 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeighted Combination and Singular Spectrum Analysis Based Remote Photoplethysmography Pulse Extraction in Low-light Environments
Mar 04, 2025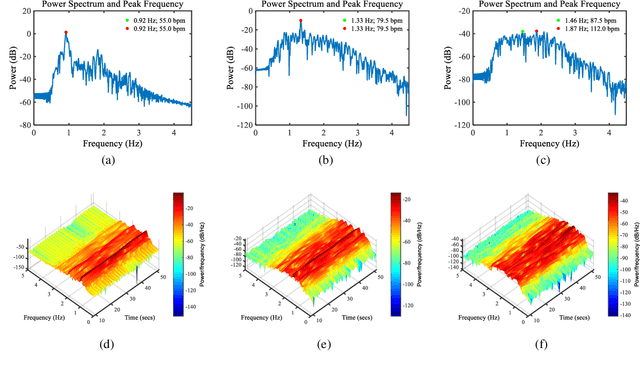
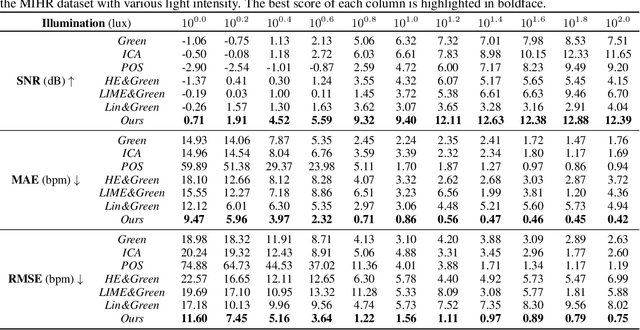
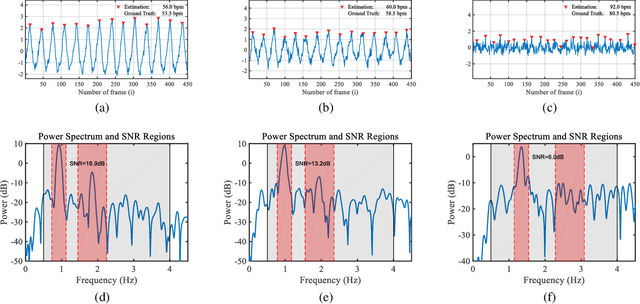
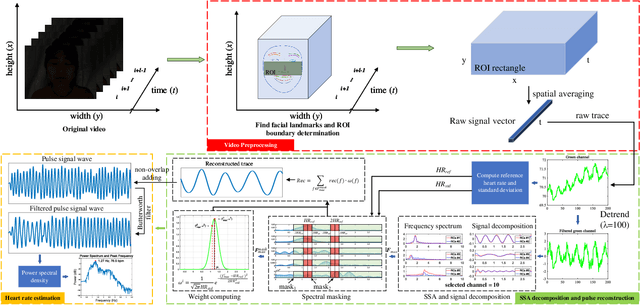
Camera-based vital signs monitoring in recent years has attracted more and more researchers and the results are promising. However, a few research works focus on heart rate extraction under extremely low illumination environments. In this paper, we propose a novel framework for remote heart rate estimation under low-light conditions. This method uses singular spectrum analysis (SSA) to decompose the filtered signal into several reconstructed components. A spectral masking algorithm is utilized to refine the preliminary candidate components on the basis of a reference heart rate. The contributive components are fused into the final pulse signal. To evaluate the performance of our framework in low-light conditions, the proposed approach is tested on a large-scale multi-illumination HR dataset (named MIHR). The test results verify that the proposed method has stronger robustness to low illumination than state-of-the-art methods, effectively improving the signal-to-noise ratio and heart rate estimation precision. We further perform experiments on the PUlse RatE detection (PURE) dataset which is recorded under normal light conditions to demonstrate the generalization of our method. The experiment results show that our method can stably detect pulse rate and achieve comparative results. The proposed method pioneers a new solution to the remote heart rate estimation in low-light conditions.
LP-ICP: General Localizability-Aware Point Cloud Registration for Robust Localization in Extreme Unstructured Environments
Jan 05, 2025



The Iterative Closest Point (ICP) algorithm is a crucial component of LiDAR-based SLAM algorithms. However, its performance can be negatively affected in unstructured environments that lack features and geometric structures, leading to low accuracy and poor robustness in localization and mapping. It is known that degeneracy caused by the lack of geometric constraints can lead to errors in 6-DOF pose estimation along ill-conditioned directions. Therefore, there is a need for a broader and more fine-grained degeneracy detection and handling method. This paper proposes a new point cloud registration framework, LP-ICP, that combines point-to-line and point-to-plane distance metrics in the ICP algorithm, with localizability detection and handling. LP-ICP consists of a localizability detection module and an optimization module. The localizability detection module performs localizability analysis by utilizing the correspondences between edge points (with low local smoothness) to lines and planar points (with high local smoothness) to planes between the scan and the map. The localizability contribution of individual correspondence constraints can be applied to a broader range. The optimization module adds additional soft and hard constraints to the optimization equations based on the localizability category. This allows the pose to be constrained along ill-conditioned directions, with updates either tending towards the constraint value or leaving the initial estimate unchanged. This improves accuracy and reduces fluctuations. The proposed method is extensively evaluated through experiments on both simulation and real-world datasets, demonstrating higher or comparable accuracy than the state-of-the-art methods. The dataset and code of this paper will also be open-sourced at https://github.com/xuqingyuan2000/LP-ICP.
