 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUrbanGS: A Scalable and Efficient Architecture for Geometrically Accurate Large-Scene Reconstruction
Feb 02, 2026While 3D Gaussian Splatting (3DGS) enables high-quality, real-time rendering for bounded scenes, its extension to large-scale urban environments gives rise to critical challenges in terms of geometric consistency, memory efficiency, and computational scalability. To address these issues, we present UrbanGS, a scalable reconstruction framework that effectively tackles these challenges for city-scale applications. First, we propose a Depth-Consistent D-Normal Regularization module. Unlike existing approaches that rely solely on monocular normal estimators, which can effectively update rotation parameters yet struggle to update position parameters, our method integrates D-Normal constraints with external depth supervision. This allows for comprehensive updates of all geometric parameters. By further incorporating an adaptive confidence weighting mechanism based on gradient consistency and inverse depth deviation, our approach significantly enhances multi-view depth alignment and geometric coherence, which effectively resolves the issue of geometric accuracy in complex large-scale scenes. To improve scalability, we introduce a Spatially Adaptive Gaussian Pruning (SAGP) strategy, which dynamically adjusts Gaussian density based on local geometric complexity and visibility to reduce redundancy. Additionally, a unified partitioning and view assignment scheme is designed to eliminate boundary artifacts and optimize computational load. Extensive experiments on multiple urban datasets demonstrate that UrbanGS achieves superior performance in rendering quality, geometric accuracy, and memory efficiency, providing a systematic solution for high-fidelity large-scale scene reconstruction.
HRGS: Hierarchical Gaussian Splatting for Memory-Efficient High-Resolution 3D Reconstruction
Jun 17, 2025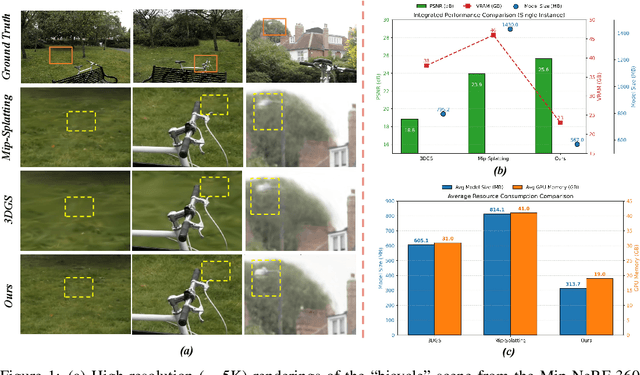

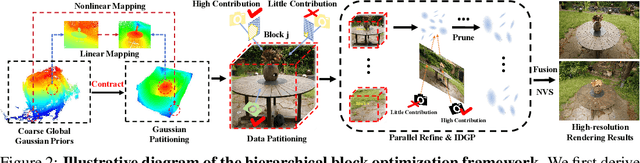

3D Gaussian Splatting (3DGS) has made significant strides in real-time 3D scene reconstruction, but faces memory scalability issues in high-resolution scenarios. To address this, we propose Hierarchical Gaussian Splatting (HRGS), a memory-efficient framework with hierarchical block-level optimization. First, we generate a global, coarse Gaussian representation from low-resolution data. Then, we partition the scene into multiple blocks, refining each block with high-resolution data. The partitioning involves two steps: Gaussian partitioning, where irregular scenes are normalized into a bounded cubic space with a uniform grid for task distribution, and training data partitioning, where only relevant observations are retained for each block. By guiding block refinement with the coarse Gaussian prior, we ensure seamless Gaussian fusion across adjacent blocks. To reduce computational demands, we introduce Importance-Driven Gaussian Pruning (IDGP), which computes importance scores for each Gaussian and removes those with minimal contribution, speeding up convergence and reducing memory usage. Additionally, we incorporate normal priors from a pretrained model to enhance surface reconstruction quality. Our method enables high-quality, high-resolution 3D scene reconstruction even under memory constraints. Extensive experiments on three benchmarks show that HRGS achieves state-of-the-art performance in high-resolution novel view synthesis (NVS) and surface reconstruction tasks.
