental case studies demonstrate the effectiveness of the framework in different test scenarios. These findings highlight the potential to reduce development and integration efforts for testing autonomous driving pipelines in the future.
PRAM-R: A Perception-Reasoning-Action-Memory Framework with LLM-Guided Modality Routing for Adaptive Autonomous Driving
Mar 04, 2026Multimodal perception enables robust autonomous driving but incurs unnecessary computational cost when all sensors remain active. This paper presents PRAM-R, a unified Perception-Reasoning-Action-Memory framework with LLM-Guided Modality Routing for adaptive autonomous driving. PRAM-R adopts an asynchronous dual-loop design: a fast reactive loop for perception and control, and a slow deliberative loop for reasoning-driven modality selection and memory updates. An LLM router selects and weights modalities using environmental context and sensor diagnostics, while a hierarchical memory module preserves temporal consistency and supports long-term adaptation. We conduct a two-stage evaluation: (1) synthetic stress tests for stability analysis and (2) real-world validation on the nuScenes dataset. Synthetic stress tests confirm 87.2% reduction in routing oscillations via hysteresis-based stabilization. Real-world validation on nuScenes shows 6.22% modality reduction with 20% memory recall while maintaining comparable trajectory accuracy to full-modality baselines in complex urban scenarios. Our work demonstrates that LLM-augmented architectures with hierarchical memory achieve efficient, adaptive multimodal perception in autonomous driving.
Autonomous Vehicle Lateral Control Using Deep Reinforcement Learning with MPC-PID Demonstration
Jun 04, 2025The controller is one of the most important modules in the autonomous driving pipeline, ensuring the vehicle reaches its desired position. In this work, a reinforcement learning based lateral control approach, despite the imperfections in the vehicle models due to measurement errors and simplifications, is presented. Our approach ensures comfortable, efficient, and robust control performance considering the interface between controlling and other modules. The controller consists of the conventional Model Predictive Control (MPC)-PID part as the basis and the demonstrator, and the Deep Reinforcement Learning (DRL) part which leverages the online information from the MPC-PID part. The controller's performance is evaluated in CARLA using the ground truth of the waypoints as inputs. Experimental results demonstrate the effectiveness of the controller when vehicle information is incomplete, and the training of DRL can be stabilized with the demonstration part. These findings highlight the potential to reduce development and integration efforts for autonomous driving pipelines in the future.
Bridging the Inter-Domain Gap through Low-Level Features for Cross-Modal Medical Image Segmentation
May 17, 2025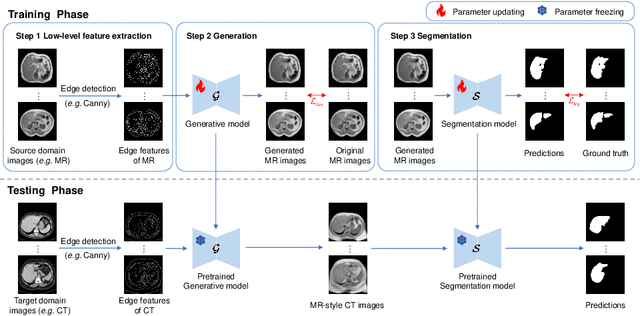
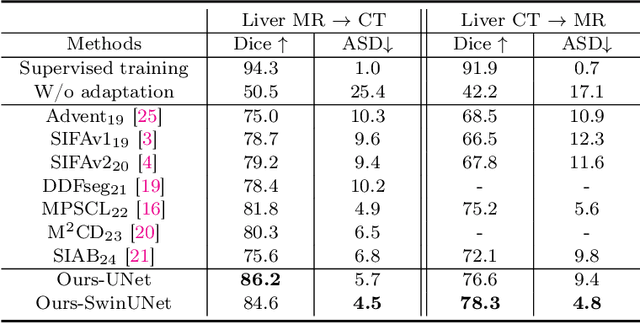
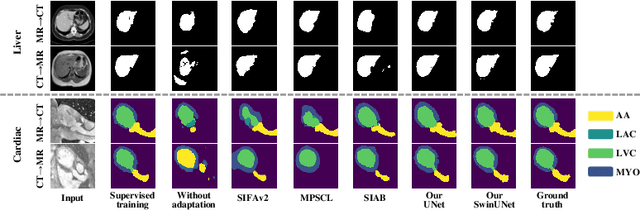
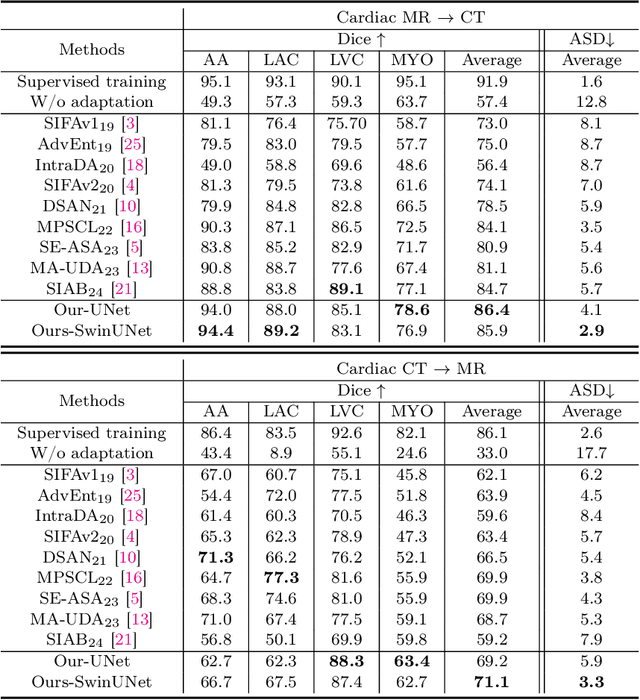
