 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIConfigurator: Lightning-Fast Configuration Optimization for Multi-Framework LLM Serving
Jan 09, 2026Optimizing Large Language Model (LLM) inference in production systems is increasingly difficult due to dynamic workloads, stringent latency/throughput targets, and a rapidly expanding configuration space. This complexity spans not only distributed parallelism strategies (tensor/pipeline/expert) but also intricate framework-specific runtime parameters such as those concerning the enablement of CUDA graphs, available KV-cache memory fractions, and maximum token capacity, which drastically impact performance. The diversity of modern inference frameworks (e.g., TRT-LLM, vLLM, SGLang), each employing distinct kernels and execution policies, makes manual tuning both framework-specific and computationally prohibitive. We present AIConfigurator, a unified performance-modeling system that enables rapid, framework-agnostic inference configuration search without requiring GPU-based profiling. AIConfigurator combines (1) a methodology that decomposes inference into analytically modelable primitives - GEMM, attention, communication, and memory operations while capturing framework-specific scheduling dynamics; (2) a calibrated kernel-level performance database for these primitives across a wide range of hardware platforms and popular open-weights models (GPT-OSS, Qwen, DeepSeek, LLama, Mistral); and (3) an abstraction layer that automatically resolves optimal launch parameters for the target backend, seamlessly integrating into production-grade orchestration systems. Evaluation on production LLM serving workloads demonstrates that AIConfigurator identifies superior serving configurations that improve performance by up to 40% for dense models (e.g., Qwen3-32B) and 50% for MoE architectures (e.g., DeepSeek-V3), while completing searches within 30 seconds on average. Enabling the rapid exploration of vast design spaces - from cluster topology down to engine specific flags.
ELBO-T2IAlign: A Generic ELBO-Based Method for Calibrating Pixel-level Text-Image Alignment in Diffusion Models
Jun 11, 2025Diffusion models excel at image generation. Recent studies have shown that these models not only generate high-quality images but also encode text-image alignment information through attention maps or loss functions. This information is valuable for various downstream tasks, including segmentation, text-guided image editing, and compositional image generation. However, current methods heavily rely on the assumption of perfect text-image alignment in diffusion models, which is not the case. In this paper, we propose using zero-shot referring image segmentation as a proxy task to evaluate the pixel-level image and class-level text alignment of popular diffusion models. We conduct an in-depth analysis of pixel-text misalignment in diffusion models from the perspective of training data bias. We find that misalignment occurs in images with small sized, occluded, or rare object classes. Therefore, we propose ELBO-T2IAlign, a simple yet effective method to calibrate pixel-text alignment in diffusion models based on the evidence lower bound (ELBO) of likelihood. Our method is training-free and generic, eliminating the need to identify the specific cause of misalignment and works well across various diffusion model architectures. Extensive experiments on commonly used benchmark datasets on image segmentation and generation have verified the effectiveness of our proposed calibration approach.
