 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering Latent Communication Patterns in Brain Networks via Adaptive Flow Routing
Jan 31, 2026Unraveling how macroscopic cognitive phenotypes emerge from microscopic neuronal connectivity remains one of the core pursuits of neuroscience. To this end, researchers typically leverage multi-modal information from structural connectivity (SC) and functional connectivity (FC) to complete downstream tasks. Recent methodologies explore the intricate coupling mechanisms between SC and FC, attempting to fuse their representations at the regional level. However, lacking fundamental neuroscientific insight, these approaches fail to uncover the latent interactions between neural regions underlying these connectomes, and thus cannot explain why SC and FC exhibit dynamic states of both coupling and heterogeneity. In this paper, we formulate multi-modal fusion through the lens of neural communication dynamics and propose the Adaptive Flow Routing Network (AFR-Net), a physics-informed framework that models how structural constraints (SC) give rise to functional communication patterns (FC), enabling interpretable discovery of critical neural pathways. Extensive experiments demonstrate that AFR-Net significantly outperforms state-of-the-art baselines. The code is available at https://anonymous.4open.science/r/DIAL-F0D1.
MoCo: A One-Stop Shop for Model Collaboration Research
Jan 29, 2026Advancing beyond single monolithic language models (LMs), recent research increasingly recognizes the importance of model collaboration, where multiple LMs collaborate, compose, and complement each other. Existing research on this topic has mostly been disparate and disconnected, from different research communities, and lacks rigorous comparison. To consolidate existing research and establish model collaboration as a school of thought, we present MoCo: a one-stop Python library of executing, benchmarking, and comparing model collaboration algorithms at scale. MoCo features 26 model collaboration methods, spanning diverse levels of cross-model information exchange such as routing, text, logit, and model parameters. MoCo integrates 25 evaluation datasets spanning reasoning, QA, code, safety, and more, while users could flexibly bring their own data. Extensive experiments with MoCo demonstrate that most collaboration strategies outperform models without collaboration in 61.0% of (model, data) settings on average, with the most effective methods outperforming by up to 25.8%. We further analyze the scaling of model collaboration strategies, the training/inference efficiency of diverse methods, highlight that the collaborative system solves problems where single LMs struggle, and discuss future work in model collaboration, all made possible by MoCo. We envision MoCo as a valuable toolkit to facilitate and turbocharge the quest for an open, modular, decentralized, and collaborative AI future.
MolEdit: Knowledge Editing for Multimodal Molecule Language Models
Nov 16, 2025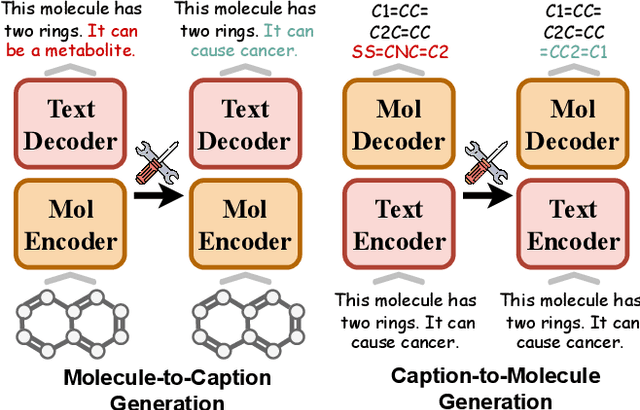
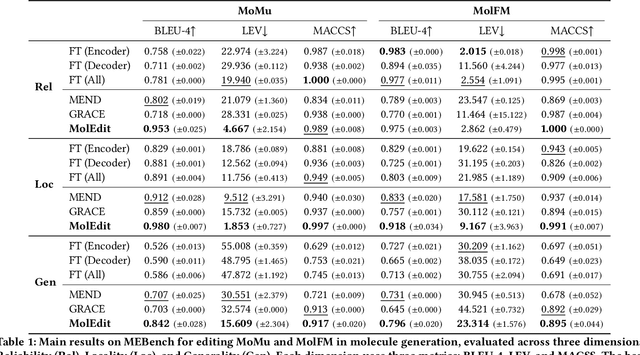

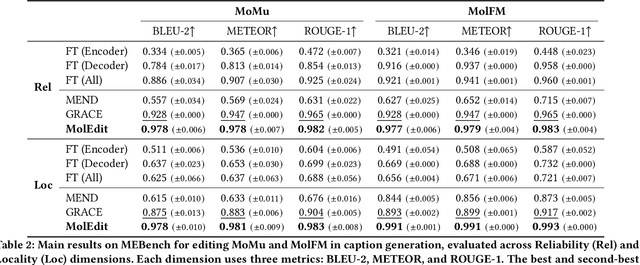
