 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRAB: An LLM-Inspired Sequence-First Click-Through Rate Prediction Modeling Paradigm
Feb 03, 2026Traditional Deep Learning Recommendation Models (DLRMs) face increasing bottlenecks in performance and efficiency, often struggling with generalization and long-sequence modeling. Inspired by the scaling success of Large Language Models (LLMs), we propose Generative Ranking for Ads at Baidu (GRAB), an end-to-end generative framework for Click-Through Rate (CTR) prediction. GRAB integrates a novel Causal Action-aware Multi-channel Attention (CamA) mechanism to effectively capture temporal dynamics and specific action signals within user behavior sequences. Full-scale online deployment demonstrates that GRAB significantly outperforms established DLRMs, delivering a 3.05% increase in revenue and a 3.49% rise in CTR. Furthermore, the model demonstrates desirable scaling behavior: its expressive power shows a monotonic and approximately linear improvement as longer interaction sequences are utilized.
UniGlyph: Unified Segmentation-Conditioned Diffusion for Precise Visual Text Synthesis
Jul 02, 2025Text-to-image generation has greatly advanced content creation, yet accurately rendering visual text remains a key challenge due to blurred glyphs, semantic drift, and limited style control. Existing methods often rely on pre-rendered glyph images as conditions, but these struggle to retain original font styles and color cues, necessitating complex multi-branch designs that increase model overhead and reduce flexibility. To address these issues, we propose a segmentation-guided framework that uses pixel-level visual text masks -- rich in glyph shape, color, and spatial detail -- as unified conditional inputs. Our method introduces two core components: (1) a fine-tuned bilingual segmentation model for precise text mask extraction, and (2) a streamlined diffusion model augmented with adaptive glyph conditioning and a region-specific loss to preserve textual fidelity in both content and style. Our approach achieves state-of-the-art performance on the AnyText benchmark, significantly surpassing prior methods in both Chinese and English settings. To enable more rigorous evaluation, we also introduce two new benchmarks: GlyphMM-benchmark for testing layout and glyph consistency in complex typesetting, and MiniText-benchmark for assessing generation quality in small-scale text regions. Experimental results show that our model outperforms existing methods by a large margin in both scenarios, particularly excelling at small text rendering and complex layout preservation, validating its strong generalization and deployment readiness.
Sparse Meets Dense: Unified Generative Recommendations with Cascaded Sparse-Dense Representations
Mar 04, 2025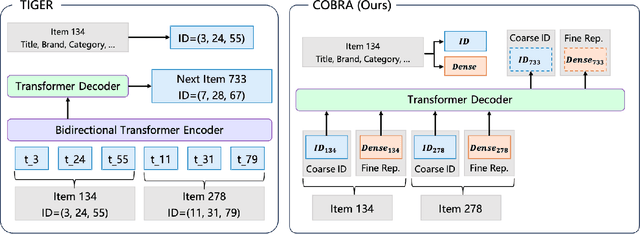
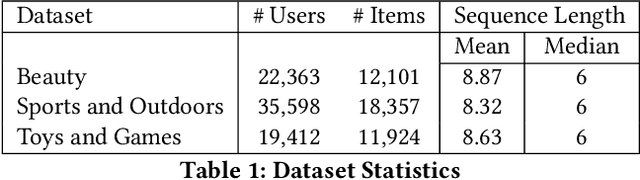
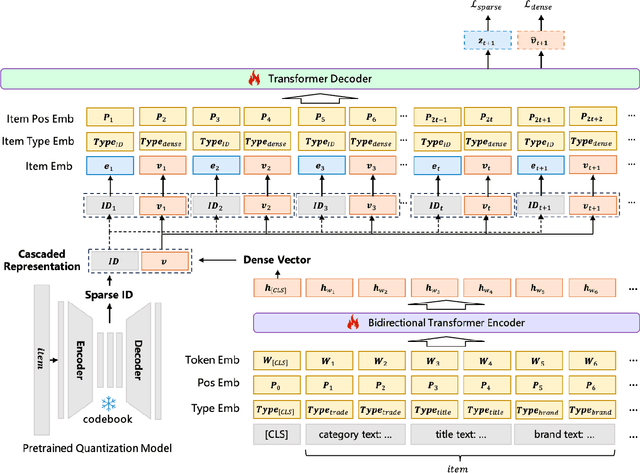