Large language models enabled multiagent ensemble method for efficient EHR data labeling
Oct 21, 2024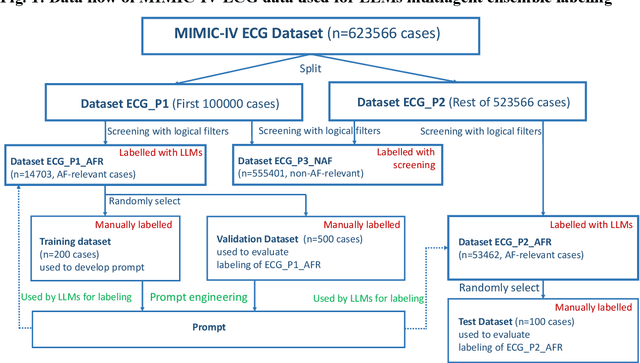
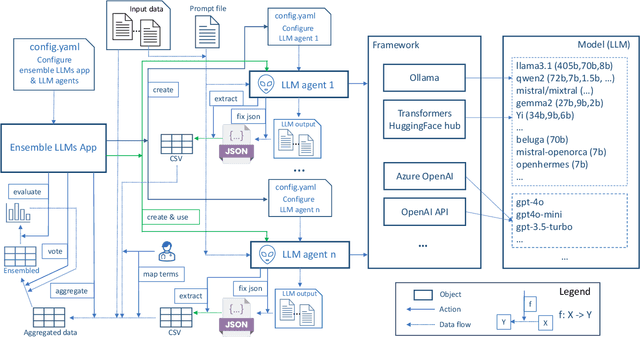
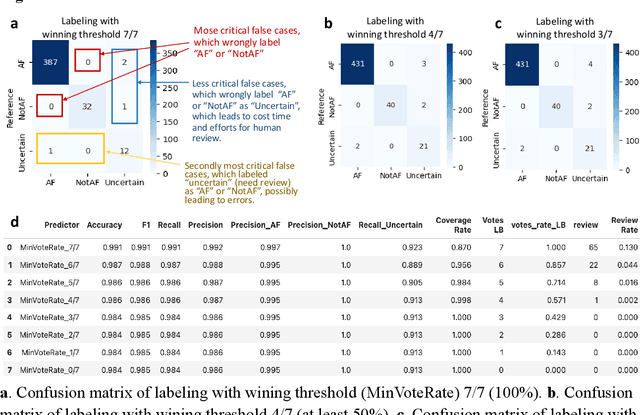
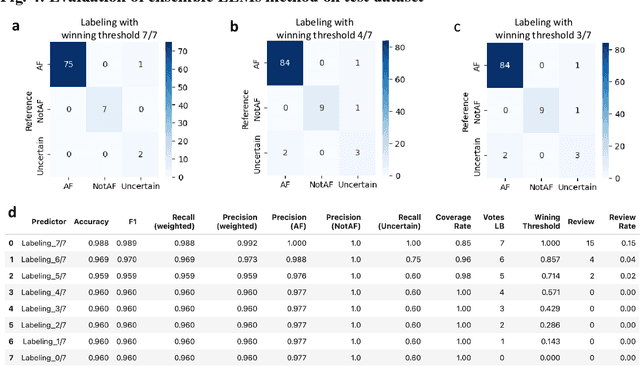
This study introduces a novel multiagent ensemble method powered by LLMs to address a key challenge in ML - data labeling, particularly in large-scale EHR datasets. Manual labeling of such datasets requires domain expertise and is labor-intensive, time-consuming, expensive, and error-prone. To overcome this bottleneck, we developed an ensemble LLMs method and demonstrated its effectiveness in two real-world tasks: (1) labeling a large-scale unlabeled ECG dataset in MIMIC-IV; (2) identifying social determinants of health (SDOH) from the clinical notes of EHR. Trading off benefits and cost, we selected a pool of diverse open source LLMs with satisfactory performance. We treat each LLM's prediction as a vote and apply a mechanism of majority voting with minimal winning threshold for ensemble. We implemented an ensemble LLMs application for EHR data labeling tasks. By using the ensemble LLMs and natural language processing, we labeled MIMIC-IV ECG dataset of 623,566 ECG reports with an estimated accuracy of 98.2%. We applied the ensemble LLMs method to identify SDOH from social history sections of 1,405 EHR clinical notes, also achieving competitive performance. Our experiments show that the ensemble LLMs can outperform individual LLM even the best commercial one, and the method reduces hallucination errors. From the research, we found that (1) the ensemble LLMs method significantly reduces the time and effort required for labeling large-scale EHR data, automating the process with high accuracy and quality; (2) the method generalizes well to other text data labeling tasks, as shown by its application to SDOH identification; (3) the ensemble of a group of diverse LLMs can outperform or match the performance of the best individual LLM; and (4) the ensemble method substantially reduces hallucination errors. This approach provides a scalable and efficient solution to data-labeling challenges.
