 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLP-ICP: General Localizability-Aware Point Cloud Registration for Robust Localization in Extreme Unstructured Environments
Jan 05, 2025



The Iterative Closest Point (ICP) algorithm is a crucial component of LiDAR-based SLAM algorithms. However, its performance can be negatively affected in unstructured environments that lack features and geometric structures, leading to low accuracy and poor robustness in localization and mapping. It is known that degeneracy caused by the lack of geometric constraints can lead to errors in 6-DOF pose estimation along ill-conditioned directions. Therefore, there is a need for a broader and more fine-grained degeneracy detection and handling method. This paper proposes a new point cloud registration framework, LP-ICP, that combines point-to-line and point-to-plane distance metrics in the ICP algorithm, with localizability detection and handling. LP-ICP consists of a localizability detection module and an optimization module. The localizability detection module performs localizability analysis by utilizing the correspondences between edge points (with low local smoothness) to lines and planar points (with high local smoothness) to planes between the scan and the map. The localizability contribution of individual correspondence constraints can be applied to a broader range. The optimization module adds additional soft and hard constraints to the optimization equations based on the localizability category. This allows the pose to be constrained along ill-conditioned directions, with updates either tending towards the constraint value or leaving the initial estimate unchanged. This improves accuracy and reduces fluctuations. The proposed method is extensively evaluated through experiments on both simulation and real-world datasets, demonstrating higher or comparable accuracy than the state-of-the-art methods. The dataset and code of this paper will also be open-sourced at https://github.com/xuqingyuan2000/LP-ICP.
Multi-modality Affinity Inference for Weakly Supervised 3D Semantic Segmentation
Dec 29, 20233D point cloud semantic segmentation has a wide range of applications. Recently, weakly supervised point cloud segmentation methods have been proposed, aiming to alleviate the expensive and laborious manual annotation process by leveraging scene-level labels. However, these methods have not effectively exploited the rich geometric information (such as shape and scale) and appearance information (such as color and texture) present in RGB-D scans. Furthermore, current approaches fail to fully leverage the point affinity that can be inferred from the feature extraction network, which is crucial for learning from weak scene-level labels. Additionally, previous work overlooks the detrimental effects of the long-tailed distribution of point cloud data in weakly supervised 3D semantic segmentation. To this end, this paper proposes a simple yet effective scene-level weakly supervised point cloud segmentation method with a newly introduced multi-modality point affinity inference module. The point affinity proposed in this paper is characterized by features from multiple modalities (e.g., point cloud and RGB), and is further refined by normalizing the classifier weights to alleviate the detrimental effects of long-tailed distribution without the need of the prior of category distribution. Extensive experiments on the ScanNet and S3DIS benchmarks verify the effectiveness of our proposed method, which outperforms the state-of-the-art by ~4% to ~6% mIoU. Codes are released at https://github.com/Sunny599/AAAI24-3DWSSG-MMA.