Neural Augmentation Based Panoramic High Dynamic Range Stitching
Sep 07, 2024Due to saturated regions of inputting low dynamic range (LDR) images and large intensity changes among the LDR images caused by different exposures, it is challenging to produce an information enriched panoramic LDR image without visual artifacts for a high dynamic range (HDR) scene through stitching multiple geometrically synchronized LDR images with different exposures and pairwise overlapping fields of views (OFOVs). Fortunately, the stitching of such images is innately a perfect scenario for the fusion of a physics-driven approach and a data-driven approach due to their OFOVs. Based on this new insight, a novel neural augmentation based panoramic HDR stitching algorithm is proposed in this paper. The physics-driven approach is built up using the OFOVs. Different exposed images of each view are initially generated by using the physics-driven approach, are then refined by a data-driven approach, and are finally used to produce panoramic LDR images with different exposures. All the panoramic LDR images with different exposures are combined together via a multi-scale exposure fusion algorithm to produce the final panoramic LDR image. Experimental results demonstrate the proposed algorithm outperforms existing panoramic stitching algorithms.
Domain Generalization for Zero-calibration BCIs with Knowledge Distillation-based Phase Invariant Feature Extraction
May 18, 2024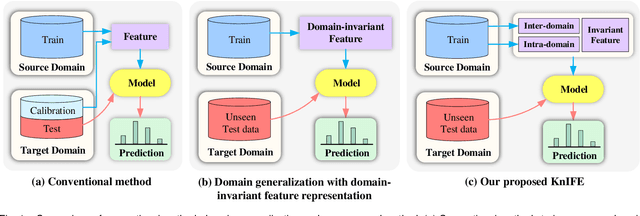
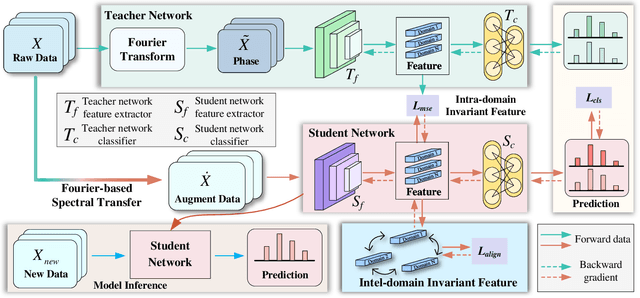
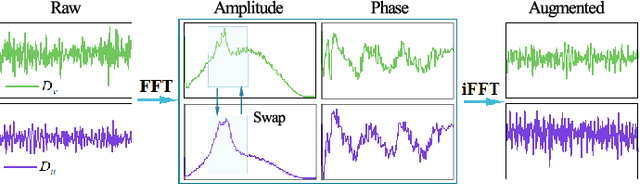
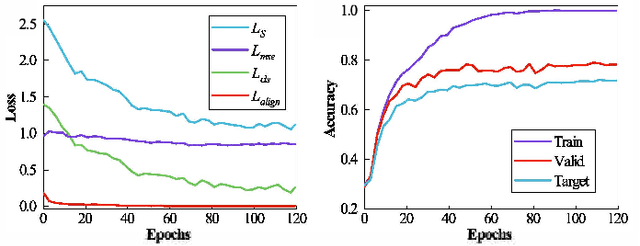
The distribution shift of electroencephalography (EEG) data causes poor generalization of braincomputer interfaces (BCIs) in unseen domains. Some methods try to tackle this challenge by collecting a portion of user data for calibration. However, it is time-consuming, mentally fatiguing, and user-unfriendly. To achieve zerocalibration BCIs, most studies employ domain generalization (DG) techniques to learn invariant features across different domains in the training set. However, they fail to fully explore invariant features within the same domain, leading to limited performance. In this paper, we present an novel method to learn domain-invariant features from both interdomain and intra-domain perspectives. For intra-domain invariant features, we propose a knowledge distillation framework to extract EEG phase-invariant features within one domain. As for inter-domain invariant features, correlation alignment is used to bridge distribution gaps across multiple domains. Experimental results on three public datasets validate the effectiveness of our method, showcasing stateof-the-art performance. To the best of our knowledge, this is the first domain generalization study that exploit Fourier phase information as an intra-domain invariant feature to facilitate EEG generalization. More importantly, the zerocalibration BCI based on inter- and intra-domain invariant features has significant potential to advance the practical applications of BCIs in real world.