Automatic Organ and Pan-cancer Segmentation in Abdomen CT: the FLARE 2023 Challenge
Aug 22, 2024Organ and cancer segmentation in abdomen Computed Tomography (CT) scans is the prerequisite for precise cancer diagnosis and treatment. Most existing benchmarks and algorithms are tailored to specific cancer types, limiting their ability to provide comprehensive cancer analysis. This work presents the first international competition on abdominal organ and pan-cancer segmentation by providing a large-scale and diverse dataset, including 4650 CT scans with various cancer types from over 40 medical centers. The winning team established a new state-of-the-art with a deep learning-based cascaded framework, achieving average Dice Similarity Coefficient scores of 92.3% for organs and 64.9% for lesions on the hidden multi-national testing set. The dataset and code of top teams are publicly available, offering a benchmark platform to drive further innovations https://codalab.lisn.upsaclay.fr/competitions/12239.
Attention Calibration for Disentangled Text-to-Image Personalization
Apr 11, 2024Recent thrilling progress in large-scale text-to-image (T2I) models has unlocked unprecedented synthesis quality of AI-generated content (AIGC) including image generation, 3D and video composition. Further, personalized techniques enable appealing customized production of a novel concept given only several images as reference. However, an intriguing problem persists: Is it possible to capture multiple, novel concepts from one single reference image? In this paper, we identify that existing approaches fail to preserve visual consistency with the reference image and eliminate cross-influence from concepts. To alleviate this, we propose an attention calibration mechanism to improve the concept-level understanding of the T2I model. Specifically, we first introduce new learnable modifiers bound with classes to capture attributes of multiple concepts. Then, the classes are separated and strengthened following the activation of the cross-attention operation, ensuring comprehensive and self-contained concepts. Additionally, we suppress the attention activation of different classes to mitigate mutual influence among concepts. Together, our proposed method, dubbed DisenDiff, can learn disentangled multiple concepts from one single image and produce novel customized images with learned concepts. We demonstrate that our method outperforms the current state of the art in both qualitative and quantitative evaluations. More importantly, our proposed techniques are compatible with LoRA and inpainting pipelines, enabling more interactive experiences.
Diffusion Model is Secretly a Training-free Open Vocabulary Semantic Segmenter