Diffusion Model is Secretly a Training-free Open Vocabulary Semantic Segmenter
Sep 06, 2023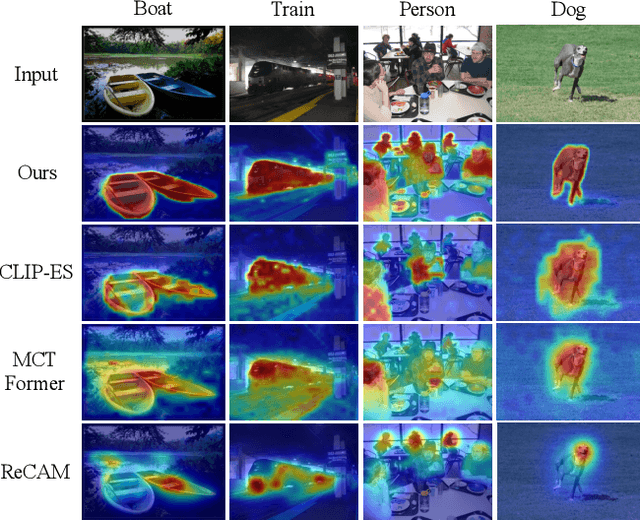
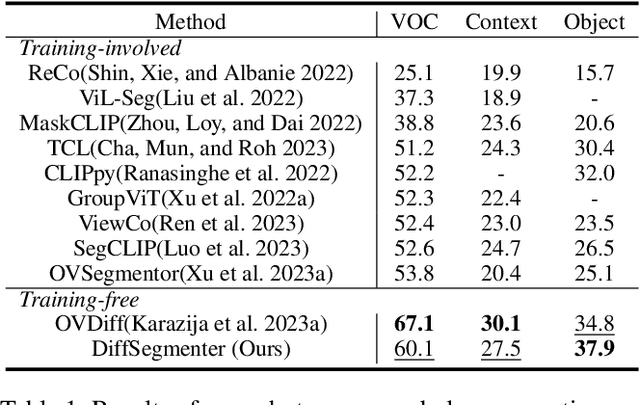
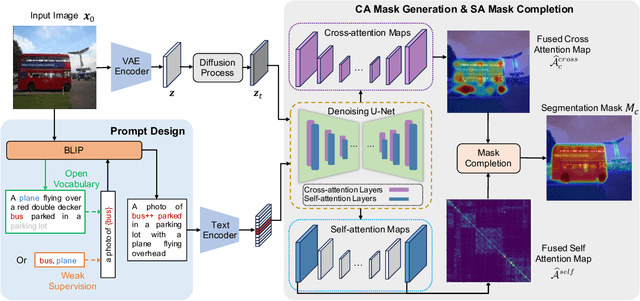
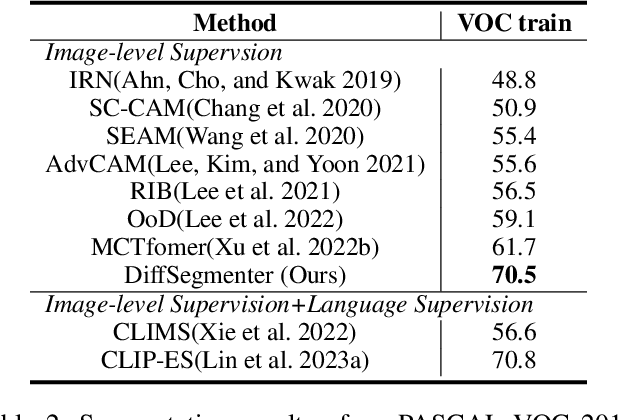
Recent research has explored the utilization of pre-trained text-image discriminative models, such as CLIP, to tackle the challenges associated with open-vocabulary semantic segmentation. However, it is worth noting that the alignment process based on contrastive learning employed by these models may unintentionally result in the loss of crucial localization information and object completeness, which are essential for achieving accurate semantic segmentation. More recently, there has been an emerging interest in extending the application of diffusion models beyond text-to-image generation tasks, particularly in the domain of semantic segmentation. These approaches utilize diffusion models either for generating annotated data or for extracting features to facilitate semantic segmentation. This typically involves training segmentation models by generating a considerable amount of synthetic data or incorporating additional mask annotations. To this end, we uncover the potential of generative text-to-image conditional diffusion models as highly efficient open-vocabulary semantic segmenters, and introduce a novel training-free approach named DiffSegmenter. Specifically, by feeding an input image and candidate classes into an off-the-shelf pre-trained conditional latent diffusion model, the cross-attention maps produced by the denoising U-Net are directly used as segmentation scores, which are further refined and completed by the followed self-attention maps. Additionally, we carefully design effective textual prompts and a category filtering mechanism to further enhance the segmentation results. Extensive experiments on three benchmark datasets show that the proposed DiffSegmenter achieves impressive results for open-vocabulary semantic segmentation.