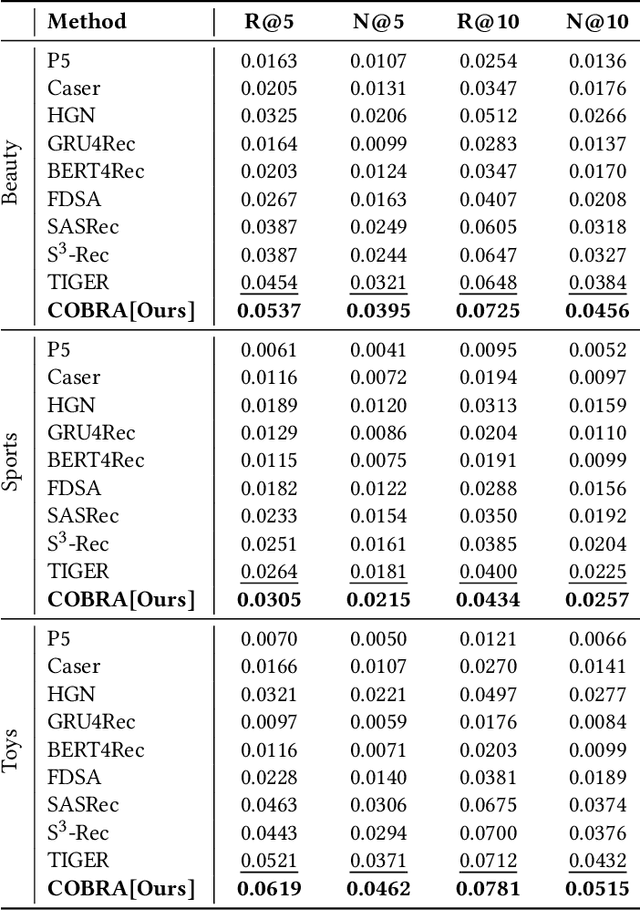
Generative models have recently gained attention in recommendation systems by directly predicting item identifiers from user interaction sequences. However, existing methods suffer from significant information loss due to the separation of stages such as quantization and sequence modeling, hindering their ability to achieve the modeling precision and accuracy of sequential dense retrieval techniques. Integrating generative and dense retrieval methods remains a critical challenge. To address this, we introduce the Cascaded Organized Bi-Represented generAtive retrieval (COBRA) framework, which innovatively integrates sparse semantic IDs and dense vectors through a cascading process. Our method alternates between generating these representations by first generating sparse IDs, which serve as conditions to aid in the generation of dense vectors. End-to-end training enables dynamic refinement of dense representations, capturing both semantic insights and collaborative signals from user-item interactions. During inference, COBRA employs a coarse-to-fine strategy, starting with sparse ID generation and refining them into dense vectors via the generative model. We further propose BeamFusion, an innovative approach combining beam search with nearest neighbor scores to enhance inference flexibility and recommendation diversity. Extensive experiments on public datasets and offline tests validate our method's robustness. Online A/B tests on a real-world advertising platform with over 200 million daily users demonstrate substantial improvements in key metrics, highlighting COBRA's practical advantages.
Enhancing Dynamic Image Advertising with Vision-Language Pre-training
Jun 25, 2023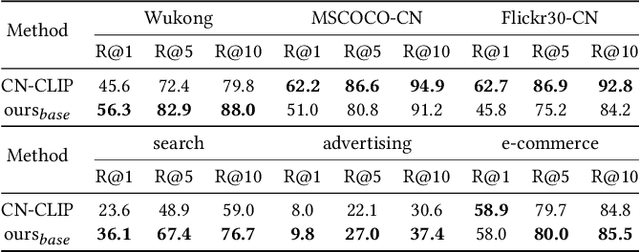
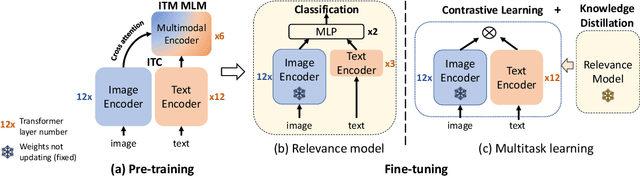


In the multimedia era, image is an effective medium in search advertising. Dynamic Image Advertising (DIA), a system that matches queries with ad images and generates multimodal ads, is introduced to improve user experience and ad revenue. The core of DIA is a query-image matching module performing ad image retrieval and relevance modeling. Current query-image matching suffers from limited and inconsistent data, and insufficient cross-modal interaction. Also, the separate optimization of retrieval and relevance models affects overall performance. To address this issue, we propose a vision-language framework consisting of two parts. First, we train a base model on large-scale image-text pairs to learn general multimodal representation. Then, we fine-tune the base model on advertising business data, unifying relevance modeling and retrieval through multi-objective learning. Our framework has been implemented in Baidu search advertising system "Phoneix Nest". Online evaluation shows that it improves cost per mille (CPM) and click-through rate (CTR) by 1.04% and 1.865%.