Sep 06, 2023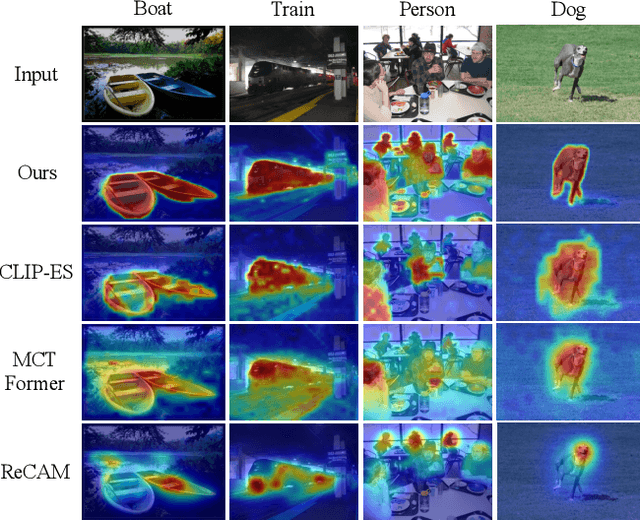
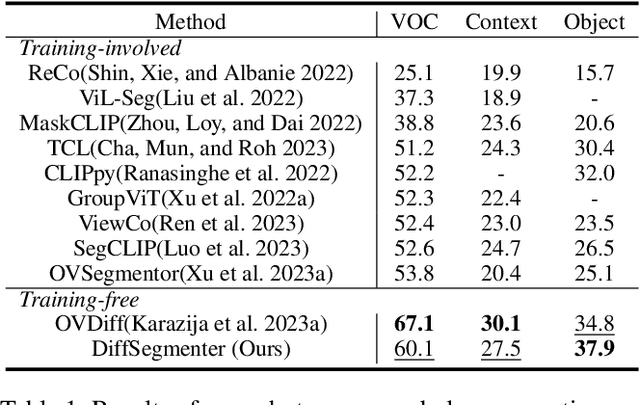
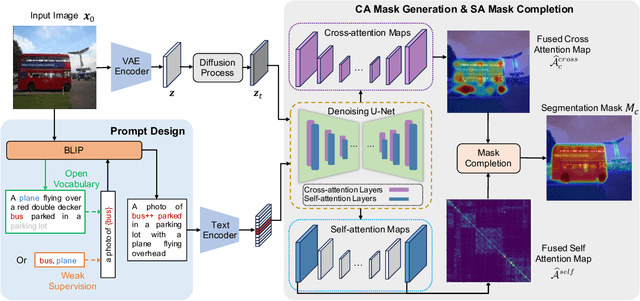
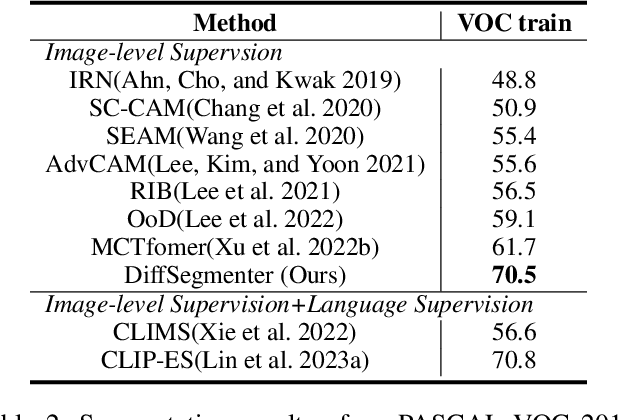
Recent research has explored the utilization of pre-trained text-image discriminative models, such as CLIP, to tackle the challenges associated with open-vocabulary semantic segmentation. However, it is worth noting that the alignment process based on contrastive learning employed by these models may unintentionally result in the loss of crucial localization information and object completeness, which are essential for achieving accurate semantic segmentation. More recently, there has been an emerging interest in extending the application of diffusion models beyond text-to-image generation tasks, particularly in the domain of semantic segmentation. These approaches utilize diffusion models either for generating annotated data or for extracting features to facilitate semantic segmentation. This typically involves training segmentation models by generating a considerable amount of synthetic data or incorporating additional mask annotations. To this end, we uncover the potential of generative text-to-image conditional diffusion models as highly efficient open-vocabulary semantic segmenters, and introduce a novel training-free approach named DiffSegmenter. Specifically, by feeding an input image and candidate classes into an off-the-shelf pre-trained conditional latent diffusion model, the cross-attention maps produced by the denoising U-Net are directly used as segmentation scores, which are further refined and completed by the followed self-attention maps. Additionally, we carefully design effective textual prompts and a category filtering mechanism to further enhance the segmentation results. Extensive experiments on three benchmark datasets show that the proposed DiffSegmenter achieves impressive results for open-vocabulary semantic segmentation.
KiPA22 Report: U-Net with Contour Regularization for Renal Structures Segmentation
Aug 10, 2022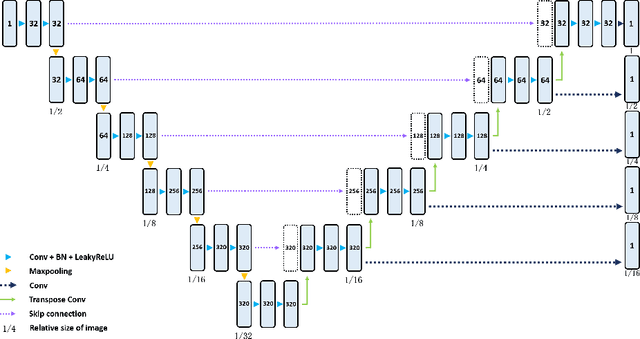
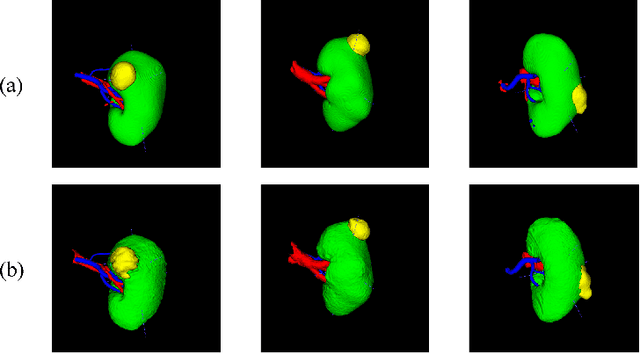

Three-dimensional (3D) integrated renal structures (IRS) segmentation is important in clinical practice. With the advancement of deep learning techniques, many powerful frameworks focusing on medical image segmentation are proposed. In this challenge, we utilized the nnU-Net framework, which is the state-of-the-art method for medical image segmentation. To reduce the outlier prediction for the tumor label, we combine contour regularization (CR) loss of the tumor label with Dice loss and cross-entropy loss to improve this phenomenon.