NDDepth: Normal-Distance Assisted Monocular Depth Estimation and Completion
Nov 13, 2023Over the past few years, monocular depth estimation and completion have been paid more and more attention from the computer vision community because of their widespread applications. In this paper, we introduce novel physics (geometry)-driven deep learning frameworks for these two tasks by assuming that 3D scenes are constituted with piece-wise planes. Instead of directly estimating the depth map or completing the sparse depth map, we propose to estimate the surface normal and plane-to-origin distance maps or complete the sparse surface normal and distance maps as intermediate outputs. To this end, we develop a normal-distance head that outputs pixel-level surface normal and distance. Meanwhile, the surface normal and distance maps are regularized by a developed plane-aware consistency constraint, which are then transformed into depth maps. Furthermore, we integrate an additional depth head to strengthen the robustness of the proposed frameworks. Extensive experiments on the NYU-Depth-v2, KITTI and SUN RGB-D datasets demonstrate that our method exceeds in performance prior state-of-the-art monocular depth estimation and completion competitors. The source code will be available at https://github.com/ShuweiShao/NDDepth.
MonoDiffusion: Self-Supervised Monocular Depth Estimation Using Diffusion Model
Nov 13, 2023Over the past few years, self-supervised monocular depth estimation that does not depend on ground-truth during the training phase has received widespread attention. Most efforts focus on designing different types of network architectures and loss functions or handling edge cases, e.g., occlusion and dynamic objects. In this work, we introduce a novel self-supervised depth estimation framework, dubbed MonoDiffusion, by formulating it as an iterative denoising process. Because the depth ground-truth is unavailable in the training phase, we develop a pseudo ground-truth diffusion process to assist the diffusion in MonoDiffusion. The pseudo ground-truth diffusion gradually adds noise to the depth map generated by a pre-trained teacher model. Moreover,the teacher model allows applying a distillation loss to guide the denoised depth. Further, we develop a masked visual condition mechanism to enhance the denoising ability of model. Extensive experiments are conducted on the KITTI and Make3D datasets and the proposed MonoDiffusion outperforms prior state-of-the-art competitors. The source code will be available at https://github.com/ShuweiShao/MonoDiffusion.
IEBins: Iterative Elastic Bins for Monocular Depth Estimation
Sep 25, 2023Monocular depth estimation (MDE) is a fundamental topic of geometric computer vision and a core technique for many downstream applications. Recently, several methods reframe the MDE as a classification-regression problem where a linear combination of probabilistic distribution and bin centers is used to predict depth. In this paper, we propose a novel concept of iterative elastic bins (IEBins) for the classification-regression-based MDE. The proposed IEBins aims to search for high-quality depth by progressively optimizing the search range, which involves multiple stages and each stage performs a finer-grained depth search in the target bin on top of its previous stage. To alleviate the possible error accumulation during the iterative process, we utilize a novel elastic target bin to replace the original target bin, the width of which is adjusted elastically based on the depth uncertainty. Furthermore, we develop a dedicated framework composed of a feature extractor and an iterative optimizer that has powerful temporal context modeling capabilities benefiting from the GRU-based architecture. Extensive experiments on the KITTI, NYU-Depth-v2 and SUN RGB-D datasets demonstrate that the proposed method surpasses prior state-of-the-art competitors. The source code is publicly available at https://github.com/ShuweiShao/IEBins.
NDDepth: Normal-Distance Assisted Monocular Depth Estimation
Sep 24, 2023Monocular depth estimation has drawn widespread attention from the vision community due to its broad applications. In this paper, we propose a novel physics (geometry)-driven deep learning framework for monocular depth estimation by assuming that 3D scenes are constituted by piece-wise planes. Particularly, we introduce a new normal-distance head that outputs pixel-level surface normal and plane-to-origin distance for deriving depth at each position. Meanwhile, the normal and distance are regularized by a developed plane-aware consistency constraint. We further integrate an additional depth head to improve the robustness of the proposed framework. To fully exploit the strengths of these two heads, we develop an effective contrastive iterative refinement module that refines depth in a complementary manner according to the depth uncertainty. Extensive experiments indicate that the proposed method exceeds previous state-of-the-art competitors on the NYU-Depth-v2, KITTI and SUN RGB-D datasets. Notably, it ranks 1st among all submissions on the KITTI depth prediction online benchmark at the submission time.
