 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Multi-Scale Hypergraph for High-Order Brain Connectivity Analysis
Jun 02, 2026Understanding complex interactions between brain regions is critical for early neurodegenerative disease classification such as Alzheimer's Disease (AD) and Parkinson's Disease (PD). While graph-based models are widely used to analyze brain networks, most existing approaches primarily focus on pairwise interactions between directly connected nodes, limiting their ability to capture higher-order dependencies across multiple regions. Although hypergraph-based methods have been proposed to model higher-order relations, many rely on predefined hyperedges or restrict learning to hyperedge weights, reducing flexibility and limiting their capacity to capture multi-resolution structural patterns. In this regard, we introduce an adaptive multi-scale hyperedge learning framework, i.e., MuHL, which constructs hierarchical node features and dynamically learns high-order interactions through continuous hyperedge construction over multi-resolution graph signals. Extensive experiments on multiple brain network benchmarks demonstrate that MuHL consistently improves disease classification performance across different stages, and further identifies key regions of interest (ROIs) and their group-wise interactions from the learned hyperedges that are associated with disease progression, highlighting its potential as a powerful tool for brain network analysis in neurodegenerative disorders.
Multi-Modal Graph Neural Network with Transformer-Guided Adaptive Diffusion for Preclinical Alzheimer Classification
Jun 02, 2026The graphical representation of the brain offers critical insights into diagnosing and prognosing neurodegenerative disease via relationships between regions of interest (ROIs). Despite recent emergence of various Graph Neural Networks (GNNs) to effectively capture the relational information, there remain inherent limitations in interpreting the brain networks. Specifically, convolutional approaches ineffectively aggregate information from distant neighborhoods, while attention-based methods exhibit deficiencies in capturing node-centric information, particularly in retaining critical characteristics from pivotal nodes. These shortcomings reveal challenges for identifying disease-specific variation from diverse features from different modalities. In this regard, we propose an integrated framework guiding diffusion process at each node by a downstream transformer where both short- and long-range properties of graphs are aggregated via diffusion-kernel and multi-head attention respectively. We demonstrate the superiority of our model by improving performance of pre-clinical Alzheimer's disease (AD) classification with various modalities. Also, our model adeptly identifies key ROIs that are closely associated with the preclinical stages of AD, marking a significant potential for early diagnosis and prevision of the disease.
Marrying Generative Model of Healthcare Events with Digital Twin of Social Determinants of Health for Disease Reasoning
May 10, 2026Despite the central role of sensor-derived measurements such as imaging traits and plasma biomarkers in biomedical research and clinical practice, existing generative models for disease prediction largely depend on event-level representations from hospital and registry data. Given the multi-factorial nature of human disease, the absence of explicit modeling of social determinants of health (SDoH), even in the limited form of ICD-coded proxies (chapters Z and V--Y in ICD-10), limits the capacity for personalized disease modeling and clinical decision support. To address this limitation, we propose a generative model with ICD-coded proxies of SDoH for \textit{in silico} modeling of disease reasoning, a conditioned latent diffusion framework that establishes the connection between multi-organ sensor data with tokenized healthcare events. Specifically, we introduce a novel geometric diffusion model to characterize the temporal evolution of complex data representation such as brain networks (region-to-region connectivity encoded in a graph), in parallel with diffusion models for tabular data from other organ systems. Together, we integrate the generative model with digitalized SDoH proxies (coined \modelname{}) for simulated intervention and reasoning of future disease trajectories. We conduct extensive experiments on the UK Biobank (UKB) dataset, which contains organ-specific imaging traits, including brain (44,834), heart (23,987), liver (28,722), and kidney (32,155), along with nearly 500k medical history sequences (age range: 25$\sim$89 years). Our \modelname{} achieves significant improvements over state-of-the-art human disease autoregressive models and imaging trait generative baselines.