Seq-Masks: Bridging the gap between appearance and gait modeling for video-based person re-identification
Dec 10, 2021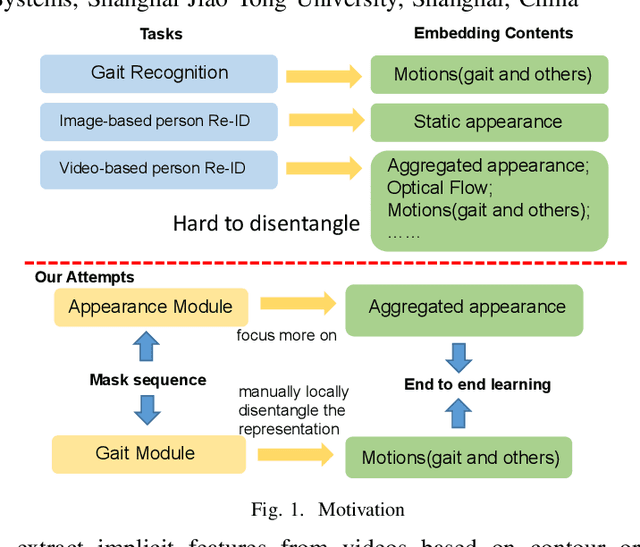
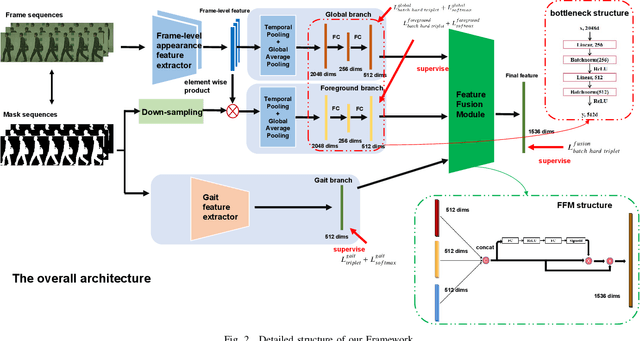
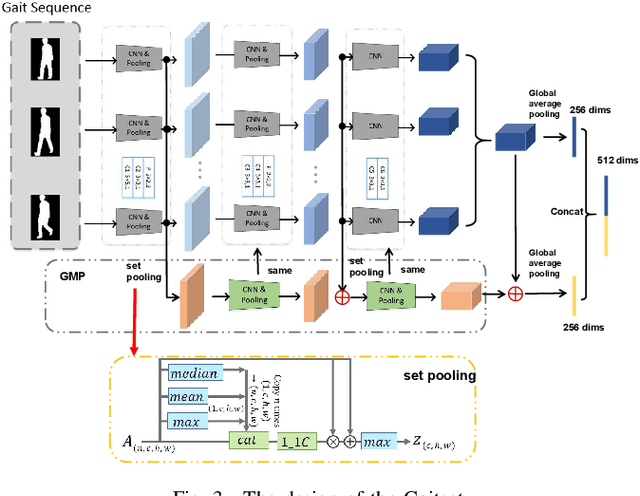

ideo-based person re-identification (Re-ID) aims to match person images in video sequences captured by disjoint surveillance cameras. Traditional video-based person Re-ID methods focus on exploring appearance information, thus, vulnerable against illumination changes, scene noises, camera parameters, and especially clothes/carrying variations. Gait recognition provides an implicit biometric solution to alleviate the above headache. Nonetheless, it experiences severe performance degeneration as camera view varies. In an attempt to address these problems, in this paper, we propose a framework that utilizes the sequence masks (SeqMasks) in the video to integrate appearance information and gait modeling in a close fashion. Specifically, to sufficiently validate the effectiveness of our method, we build a novel dataset named MaskMARS based on MARS. Comprehensive experiments on our proposed large wild video Re-ID dataset MaskMARS evidenced our extraordinary performance and generalization capability. Validations on the gait recognition metric CASIA-B dataset further demonstrated the capability of our hybrid model.