Online Unsupervised Video Object Segmentation via Contrastive Motion Clustering
Jun 21, 2023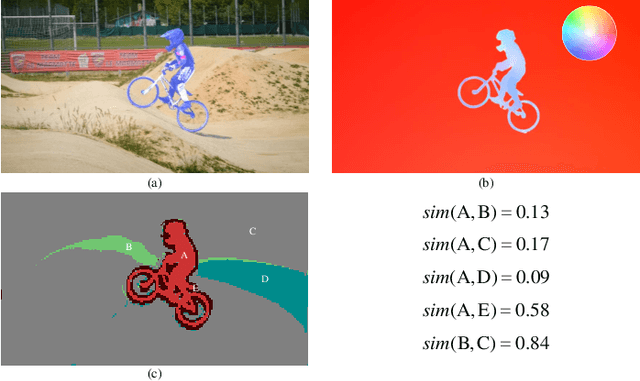
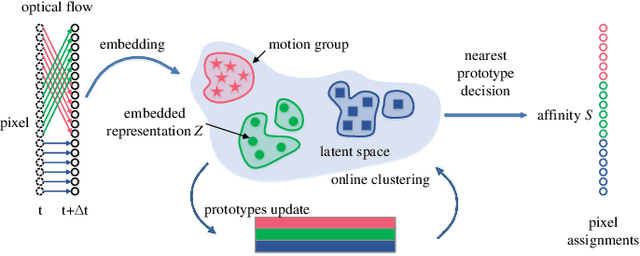
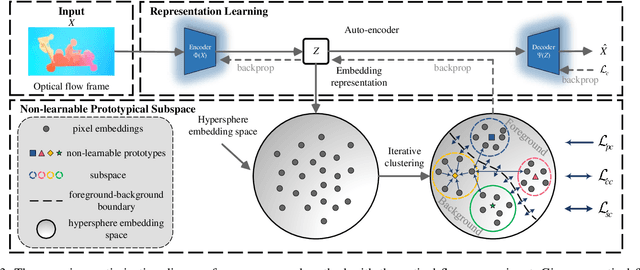
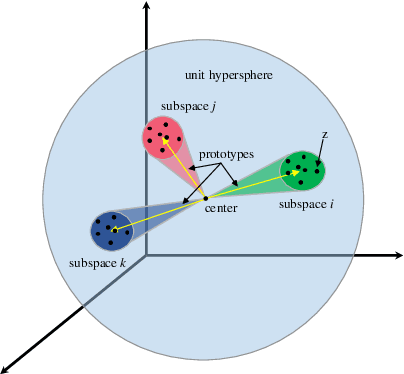
Online unsupervised video object segmentation (UVOS) uses the previous frames as its input to automatically separate the primary object(s) from a streaming video without using any further manual annotation. A major challenge is that the model has no access to the future and must rely solely on the history, i.e., the segmentation mask is predicted from the current frame as soon as it is captured. In this work, a novel contrastive motion clustering algorithm with an optical flow as its input is proposed for the online UVOS by exploiting the common fate principle that visual elements tend to be perceived as a group if they possess the same motion pattern. We build a simple and effective auto-encoder to iteratively summarize non-learnable prototypical bases for the motion pattern, while the bases in turn help learn the representation of the embedding network. Further, a contrastive learning strategy based on a boundary prior is developed to improve foreground and background feature discrimination in the representation learning stage. The proposed algorithm can be optimized on arbitrarily-scale data i.e., frame, clip, dataset) and performed in an online fashion. Experiments on $\textit{DAVIS}_{\textit{16}}$, $\textit{FBMS}$, and $\textit{SegTrackV2}$ datasets show that the accuracy of our method surpasses the previous state-of-the-art (SoTA) online UVOS method by a margin of 0.8%, 2.9%, and 1.1%, respectively. Furthermore, by using an online deep subspace clustering to tackle the motion grouping, our method is able to achieve higher accuracy at $3\times$ faster inference time compared to SoTA online UVOS method, and making a good trade-off between effectiveness and efficiency.
ALIKED: A Lighter Keypoint and Descriptor Extraction Network via Deformable Transformation
Apr 16, 2023Image keypoints and descriptors play a crucial role in many visual measurement tasks. In recent years, deep neural networks have been widely used to improve the performance of keypoint and descriptor extraction. However, the conventional convolution operations do not provide the geometric invariance required for the descriptor. To address this issue, we propose the Sparse Deformable Descriptor Head (SDDH), which learns the deformable positions of supporting features for each keypoint and constructs deformable descriptors. Furthermore, SDDH extracts descriptors at sparse keypoints instead of a dense descriptor map, which enables efficient extraction of descriptors with strong expressiveness. In addition, we relax the neural reprojection error (NRE) loss from dense to sparse to train the extracted sparse descriptors. Experimental results show that the proposed network is both efficient and powerful in various visual measurement tasks, including image matching, 3D reconstruction, and visual relocalization.