This paper addresses the task of cross-modal medical image segmentation by exploring unsupervised domain adaptation (UDA) approaches. We propose a model-agnostic UDA framework, LowBridge, which builds on a simple observation that cross-modal images share some similar low-level features (e.g., edges) as they are depicting the same structures. Specifically, we first train a generative model to recover the source images from their edge features, followed by training a segmentation model on the generated source images, separately. At test time, edge features from the target images are input to the pretrained generative model to generate source-style target domain images, which are then segmented using the pretrained segmentation network. Despite its simplicity, extensive experiments on various publicly available datasets demonstrate that \proposed achieves state-of-the-art performance, outperforming eleven existing UDA approaches under different settings. Notably, further ablation studies show that \proposed is agnostic to different types of generative and segmentation models, suggesting its potential to be seamlessly plugged with the most advanced models to achieve even more outstanding results in the future. The code is available at https://github.com/JoshuaLPF/LowBridge.
Deep Fourier-embedded Network for Bi-modal Salient Object Detection
Nov 27, 2024The rapid development of deep learning provides a significant improvement of salient object detection combining both RGB and thermal images. However, existing deep learning-based models suffer from two major shortcomings. First, the computation and memory demands of Transformer-based models with quadratic complexity are unbearable, especially in handling high-resolution bi-modal feature fusion. Second, even if learning converges to an ideal solution, there remains a frequency gap between the prediction and ground truth. Therefore, we propose a purely fast Fourier transform-based model, namely deep Fourier-embedded network (DFENet), for learning bi-modal information of RGB and thermal images. On one hand, fast Fourier transform efficiently fetches global dependencies with low complexity. Inspired by this, we design modal-coordinated perception attention to fuse the frequency gap between RGB and thermal modalities with multi-dimensional representation enhancement. To obtain reliable detailed information during decoding, we design the frequency-decomposed edge-aware module (FEM) to clarify object edges by deeply decomposing low-level features. Moreover, we equip proposed Fourier residual channel attention block in each decoder layer to prioritize high-frequency information while aligning channel global relationships. On the other hand, we propose co-focus frequency loss (CFL) to steer FEM towards minimizing the frequency gap. CFL dynamically weights hard frequencies during edge frequency reconstruction by cross-referencing the bi-modal edge information in the Fourier domain. This frequency-level refinement of edge features further contributes to the quality of the final pixel-level prediction. Extensive experiments on four bi-modal salient object detection benchmark datasets demonstrate our proposed DFENet outperforms twelve existing state-of-the-art models.