Subtask-dominated Transfer Learning for Long-tail Person Search
Dec 01, 2021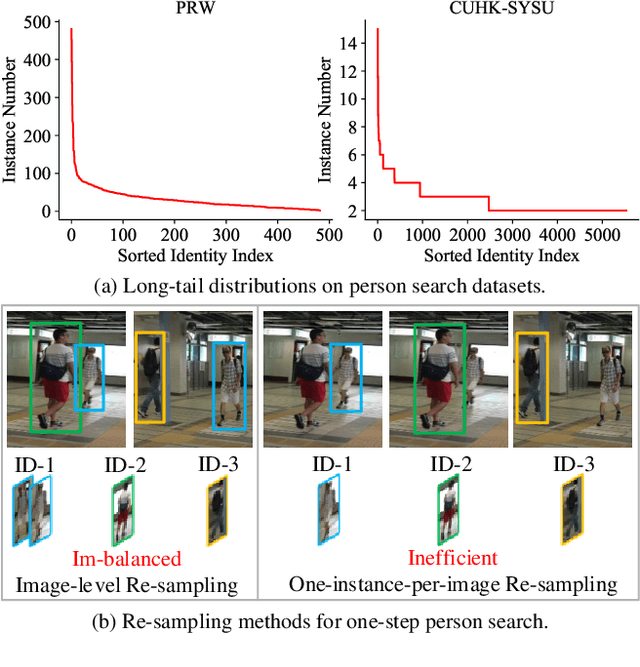
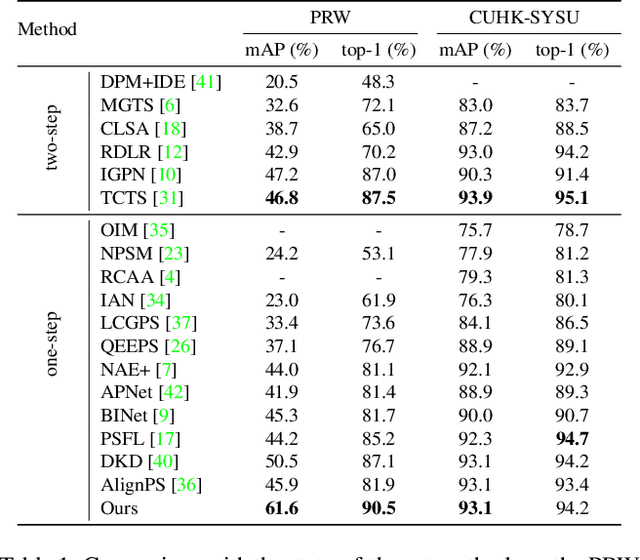

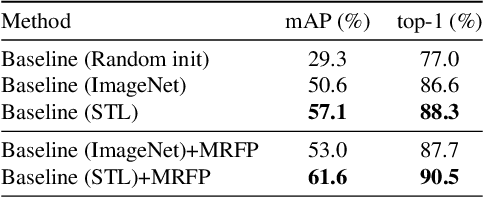
Person search unifies person detection and person re-identification (Re-ID) to locate query persons from the panoramic gallery images. One major challenge comes from the imbalanced long-tail person identity distributions, which prevents the one-step person search model from learning discriminative person features for the final re-identification. However, it is under-explored how to solve the heavy imbalanced identity distributions for the one-step person search. Techniques designed for the long-tail classification task, for example, image-level re-sampling strategies, are hard to be effectively applied to the one-step person search which jointly solves person detection and Re-ID subtasks with a detection-based multi-task framework. To tackle this problem, we propose a Subtask-dominated Transfer Learning (STL) method. The STL method solves the long-tail problem in the pretraining stage of the dominated Re-ID subtask and improves the one-step person search by transfer learning of the pretrained model. We further design a Multi-level RoI Fusion Pooling layer to enhance the discrimination ability of person features for the one-step person search. Extensive experiments on CUHK-SYSU and PRW datasets demonstrate the superiority and effectiveness of the proposed method.
