 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClue Matters: Leveraging Latent Visual Clues to Empower Video Reasoning
Mar 16, 2026Multi-modal Large Language Models (MLLMs) have significantly advanced video reasoning, yet Video Question Answering (VideoQA) remains challenging due to its demand for temporal causal reasoning and evidence-grounded answer generation. Prevailing end-to-end MLLM frameworks lack explicit structured reasoning between visual perception and answer derivation, causing severe hallucinations and poor interpretability. Existing methods also fail to address three core gaps: faithful visual clue extraction, utility-aware clue filtering, and end-to-end clue-answer alignment. Inspired by hierarchical human visual cognition, we propose ClueNet, a clue-aware video reasoning framework with a two-stage supervised fine-tuning paradigm without extensive base model modifications. Decoupled supervision aligns clue extraction and chain-based reasoning, while inference supervision with an adaptive clue filter refines high-order reasoning, alongside lightweight modules for efficient inference. Experiments on NExT-QA, STAR, and MVBench show that ClueNet outperforms state-of-the-art methods by $\ge$ 1.1%, with superior generalization, hallucination mitigation, inference efficiency, and cross-backbone compatibility. This work bridges the perception-to-generation gap in MLLM video understanding, providing an interpretable, faithful reasoning paradigm for high-stakes VideoQA applications.
Zero-shot Generalizable Graph Anomaly Detection with Mixture of Riemannian Experts
Feb 09, 2026Graph Anomaly Detection (GAD) aims to identify irregular patterns in graph data, and recent works have explored zero-shot generalist GAD to enable generalization to unseen graph datasets. However, existing zero-shot GAD methods largely ignore intrinsic geometric differences across diverse anomaly patterns, substantially limiting their cross-domain generalization. In this work, we reveal that anomaly detectability is highly dependent on the underlying geometric properties and that embedding graphs from different domains into a single static curvature space can distort the structural signatures of anomalies. To address the challenge that a single curvature space cannot capture geometry-dependent graph anomaly patterns, we propose GAD-MoRE, a novel framework for zero-shot Generalizable Graph Anomaly Detection with a Mixture of Riemannian Experts architecture. Specifically, to ensure that each anomaly pattern is modeled in the Riemannian space where it is most detectable, GAD-MoRE employs a set of specialized Riemannian expert networks, each operating in a distinct curvature space. To align raw node features with curvature-specific anomaly characteristics, we introduce an anomaly-aware multi-curvature feature alignment module that projects inputs into parallel Riemannian spaces, enabling the capture of diverse geometric characteristics. Finally, to facilitate better generalization beyond seen patterns, we design a memory-based dynamic router that adaptively assigns each input to the most compatible expert based on historical reconstruction performance on similar anomalies. Extensive experiments in the zero-shot setting demonstrate that GAD-MoRE significantly outperforms state-of-the-art generalist GAD baselines, and even surpasses strong competitors that are few-shot fine-tuned with labeled data from the target domain.
Two Heads are Better than One: Distilling Large Language Model Features Into Small Models with Feature Decomposition and Mixture
Nov 11, 2025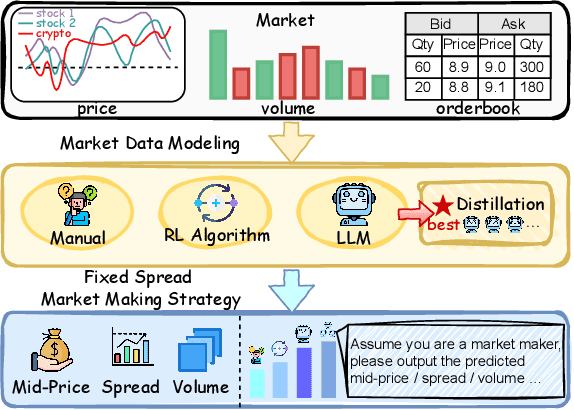

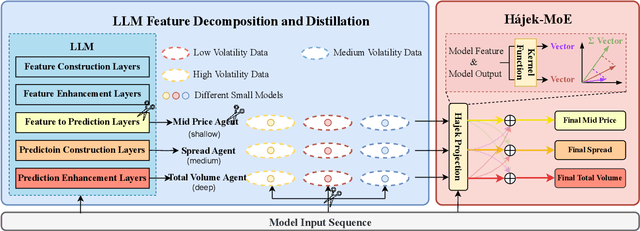

Market making (MM) through Reinforcement Learning (RL) has attracted significant attention in financial trading. With the development of Large Language Models (LLMs), more and more attempts are being made to apply LLMs to financial areas. A simple, direct application of LLM as an agent shows significant performance. Such methods are hindered by their slow inference speed, while most of the current research has not studied LLM distillation for this specific task. To address this, we first propose the normalized fluorescent probe to study the mechanism of the LLM's feature. Based on the observation found by our investigation, we propose Cooperative Market Making (CMM), a novel framework that decouples LLM features across three orthogonal dimensions: layer, task, and data. Various student models collaboratively learn simple LLM features along with different dimensions, with each model responsible for a distinct feature to achieve knowledge distillation. Furthermore, CMM introduces an Hájek-MoE to integrate the output of the student models by investigating the contribution of different models in a kernel function-generated common feature space. Extensive experimental results on four real-world market datasets demonstrate the superiority of CMM over the current distillation method and RL-based market-making strategies.