GeoDynamics: A Geometric State-Space Neural Network for Understanding Brain Dynamics on Riemannian Manifolds
Jan 20, 2026State-space models (SSMs) have become a cornerstone for unraveling brain dynamics, revealing how latent neural states evolve over time and give rise to observed signals. By combining the flexibility of deep learning with the principled dynamical structure of SSMs, recent studies have achieved powerful fits to functional neuroimaging data. However, most existing approaches still view the brain as a set of loosely connected regions or impose oversimplified network priors, falling short of a truly holistic and self-organized dynamical system perspective. Brain functional connectivity (FC) at each time point naturally forms a symmetric positive definite (SPD) matrix, which resides on a curved Riemannian manifold rather than in Euclidean space. Capturing the trajectories of these SPD matrices is key to understanding how coordinated networks support cognition and behavior. To this end, we introduce GeoDynamics, a geometric state-space neural network that tracks latent brain-state trajectories directly on the high-dimensional SPD manifold. GeoDynamics embeds each connectivity matrix into a manifold-aware recurrent framework, learning smooth and geometry-respecting transitions that reveal task-driven state changes and early markers of Alzheimer's disease, Parkinson's disease, and autism. Beyond neuroscience, we validate GeoDynamics on human action recognition benchmarks (UTKinect, Florence, HDM05), demonstrating its scalability and robustness in modeling complex spatiotemporal dynamics across diverse domains.
De-Individualizing fMRI Signals via Mahalanobis Whitening and Bures Geometry
Nov 10, 2025Functional connectivity has been widely investigated to understand brain disease in clinical studies and imaging-based neuroscience, and analyzing changes in functional connectivity has proven to be valuable for understanding and computationally evaluating the effects on brain function caused by diseases or experimental stimuli. By using Mahalanobis data whitening prior to the use of dimensionality reduction algorithms, we are able to distill meaningful information from fMRI signals about subjects and the experimental stimuli used to prompt them. Furthermore, we offer an interpretation of Mahalanobis whitening as a two-stage de-individualization of data which is motivated by similarity as captured by the Bures distance, which is connected to quantum mechanics. These methods have potential to aid discoveries about the mechanisms that link brain function with cognition and behavior and may improve the accuracy and consistency of Alzheimer's diagnosis, especially in the preclinical stage of disease progression.
OCL: Ordinal Contrastive Learning for Imputating Features with Progressive Labels
Mar 03, 2025Accurately discriminating progressive stages of Alzheimer's Disease (AD) is crucial for early diagnosis and prevention. It often involves multiple imaging modalities to understand the complex pathology of AD, however, acquiring a complete set of images is challenging due to high cost and burden for subjects. In the end, missing data become inevitable which lead to limited sample-size and decrease in precision in downstream analyses. To tackle this challenge, we introduce a holistic imaging feature imputation method that enables to leverage diverse imaging features while retaining all subjects. The proposed method comprises two networks: 1) An encoder to extract modality-independent embeddings and 2) A decoder to reconstruct the original measures conditioned on their imaging modalities. The encoder includes a novel {\em ordinal contrastive loss}, which aligns samples in the embedding space according to the progression of AD. We also maximize modality-wise coherence of embeddings within each subject, in conjunction with domain adversarial training algorithms, to further enhance alignment between different imaging modalities. The proposed method promotes our holistic imaging feature imputation across various modalities in the shared embedding space. In the experiments, we show that our networks deliver favorable results for statistical analysis and classification against imputation baselines with Alzheimer's Disease Neuroimaging Initiative (ADNI) study.
Learning Covariance-Based Multi-Scale Representation of Neuroimaging Measures for Alzheimer Classification
Mar 03, 2025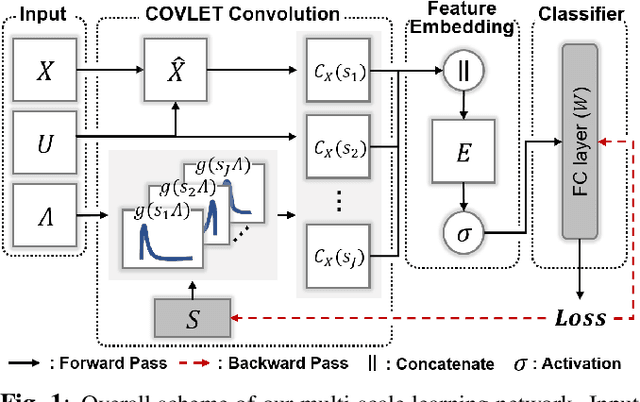
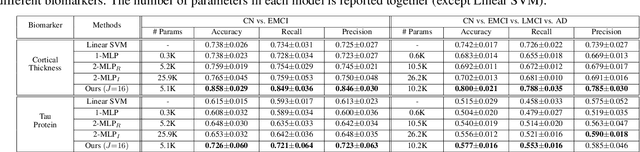

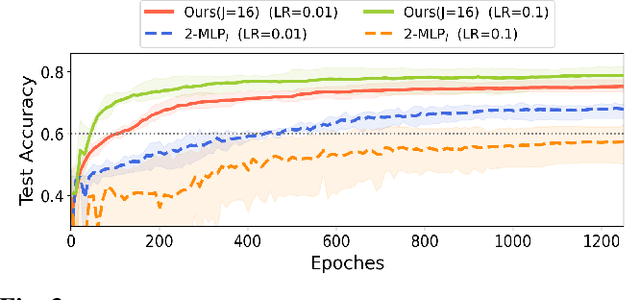
Stacking excessive layers in DNN results in highly underdetermined system when training samples are limited, which is very common in medical applications. In this regard, we present a framework capable of deriving an efficient high-dimensional space with reasonable increase in model size. This is done by utilizing a transform (i.e., convolution) that leverages scale-space theory with covariance structure. The overall model trains on this transform together with a downstream classifier (i.e., Fully Connected layer) to capture the optimal multi-scale representation of the original data which corresponds to task-specific components in a dual space. Experiments on neuroimaging measures from Alzheimer's Disease Neuroimaging Initiative (ADNI) study show that our model performs better and converges faster than conventional models even when the model size is significantly reduced. The trained model is made interpretable using gradient information over the multi-scale transform to delineate personalized AD-specific regions in the brain.