Efficient Fourier Filtering Network with Contrastive Learning for UAV-based Unaligned Bi-modal Salient Object Detection
Nov 06, 2024
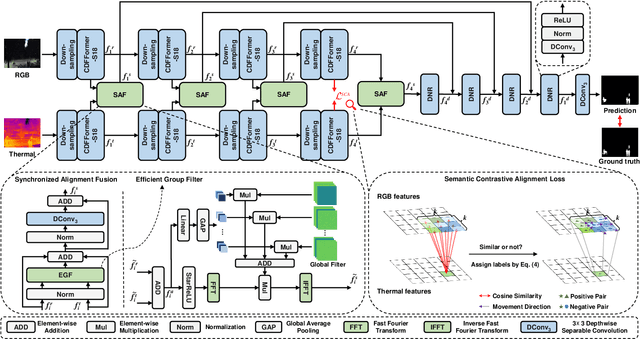
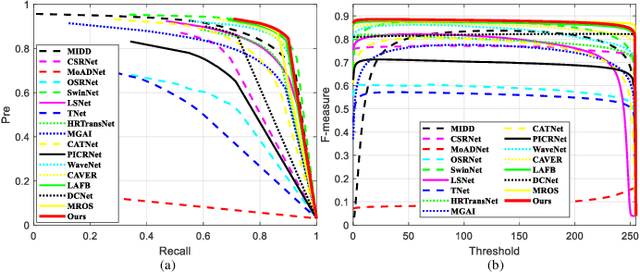

Unmanned aerial vehicle (UAV)-based bi-modal salient object detection (BSOD) aims to segment salient objects in a scene utilizing complementary cues in unaligned RGB and thermal image pairs. However, the high computational expense of existing UAV-based BSOD models limits their applicability to real-world UAV devices. To address this problem, we propose an efficient Fourier filter network with contrastive learning that achieves both real-time and accurate performance. Specifically, we first design a semantic contrastive alignment loss to align the two modalities at the semantic level, which facilitates mutual refinement in a parameter-free way. Second, inspired by the fast Fourier transform that obtains global relevance in linear complexity, we propose synchronized alignment fusion, which aligns and fuses bi-modal features in the channel and spatial dimensions by a hierarchical filtering mechanism. Our proposed model, AlignSal, reduces the number of parameters by 70.0%, decreases the floating point operations by 49.4%, and increases the inference speed by 152.5% compared to the cutting-edge BSOD model (i.e., MROS). Extensive experiments on the UAV RGB-T 2400 and three weakly aligned datasets demonstrate that AlignSal achieves both real-time inference speed and better performance and generalizability compared to sixteen state-of-the-art BSOD models across most evaluation metrics. In addition, our ablation studies further verify AlignSal's potential in boosting the performance of existing aligned BSOD models on UAV-based unaligned data. The code is available at: https://github.com/JoshuaLPF/AlignSal.
MGS-SLAM: Monocular Sparse Tracking and Gaussian Mapping with Depth Smooth Regularization
May 10, 2024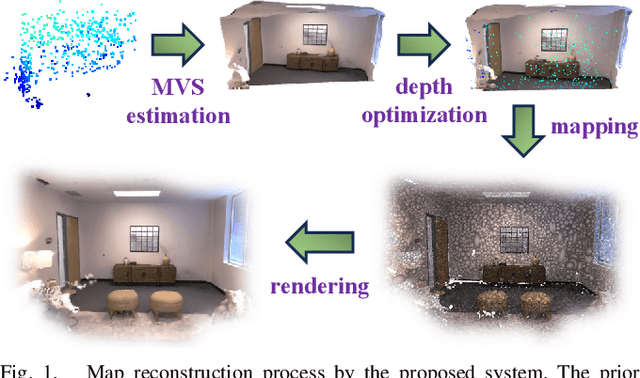
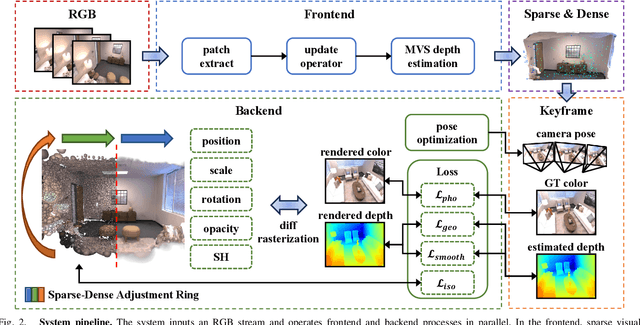
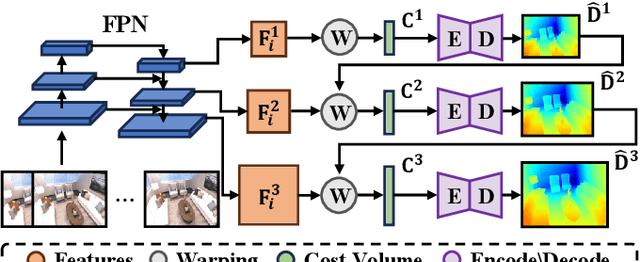
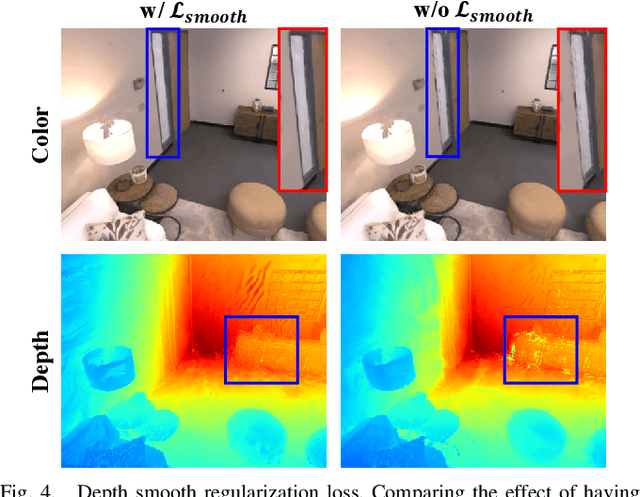
This letter introduces a novel framework for dense Visual Simultaneous Localization and Mapping (VSLAM) based on Gaussian Splatting. Recently Gaussian Splatting-based SLAM has yielded promising results, but rely on RGB-D input and is weak in tracking. To address these limitations, we uniquely integrates advanced sparse visual odometry with a dense Gaussian Splatting scene representation for the first time, thereby eliminating the dependency on depth maps typical of Gaussian Splatting-based SLAM systems and enhancing tracking robustness. Here, the sparse