Understanding and continuously refining multimodal molecular knowledge is crucial for advancing biomedicine, chemistry, and materials science. Molecule language models (MoLMs) have become powerful tools in these domains, integrating structural representations (e.g., SMILES strings, molecular graphs) with rich contextual descriptions (e.g., physicochemical properties). However, MoLMs can encode and propagate inaccuracies due to outdated web-mined training corpora or malicious manipulation, jeopardizing downstream discovery pipelines. While knowledge editing has been explored for general-domain AI, its application to MoLMs remains uncharted, presenting unique challenges due to the multifaceted and interdependent nature of molecular knowledge. In this paper, we take the first step toward MoLM editing for two critical tasks: molecule-to-caption generation and caption-to-molecule generation. To address molecule-specific challenges, we propose MolEdit, a powerful framework that enables targeted modifications while preserving unrelated molecular knowledge. MolEdit combines a Multi-Expert Knowledge Adapter that routes edits to specialized experts for different molecular facets with an Expertise-Aware Editing Switcher that activates the adapters only when input closely matches the stored edits across all expertise, minimizing interference with unrelated knowledge. To systematically evaluate editing performance, we introduce MEBench, a comprehensive benchmark assessing multiple dimensions, including Reliability (accuracy of the editing), Locality (preservation of irrelevant knowledge), and Generality (robustness to reformed queries). Across extensive experiments on two popular MoLM backbones, MolEdit delivers up to 18.8% higher Reliability and 12.0% better Locality than baselines while maintaining efficiency. The code is available at: https://github.com/LzyFischer/MolEdit.
GraphTOP: Graph Topology-Oriented Prompting for Graph Neural Networks
Oct 25, 2025Graph Neural Networks (GNNs) have revolutionized the field of graph learning by learning expressive graph representations from massive graph data. As a common pattern to train powerful GNNs, the "pre-training, adaptation" scheme first pre-trains GNNs over unlabeled graph data and subsequently adapts them to specific downstream tasks. In the adaptation phase, graph prompting is an effective strategy that modifies input graph data with learnable prompts while keeping pre-trained GNN models frozen. Typically, existing graph prompting studies mainly focus on *feature-oriented* methods that apply graph prompts to node features or hidden representations. However, these studies often achieve suboptimal performance, as they consistently overlook the potential of *topology-oriented* prompting, which adapts pre-trained GNNs by modifying the graph topology. In this study, we conduct a pioneering investigation of graph prompting in terms of graph topology. We propose the first **Graph** **T**opology-**O**riented **P**rompting (GraphTOP) framework to effectively adapt pre-trained GNN models for downstream tasks. More specifically, we reformulate topology-oriented prompting as an edge rewiring problem within multi-hop local subgraphs and relax it into the continuous probability space through reparameterization while ensuring tight relaxation and preserving graph sparsity. Extensive experiments on five graph datasets under four pre-training strategies demonstrate that our proposed GraphTOP outshines six baselines on multiple node classification datasets. Our code is available at https://github.com/xbfu/GraphTOP.
