 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniGlyph: Unified Segmentation-Conditioned Diffusion for Precise Visual Text Synthesis
Jul 02, 2025Text-to-image generation has greatly advanced content creation, yet accurately rendering visual text remains a key challenge due to blurred glyphs, semantic drift, and limited style control. Existing methods often rely on pre-rendered glyph images as conditions, but these struggle to retain original font styles and color cues, necessitating complex multi-branch designs that increase model overhead and reduce flexibility. To address these issues, we propose a segmentation-guided framework that uses pixel-level visual text masks -- rich in glyph shape, color, and spatial detail -- as unified conditional inputs. Our method introduces two core components: (1) a fine-tuned bilingual segmentation model for precise text mask extraction, and (2) a streamlined diffusion model augmented with adaptive glyph conditioning and a region-specific loss to preserve textual fidelity in both content and style. Our approach achieves state-of-the-art performance on the AnyText benchmark, significantly surpassing prior methods in both Chinese and English settings. To enable more rigorous evaluation, we also introduce two new benchmarks: GlyphMM-benchmark for testing layout and glyph consistency in complex typesetting, and MiniText-benchmark for assessing generation quality in small-scale text regions. Experimental results show that our model outperforms existing methods by a large margin in both scenarios, particularly excelling at small text rendering and complex layout preservation, validating its strong generalization and deployment readiness.
LLMs Can Simulate Standardized Patients via Agent Coevolution
Dec 16, 2024Training medical personnel using standardized patients (SPs) remains a complex challenge, requiring extensive domain expertise and role-specific practice. Most research on Large Language Model (LLM)-based simulated patients focuses on improving data retrieval accuracy or adjusting prompts through human feedback. However, this focus has overlooked the critical need for patient agents to learn a standardized presentation pattern that transforms data into human-like patient responses through unsupervised simulations. To address this gap, we propose EvoPatient, a novel simulated patient framework in which a patient agent and doctor agents simulate the diagnostic process through multi-turn dialogues, simultaneously gathering experience to improve the quality of both questions and answers, ultimately enabling human doctor training. Extensive experiments on various cases demonstrate that, by providing only overall SP requirements, our framework improves over existing reasoning methods by more than 10% in requirement alignment and better human preference, while achieving an optimal balance of resource consumption after evolving over 200 cases for 10 hours, with excellent generalizability. The code will be available at https://github.com/ZJUMAI/EvoPatient.
Multi-modality Affinity Inference for Weakly Supervised 3D Semantic Segmentation
Dec 29, 20233D point cloud semantic segmentation has a wide range of applications. Recently, weakly supervised point cloud segmentation methods have been proposed, aiming to alleviate the expensive and laborious manual annotation process by leveraging scene-level labels. However, these methods have not effectively exploited the rich geometric information (such as shape and scale) and appearance information (such as color and texture) present in RGB-D scans. Furthermore, current approaches fail to fully leverage the point affinity that can be inferred from the feature extraction network, which is crucial for learning from weak scene-level labels. Additionally, previous work overlooks the detrimental effects of the long-tailed distribution of point cloud data in weakly supervised 3D semantic segmentation. To this end, this paper proposes a simple yet effective scene-level weakly supervised point cloud segmentation method with a newly introduced multi-modality point affinity inference module. The point affinity proposed in this paper is characterized by features from multiple modalities (e.g., point cloud and RGB), and is further refined by normalizing the classifier weights to alleviate the detrimental effects of long-tailed distribution without the need of the prior of category distribution. Extensive experiments on the ScanNet and S3DIS benchmarks verify the effectiveness of our proposed method, which outperforms the state-of-the-art by ~4% to ~6% mIoU. Codes are released at https://github.com/Sunny599/AAAI24-3DWSSG-MMA.