Synthetic-to-Real Self-supervised Robust Depth Estimation via Learning with Motion and Structure Priors
Mar 26, 2025Self-supervised depth estimation from monocular cameras in diverse outdoor conditions, such as daytime, rain, and nighttime, is challenging due to the difficulty of learning universal representations and the severe lack of labeled real-world adverse data. Previous methods either rely on synthetic inputs and pseudo-depth labels or directly apply daytime strategies to adverse conditions, resulting in suboptimal results. In this paper, we present the first synthetic-to-real robust depth estimation framework, incorporating motion and structure priors to capture real-world knowledge effectively. In the synthetic adaptation, we transfer motion-structure knowledge inside cost volumes for better robust representation, using a frozen daytime model to train a depth estimator in synthetic adverse conditions. In the innovative real adaptation, which targets to fix synthetic-real gaps, models trained earlier identify the weather-insensitive regions with a designed consistency-reweighting strategy to emphasize valid pseudo-labels. We introduce a new regularization by gathering explicit depth distributions to constrain the model when facing real-world data. Experiments show that our method outperforms the state-of-the-art across diverse conditions in multi-frame and single-frame evaluations. We achieve improvements of 7.5% and 4.3% in AbsRel and RMSE on average for nuScenes and Robotcar datasets (daytime, nighttime, rain). In zero-shot evaluation of DrivingStereo (rain, fog), our method generalizes better than the previous ones.
Digging into contrastive learning for robust depth estimation with diffusion models
Apr 17, 2024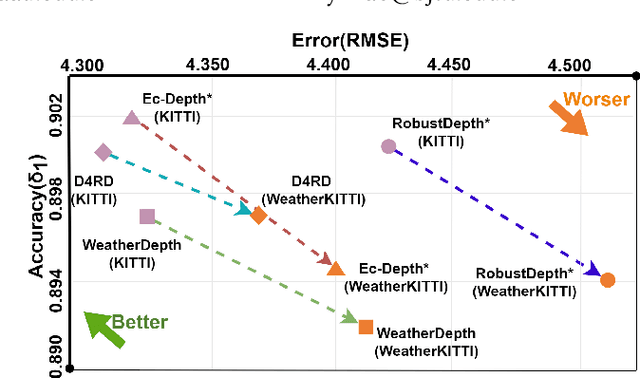
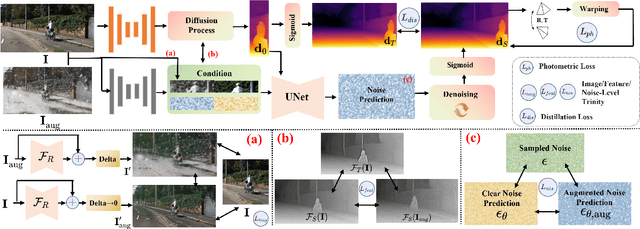
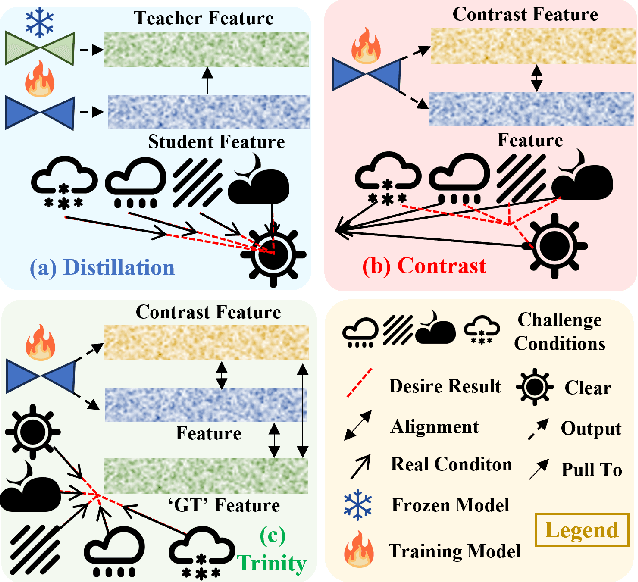

Recently, diffusion-based depth estimation methods have drawn widespread attention due to their elegant denoising patterns and promising performance. However, they are typically unreliable under adverse conditions prevalent in real-world scenarios, such as rainy, snowy, etc. In this paper, we propose a novel robust depth estimation method called D4RD, featuring a custom contrastive learning mode tailored for diffusion models to mitigate performance degradation in complex environments. Concretely, we integrate the strength of knowledge distillation into contrastive learning, building the `trinity' contrastive scheme. This scheme utilizes the sampled noise of the forward diffusion process as a natural reference, guiding the predicted noise in diverse scenes toward a more stable and precise optimum. Moreover, we extend noise-level trinity to encompass more generic feature and image levels, establishing a multi-level contrast to distribute the burden of robust perception across the overall network. Before addressing complex scenarios, we enhance the stability of the baseline diffusion model with three straightforward yet effective improvements, which facilitate convergence and remove depth outliers. Extensive experiments demonstrate that D4RD surpasses existing state-of-the-art solutions on synthetic corruption datasets and real-world weather conditions. The code for D4RD will be made available for further exploration and adoption.