visual odometry tracks camera poses in RGB stream, while Gaussian Splatting handles map reconstruction. These components are interconnected through a Multi-View Stereo (MVS) depth estimation network. And we propose a depth smooth loss to reduce the negative effect of estimated depth maps. Furthermore, the consistency in scale between the sparse visual odometry and the dense Gaussian map is preserved by Sparse-Dense Adjustment Ring (SDAR). We have evaluated our system across various synthetic and real-world datasets. The accuracy of our pose estimation surpasses existing methods and achieves state-of-the-art performance. Additionally, it outperforms previous monocular methods in terms of novel view synthesis fidelity, matching the results of neural SLAM systems that utilize RGB-D input.
A geometry-aware deep network for depth estimation in monocular endoscopy
Apr 20, 2023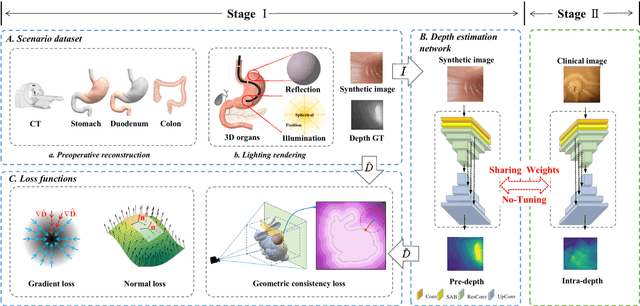
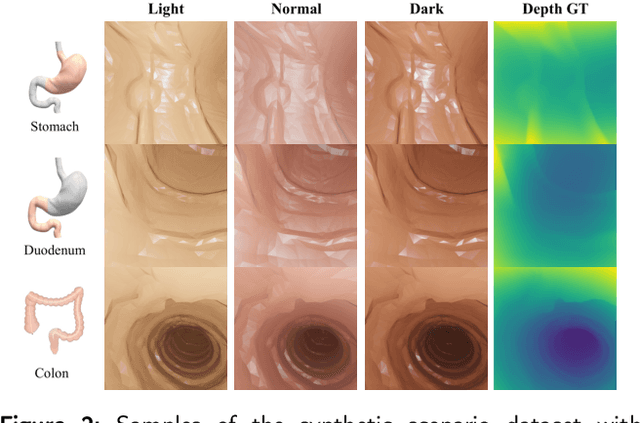
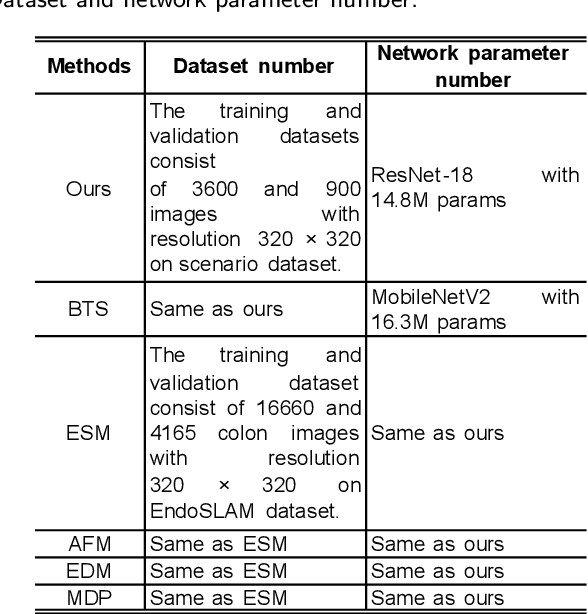
Monocular depth estimation is critical for endoscopists to perform spatial perception and 3D navigation of surgical sites. However, most of the existing methods ignore the important geometric structural consistency, which inevitably leads to performance degradation and distortion of 3D reconstruction. To address this issue, we introduce a gradient loss to penalize edge fluctuations ambiguous around stepped edge structures and a normal loss to explicitly express the sensitivity to frequently small structures, and propose a geometric consistency loss to spreads the spatial information across the sample grids to constrain the global geometric anatomy structures. In addition, we develop a synthetic RGB-Depth dataset that captures the anatomical structures under reflections and illumination variations. The proposed method is extensively validated across different datasets and clinical images and achieves mean RMSE values of 0.066 (stomach), 0.029 (small intestine), and 0.139 (colon) on the EndoSLAM dataset. The generalizability of the proposed method achieves mean RMSE values of 12.604 (T1-L1), 9.930 (T2-L2), and 13.893 (T3-L3) on the ColonDepth dataset. The experimental results show that our method exceeds previous state-of-the-art competitors and generates more consistent depth maps and reasonable anatomical structures. The quality of intraoperative 3D structure perception from endoscopic videos of the proposed method meets the accuracy requirements of video-CT registration algorithms for endoscopic navigation. The dataset and the source code will be available at https://github.com/YYM-SIA/LINGMI-MR.
Amos-SLAM: An Anti-Dynamics Two-stage SLAM Approach