Diffusion Model is Secretly a Training-free Open Vocabulary Semantic Segmenter
Sep 06, 2023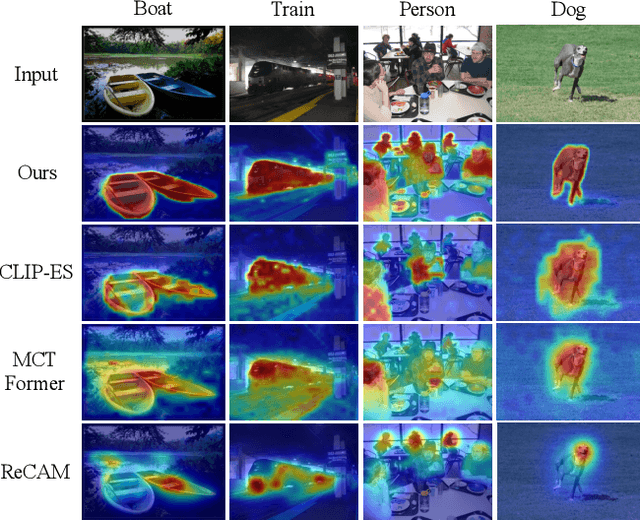
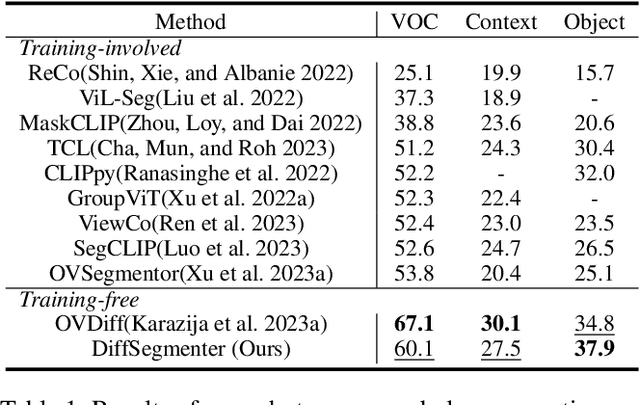
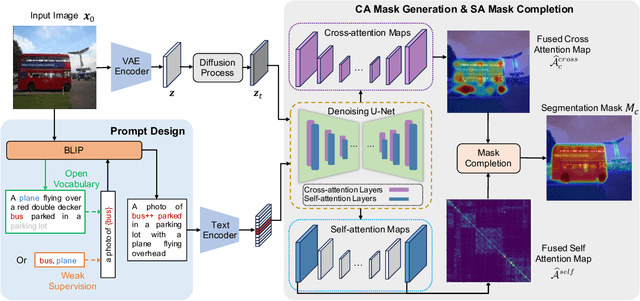
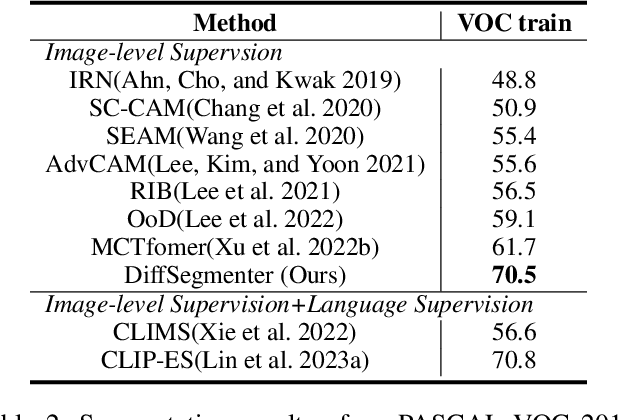
Recent research has explored the utilization of pre-trained text-image discriminative models, such as CLIP, to tackle the challenges associated with open-vocabulary semantic segmentation. However, it is worth noting that the alignment process based on contrastive learning employed by these models may unintentionally result in the loss of crucial localization information and object completeness, which are essential for achieving accurate semantic segmentation. More recently, there has been an emerging interest in extending the application of diffusion models beyond text-to-image generation tasks, particularly in the domain of semantic segmentation. These approaches utilize diffusion models either for generating annotated data or for extracting features to facilitate semantic segmentation. This typically involves training segmentation models by generating a considerable amount of synthetic data or incorporating additional mask annotations. To this end, we uncover the potential of generative text-to-image conditional diffusion models as highly efficient open-vocabulary semantic segmenters, and introduce a novel training-free approach named DiffSegmenter. Specifically, by feeding an input image and candidate classes into an off-the-shelf pre-trained conditional latent diffusion model, the cross-attention maps produced by the denoising U-Net are directly used as segmentation scores, which are further refined and completed by the followed self-attention maps. Additionally, we carefully design effective textual prompts and a category filtering mechanism to further enhance the segmentation results. Extensive experiments on three benchmark datasets show that the proposed DiffSegmenter achieves impressive results for open-vocabulary semantic segmentation.