Modality-Agnostic Style Transfer for Holistic Feature Imputation
Mar 03, 2025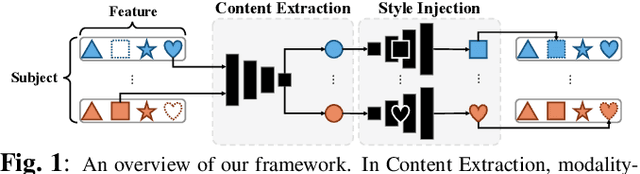
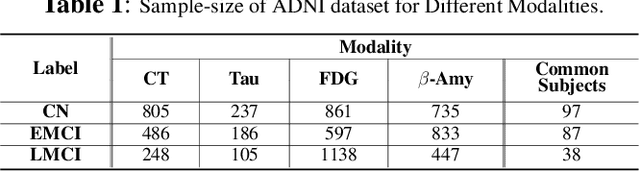
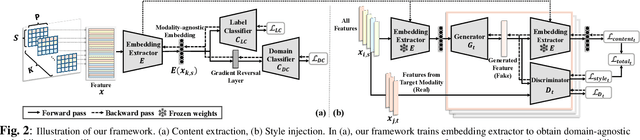
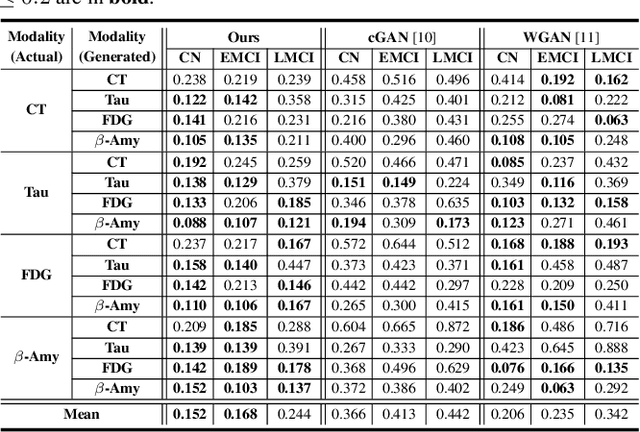
Characterizing a preclinical stage of Alzheimer's Disease (AD) via single imaging is difficult as its early symptoms are quite subtle. Therefore, many neuroimaging studies are curated with various imaging modalities, e.g., MRI and PET, however, it is often challenging to acquire all of them from all subjects and missing data become inevitable. In this regards, in this paper, we propose a framework that generates unobserved imaging measures for specific subjects using their existing measures, thereby reducing the need for additional examinations. Our framework transfers modality-specific style while preserving AD-specific content. This is done by domain adversarial training that preserves modality-agnostic but AD-specific information, while a generative adversarial network adds an indistinguishable modality-specific style. Our proposed framework is evaluated on the Alzheimer's Disease Neuroimaging Initiative (ADNI) study and compared with other imputation methods in terms of generated data quality. Small average Cohen's $d$ $< 0.19$ between our generated measures and real ones suggests that the synthetic data are practically usable regardless of their modality type.