$\mathrm{F^2Depth}$: Self-supervised Indoor Monocular Depth Estimation via Optical Flow Consistency and Feature Map Synthesis
Mar 27, 2024Self-supervised monocular depth estimation methods have been increasingly given much attention due to the benefit of not requiring large, labelled datasets. Such self-supervised methods require high-quality salient features and consequently suffer from severe performance drop for indoor scenes, where low-textured regions dominant in the scenes are almost indiscriminative. To address the issue, we propose a self-supervised indoor monocular depth estimation framework called $\mathrm{F^2Depth}$. A self-supervised optical flow estimation network is introduced to supervise depth learning. To improve optical flow estimation performance in low-textured areas, only some patches of points with more discriminative features are adopted for finetuning based on our well-designed patch-based photometric loss. The finetuned optical flow estimation network generates high-accuracy optical flow as a supervisory signal for depth estimation. Correspondingly, an optical flow consistency loss is designed. Multi-scale feature maps produced by finetuned optical flow estimation network perform warping to compute feature map synthesis loss as another supervisory signal for depth learning. Experimental results on the NYU Depth V2 dataset demonstrate the effectiveness of the framework and our proposed losses. To evaluate the generalization ability of our $\mathrm{F^2Depth}$, we collect a Campus Indoor depth dataset composed of approximately 1500 points selected from 99 images in 18 scenes. Zero-shot generalization experiments on 7-Scenes dataset and Campus Indoor achieve $\delta_1$ accuracy of 75.8% and 76.0% respectively. The accuracy results show that our model can generalize well to monocular images captured in unknown indoor scenes.
NDDepth: Normal-Distance Assisted Monocular Depth Estimation and Completion
Nov 13, 2023Over the past few years, monocular depth estimation and completion have been paid more and more attention from the computer vision community because of their widespread applications. In this paper, we introduce novel physics (geometry)-driven deep learning frameworks for these two tasks by assuming that 3D scenes are constituted with piece-wise planes. Instead of directly estimating the depth map or completing the sparse depth map, we propose to estimate the surface normal and plane-to-origin distance maps or complete the sparse surface normal and distance maps as intermediate outputs. To this end, we develop a normal-distance head that outputs pixel-level surface normal and distance. Meanwhile, the surface normal and distance maps are regularized by a developed plane-aware consistency constraint, which are then transformed into depth maps. Furthermore, we integrate an additional depth head to strengthen the robustness of the proposed frameworks. Extensive experiments on the NYU-Depth-v2, KITTI and SUN RGB-D datasets demonstrate that our method exceeds in performance prior state-of-the-art monocular depth estimation and completion competitors. The source code will be available at https://github.com/ShuweiShao/NDDepth.