Feb 23, 2023



The traditional Simultaneous Localization And Mapping (SLAM) systems rely on the assumption of a static environment and fail to accurately estimate the system's location when dynamic objects are present in the background. While learning-based dynamic SLAM systems have difficulties in handling unknown moving objects, geometry-based methods have limited success in addressing the residual effects of unidentified dynamic objects on location estimation. To address these issues, we propose an anti-dynamics two-stage SLAM approach. Firstly, the potential motion regions of both prior and non-prior dynamic objects are extracted and pose estimates for dynamic discrimination are quickly obtained using optical flow tracking and model generation methods. Secondly, dynamic points in each frame are removed through dynamic judgment. For non-prior dynamic objects, we present a approach that uses super-pixel extraction and geometric clustering to determine the potential motion regions based on color and geometric information in the image. Evaluations on multiple low and high dynamic sequences in a public RGB-D dataset show that our proposed method outperforms state-of-the-art dynamic SLAM methods.
A Novel Underwater Image Enhancement and Improved Underwater Biological Detection Pipeline
May 20, 2022For aquaculture resource evaluation and ecological environment monitoring, automatic detection and identification of marine organisms is critical. However, due to the low quality of underwater images and the characteristics of underwater biological, a lack of abundant features may impede traditional hand-designed feature extraction approaches or CNN-based object detection algorithms, particularly in complex underwater environment. Therefore, the goal of this paper is to perform object detection in the underwater environment. This paper proposed a novel method for capturing feature information, which adds the convolutional block attention module (CBAM) to the YOLOv5 backbone. The interference of underwater creature characteristics on object characteristics is decreased, and the output of the backbone network to object information is enhanced. In addition, the self-adaptive global histogram stretching algorithm (SAGHS) is designed to eliminate the degradation problems such as low contrast and color loss caused by underwater environmental information to better restore image quality. Extensive experiments and comprehensive evaluation on the URPC2021 benchmark dataset demonstrate the effectiveness and adaptivity of our methods. Beyond that, this paper conducts an exhaustive analysis of the role of training data on performance.