BrainMAP: Learning Multiple Activation Pathways in Brain Networks
Dec 23, 2024Functional Magnetic Resonance Image (fMRI) is commonly employed to study human brain activity, since it offers insight into the relationship between functional fluctuations and human behavior. To enhance analysis and comprehension of brain activity, Graph Neural Networks (GNNs) have been widely applied to the analysis of functional connectivities (FC) derived from fMRI data, due to their ability to capture the synergistic interactions among brain regions. However, in the human brain, performing complex tasks typically involves the activation of certain pathways, which could be represented as paths across graphs. As such, conventional GNNs struggle to learn from these pathways due to the long-range dependencies of multiple pathways. To address these challenges, we introduce a novel framework BrainMAP to learn Multiple Activation Pathways in Brain networks. BrainMAP leverages sequential models to identify long-range correlations among sequentialized brain regions and incorporates an aggregation module based on Mixture of Experts (MoE) to learn from multiple pathways. Our comprehensive experiments highlight BrainMAP's superior performance. Furthermore, our framework enables explanatory analyses of crucial brain regions involved in tasks. Our code is provided at https://github.com/LzyFischer/Graph-Mamba.
NeuroPath: A Neural Pathway Transformer for Joining the Dots of Human Connectomes
Sep 26, 2024
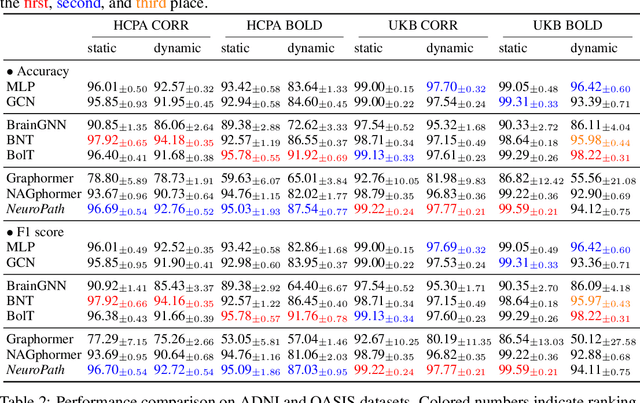

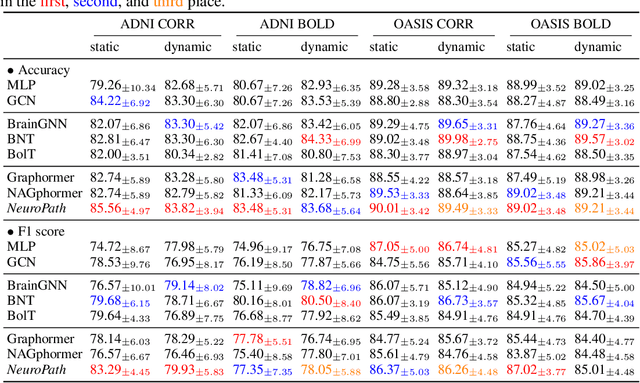
Although modern imaging technologies allow us to study connectivity between two distinct brain regions in-vivo, an in-depth understanding of how anatomical structure supports brain function and how spontaneous functional fluctuations emerge remarkable cognition is still elusive. Meanwhile, tremendous efforts have been made in the realm of machine learning to establish the nonlinear mapping between neuroimaging data and phenotypic traits. However, the absence of neuroscience insight in the current approaches poses significant challenges in understanding cognitive behavior from transient neural activities. To address this challenge, we put the spotlight on the coupling mechanism of structural connectivity (SC) and functional connectivity (FC) by formulating such network neuroscience question into an expressive graph representation learning problem for high-order topology. Specifically, we introduce the concept of topological detour to characterize how a ubiquitous instance of FC (direct link) is supported by neural pathways (detour) physically wired by SC, which forms a cyclic loop interacted by brain structure and function. In the clich\'e of machine learning, the multi-hop detour pathway underlying SC-FC coupling allows us to devise a novel multi-head self-attention mechanism within Transformer to capture multi-modal feature representation from paired graphs of SC and FC. Taken together, we propose a biological-inspired deep model, coined as NeuroPath, to find putative connectomic feature representations from the unprecedented amount of neuroimages, which can be plugged into various downstream applications such as task recognition and disease diagnosis. We have evaluated NeuroPath on large-scale public datasets including HCP and UK Biobank under supervised and zero-shot learning, where the state-of-the-art performance by our NeuroPath indicates great potential in network neuroscience.