MonoDiffusion: Self-Supervised Monocular Depth Estimation Using Diffusion Model
Nov 13, 2023Over the past few years, self-supervised monocular depth estimation that does not depend on ground-truth during the training phase has received widespread attention. Most efforts focus on designing different types of network architectures and loss functions or handling edge cases, e.g., occlusion and dynamic objects. In this work, we introduce a novel self-supervised depth estimation framework, dubbed MonoDiffusion, by formulating it as an iterative denoising process. Because the depth ground-truth is unavailable in the training phase, we develop a pseudo ground-truth diffusion process to assist the diffusion in MonoDiffusion. The pseudo ground-truth diffusion gradually adds noise to the depth map generated by a pre-trained teacher model. Moreover,the teacher model allows applying a distillation loss to guide the denoised depth. Further, we develop a masked visual condition mechanism to enhance the denoising ability of model. Extensive experiments are conducted on the KITTI and Make3D datasets and the proposed MonoDiffusion outperforms prior state-of-the-art competitors. The source code will be available at https://github.com/ShuweiShao/MonoDiffusion.
IEBins: Iterative Elastic Bins for Monocular Depth Estimation
Sep 25, 2023Monocular depth estimation (MDE) is a fundamental topic of geometric computer vision and a core technique for many downstream applications. Recently, several methods reframe the MDE as a classification-regression problem where a linear combination of probabilistic distribution and bin centers is used to predict depth. In this paper, we propose a novel concept of iterative elastic bins (IEBins) for the classification-regression-based MDE. The proposed IEBins aims to search for high-quality depth by progressively optimizing the search range, which involves multiple stages and each stage performs a finer-grained depth search in the target bin on top of its previous stage. To alleviate the possible error accumulation during the iterative process, we utilize a novel elastic target bin to replace the original target bin, the width of which is adjusted elastically based on the depth uncertainty. Furthermore, we develop a dedicated framework composed of a feature extractor and an iterative optimizer that has powerful temporal context modeling capabilities benefiting from the GRU-based architecture. Extensive experiments on the KITTI, NYU-Depth-v2 and SUN RGB-D datasets demonstrate that the proposed method surpasses prior state-of-the-art competitors. The source code is publicly available at https://github.com/ShuweiShao/IEBins.
NDDepth: Normal-Distance Assisted Monocular Depth Estimation
Sep 24, 2023Monocular depth estimation has drawn widespread attention from the vision community due to its broad applications. In this paper, we propose a novel physics (geometry)-driven deep learning framework for monocular depth estimation by assuming that 3D scenes are constituted by piece-wise planes. Particularly, we introduce a new normal-distance head that outputs pixel-level surface normal and plane-to-origin distance for deriving depth at each position. Meanwhile, the normal and distance are regularized by a developed plane-aware consistency constraint. We further integrate an additional depth head to improve the robustness of the proposed framework. To fully exploit the strengths of these two heads, we develop an effective contrastive iterative refinement module that refines depth in a complementary manner according to the depth uncertainty. Extensive experiments indicate that the proposed method exceeds previous state-of-the-art competitors on the NYU-Depth-v2, KITTI and SUN RGB-D datasets. Notably, it ranks 1st among all submissions on the KITTI depth prediction online benchmark at the submission time.