Learning from Diverse Reasoning Paths with Routing and Collaboration
Aug 23, 2025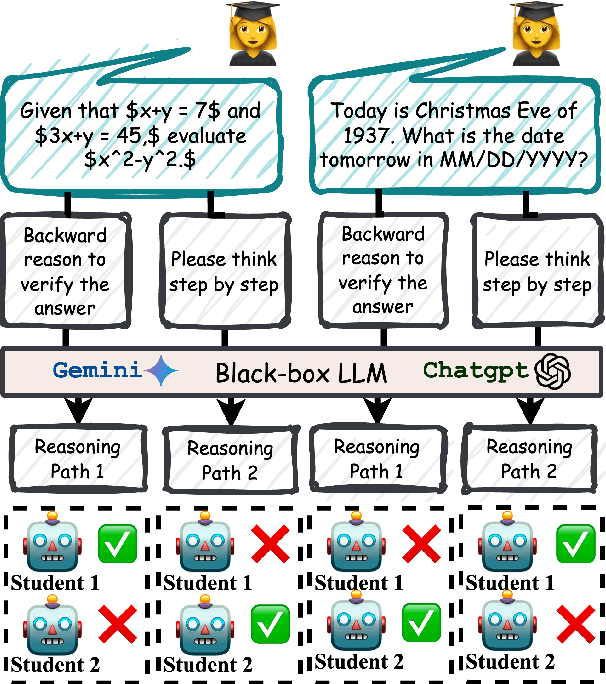
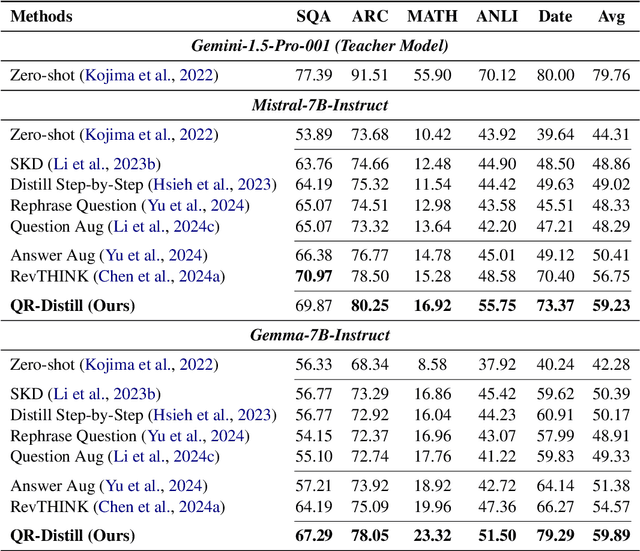
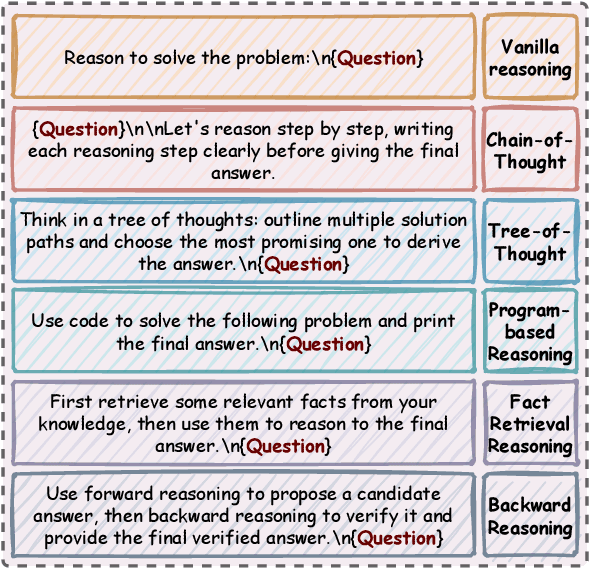
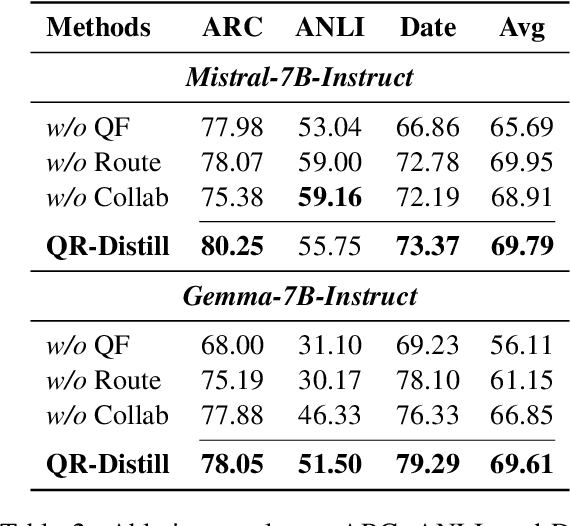
Advances in large language models (LLMs) significantly enhance reasoning capabilities but their deployment is restricted in resource-constrained scenarios. Knowledge distillation addresses this by transferring knowledge from powerful teacher models to compact and transparent students. However, effectively capturing the teacher's comprehensive reasoning is challenging due to conventional token-level supervision's limited scope. Using multiple reasoning paths per query alleviates this problem, but treating each path identically is suboptimal as paths vary widely in quality and suitability across tasks and models. We propose Quality-filtered Routing with Cooperative Distillation (QR-Distill), combining path quality filtering, conditional routing, and cooperative peer teaching. First, quality filtering retains only correct reasoning paths scored by an LLM-based