Metacognitive Self-Correction for Multi-Agent System via Prototype-Guided Next-Execution Reconstruction
Oct 16, 2025Large Language Model based multi-agent systems (MAS) excel at collaborative problem solving but remain brittle to cascading errors: a single faulty step can propagate across agents and disrupt the trajectory. In this paper, we present MASC, a metacognitive framework that endows MAS with real-time, unsupervised, step-level error detection and self-correction. MASC rethinks detection as history-conditioned anomaly scoring via two complementary designs: (1) Next-Execution Reconstruction, which predicts the embedding of the next step from the query and interaction history to capture causal consistency, and (2) Prototype-Guided Enhancement, which learns a prototype prior over normal-step embeddings and uses it to stabilize reconstruction and anomaly scoring under sparse context (e.g., early steps). When an anomaly step is flagged, MASC triggers a correction agent to revise the acting agent's output before information flows downstream. On the Who&When benchmark, MASC consistently outperforms all baselines, improving step-level error detection by up to 8.47% AUC-ROC ; When plugged into diverse MAS frameworks, it delivers consistent end-to-end gains across architectures, confirming that our metacognitive monitoring and targeted correction can mitigate error propagation with minimal overhead.
GTCN-G: A Residual Graph-Temporal Fusion Network for Imbalanced Intrusion Detection (Preprint)
Oct 08, 2025The escalating complexity of network threats and the inherent class imbalance in traffic data present formidable challenges for modern Intrusion Detection Systems (IDS). While Graph Neural Networks (GNNs) excel in modeling topological structures and Temporal Convolutional Networks (TCNs) are proficient in capturing time-series dependencies, a framework that synergistically integrates both while explicitly addressing data imbalance remains an open challenge. This paper introduces a novel deep learning framework, named Gated Temporal Convolutional Network and Graph (GTCN-G), engineered to overcome these limitations. Our model uniquely fuses a Gated TCN (G-TCN) for extracting hierarchical temporal features from network flows with a Graph Convolutional Network (GCN) designed to learn from the underlying graph structure. The core innovation lies in the integration of a residual learning mechanism, implemented via a Graph Attention Network (GAT). This mechanism preserves original feature information through residual connections, which is critical for mitigating the class imbalance problem and enhancing detection sensitivity for rare malicious activities (minority classes). We conducted extensive experiments on two public benchmark datasets, UNSW-NB15 and ToN-IoT, to validate our approach. The empirical results demonstrate that the proposed GTCN-G model achieves state-of-the-art performance, significantly outperforming existing baseline models in both binary and multi-class classification tasks.
Transferring Expert Cognitive Models to Social Robots via Agentic Concept Bottleneck Models
Aug 06, 2025Successful group meetings, such as those implemented in group behavioral-change programs, work meetings, and other social contexts, must promote individual goal setting and execution while strengthening the social relationships within the group. Consequently, an ideal facilitator must be sensitive to the subtle dynamics of disengagement, difficulties with individual goal setting and execution, and interpersonal difficulties that signal a need for intervention. The challenges and cognitive load experienced by facilitators create a critical gap for an embodied technology that can interpret social exchanges while remaining aware of the needs of the individuals in the group and providing transparent recommendations that go beyond powerful but "black box" foundation models (FMs) that identify social cues. We address this important demand with a social robot co-facilitator that analyzes multimodal meeting data and provides discreet cues to the facilitator. The robot's reasoning is powered by an agentic concept bottleneck model (CBM), which makes decisions based on human-interpretable concepts like participant engagement and sentiments, ensuring transparency and trustworthiness. Our core contribution is a transfer learning framework that distills the broad social understanding of an FM into our specialized and transparent CBM. This concept-driven system significantly outperforms direct zero-shot FMs in predicting the need for intervention and enables real-time human correction of its reasoning. Critically, we demonstrate robust knowledge transfer: the model generalizes across different groups and successfully transfers the expertise of senior human facilitators to improve the performance of novices. By transferring an expert's cognitive model into an interpretable robotic partner, our work provides a powerful blueprint for augmenting human capabilities in complex social domains.
ChartMuseum: Testing Visual Reasoning Capabilities of Large Vision-Language Models
May 19, 2025Chart understanding presents a unique challenge for large vision-language models (LVLMs), as it requires the integration of sophisticated textual and visual reasoning capabilities. However, current LVLMs exhibit a notable imbalance between these skills, falling short on visual reasoning that is difficult to perform in text. We conduct a case study using a synthetic dataset solvable only through visual reasoning and show that model performance degrades significantly with increasing visual complexity, while human performance remains robust. We then introduce ChartMuseum, a new Chart Question Answering (QA) benchmark containing 1,162 expert-annotated questions spanning multiple reasoning types, curated from real-world charts across 184 sources, specifically built to evaluate complex visual and textual reasoning. Unlike prior chart understanding benchmarks -- where frontier models perform similarly and near saturation -- our benchmark exposes a substantial gap between model and human performance, while effectively differentiating model capabilities: although humans achieve 93% accuracy, the best-performing model Gemini-2.5-Pro attains only 63.0%, and the leading open-source LVLM Qwen2.5-VL-72B-Instruct achieves only 38.5%. Moreover, on questions requiring primarily visual reasoning, all models experience a 35%-55% performance drop from text-reasoning-heavy question performance. Lastly, our qualitative error analysis reveals specific categories of visual reasoning that are challenging for current LVLMs.