A geometry-aware deep network for depth estimation in monocular endoscopy
Apr 20, 2023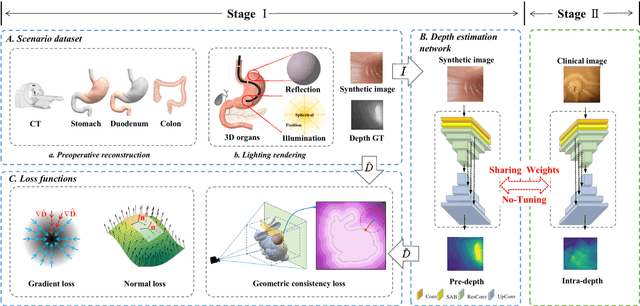
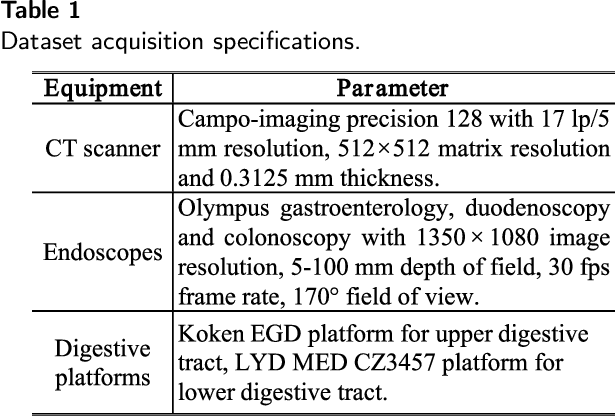
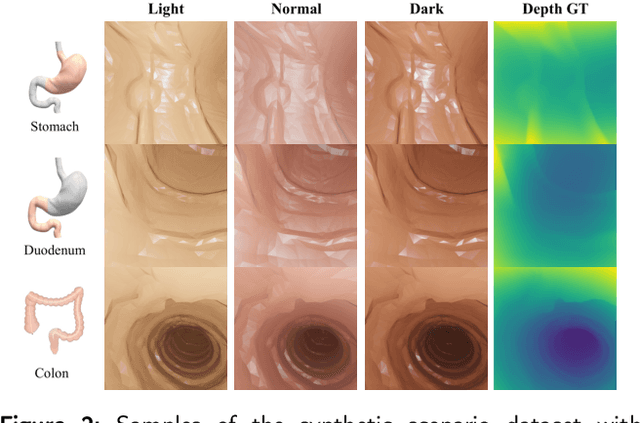
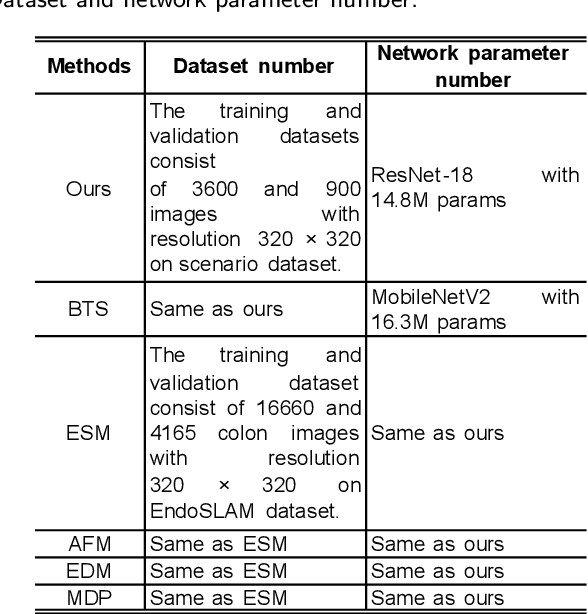
Monocular depth estimation is critical for endoscopists to perform spatial perception and 3D navigation of surgical sites. However, most of the existing methods ignore the important geometric structural consistency, which inevitably leads to performance degradation and distortion of 3D reconstruction. To address this issue, we introduce a gradient loss to penalize edge fluctuations ambiguous around stepped edge structures and a normal loss to explicitly express the sensitivity to frequently small structures, and propose a geometric consistency loss to spreads the spatial information across the sample grids to constrain the global geometric anatomy structures. In addition, we develop a synthetic RGB-Depth dataset that captures the anatomical structures under reflections and illumination variations. The proposed method is extensively validated across different datasets and clinical images and achieves mean RMSE values of 0.066 (stomach), 0.029 (small intestine), and 0.139 (colon) on the EndoSLAM dataset. The generalizability of the proposed method achieves mean RMSE values of 12.604 (T1-L1), 9.930 (T2-L2), and 13.893 (T3-L3) on the ColonDepth dataset. The experimental results show that our method exceeds previous state-of-the-art competitors and generates more consistent depth maps and reasonable anatomical structures. The quality of intraoperative 3D structure perception from endoscopic videos of the proposed method meets the accuracy requirements of video-CT registration algorithms for endoscopic navigation. The dataset and the source code will be available at https://github.com/YYM-SIA/LINGMI-MR.