Making Person Search Enjoy the Merits of Person Re-identification
Aug 24, 2021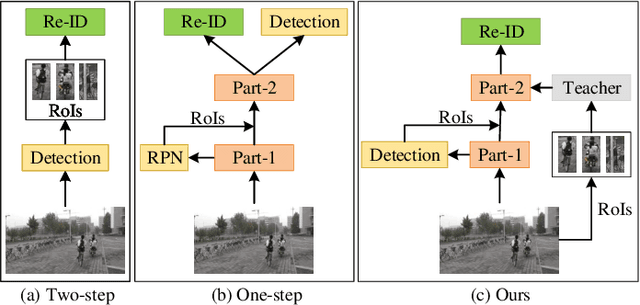
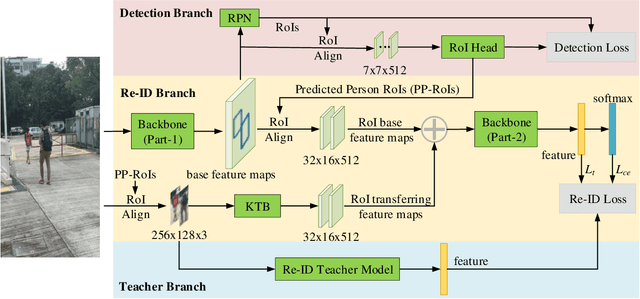

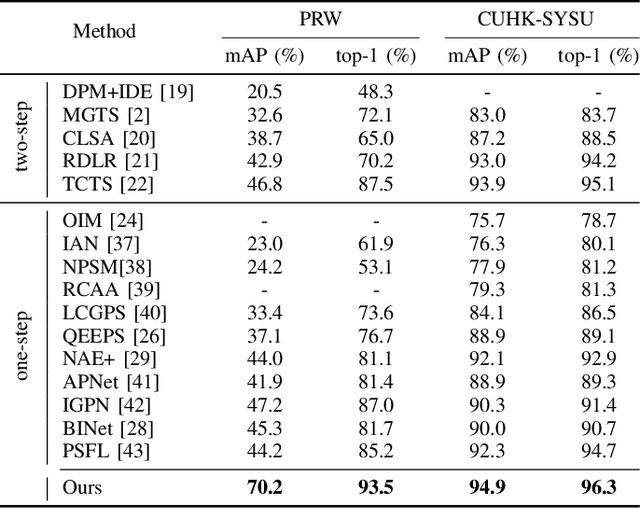
Person search is an extended task of person re-identification (Re-ID). However, most existing one-step person search works have not studied how to employ existing advanced Re-ID models to boost the one-step person search performance due to the integration of person detection and Re-ID. To address this issue, we propose a faster and stronger one-step person search framework, the Teacher-guided Disentangling Networks (TDN), to make the one-step person search enjoy the merits of the existing Re-ID researches. The proposed TDN can significantly boost the person search performance by transferring the advanced person Re-ID knowledge to the person search model. In the proposed TDN, for better knowledge transfer from the Re-ID teacher model to the one-step person search model, we design a strong one-step person search base framework by partially disentangling the two subtasks. Besides, we propose a Knowledge Transfer Bridge module to bridge the scale gap caused by different input formats between the Re-ID model and one-step person search model. During testing, we further propose the Ranking with Context Persons strategy to exploit the context information in panoramic images for better retrieval. Experiments on two public person search datasets demonstrate the favorable performance of the proposed method.