Contour Field based Elliptical Shape Prior for the Segment Anything Model
Apr 17, 2025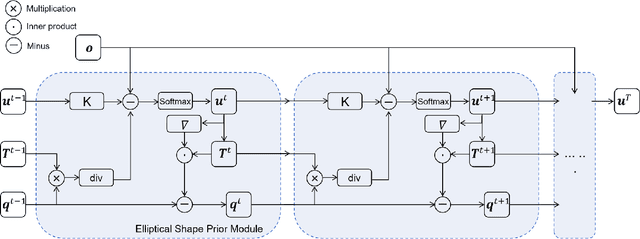
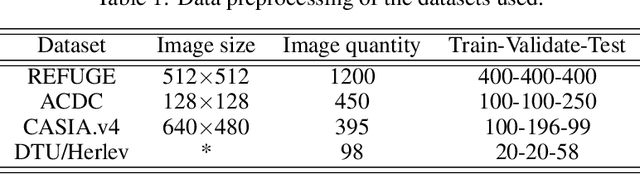

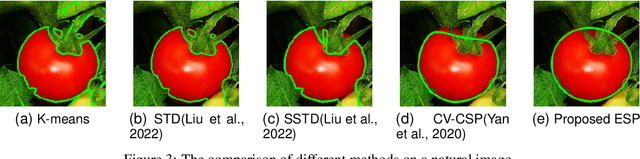
The elliptical shape prior information plays a vital role in improving the accuracy of image segmentation for specific tasks in medical and natural images. Existing deep learning-based segmentation methods, including the Segment Anything Model (SAM), often struggle to produce segmentation results with elliptical shapes efficiently. This paper proposes a new approach to integrate the prior of elliptical shapes into the deep learning-based SAM image segmentation techniques using variational methods. The proposed method establishes a parameterized elliptical contour field, which constrains the segmentation results to align with predefined elliptical contours. Utilizing the dual algorithm, the model seamlessly integrates image features with elliptical priors and spatial regularization priors, thereby greatly enhancing segmentation accuracy. By decomposing SAM into four mathematical sub-problems, we integrate the variational ellipse prior to design a new SAM network structure, ensuring that the segmentation output of SAM consists of elliptical regions. Experimental results on some specific image datasets demonstrate an improvement over the original SAM.
GuideLLM: Exploring LLM-Guided Conversation with Applications in Autobiography Interviewing
Feb 10, 2025



Although Large Language Models (LLMs) succeed in human-guided conversations such as instruction following and question answering, the potential of LLM-guided conversations-where LLMs direct the discourse and steer the conversation's objectives-remains under-explored. In this study, we first characterize LLM-guided conversation into three fundamental components: (i) Goal Navigation; (ii) Context Management; (iii) Empathetic Engagement, and propose GuideLLM as an installation. We then implement an interviewing environment for the evaluation of LLM-guided conversation. Specifically, various topics are involved in this environment for comprehensive interviewing evaluation, resulting in around 1.4k turns of utterances, 184k tokens, and over 200 events mentioned during the interviewing for each chatbot evaluation. We compare GuideLLM with 6 state-of-the-art LLMs such as GPT-4o and Llama-3-70b-Instruct, from the perspective of interviewing quality, and autobiography generation quality. For automatic evaluation, we derive user proxies from multiple autobiographies and employ LLM-as-a-judge to score LLM behaviors. We further conduct a human-involved experiment by employing 45 human participants to chat with GuideLLM and baselines. We then collect human feedback, preferences, and ratings regarding the qualities of conversation and autobiography. Experimental results indicate that GuideLLM significantly outperforms baseline LLMs in automatic evaluation and achieves consistent leading performances in human ratings.
Dialogue is Better Than Monologue: Instructing Medical LLMs via Strategical Conversations
Jan 29, 2025Current medical AI systems often fail to replicate real-world clinical reasoning, as they are predominantly trained and evaluated on static text and question-answer tasks. These tuning methods and benchmarks overlook critical aspects like evidence-based reasoning and handling distracting information. To bridge this gap, we introduce a novel benchmark that simulates real-world diagnostic scenarios, integrating noise and difficulty levels aligned with USMLE standards. Moreover, we explore dialogue-based fine-tuning, which transforms static datasets into conversational formats to better capture iterative reasoning processes. Experiments show that dialogue-tuned models outperform traditional methods, with improvements of $9.64\%$ in multi-round reasoning scenarios and $6.18\%$ in accuracy in a noisy environment. Our findings highlight dialogue tuning as a promising approach for advancing clinically aligned and robust medical AI systems.