evaluation. Second, conditional routing dynamically assigns paths tailored to each student's current learning state. Finally, cooperative peer teaching enables students to mutually distill diverse insights, addressing knowledge gaps and biases toward specific reasoning styles. Experiments demonstrate QR-Distill's superiority over traditional single- and multi-path distillation methods. Ablation studies further highlight the importance of each component including quality filtering, conditional routing, and peer teaching in effective knowledge transfer. Our code is available at https://github.com/LzyFischer/Distill.
Graph Prompting for Graph Learning Models: Recent Advances and Future Directions
Jun 10, 2025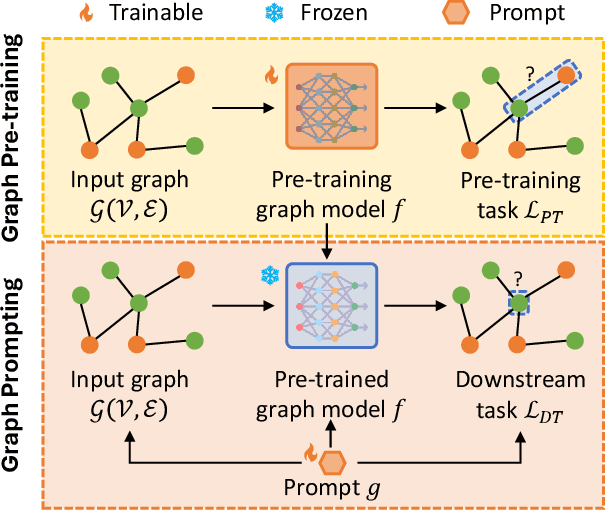
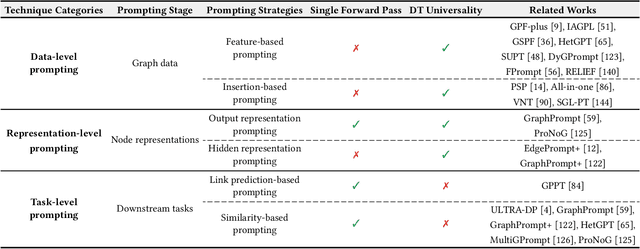
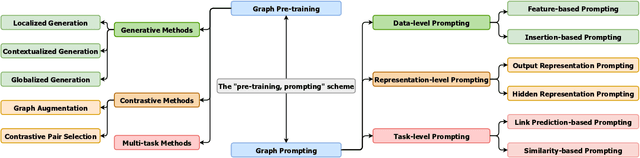
Graph learning models have demonstrated great prowess in learning expressive representations from large-scale graph data in a wide variety of real-world scenarios. As a prevalent strategy for training powerful graph learning models, the "pre-training, adaptation" scheme first pre-trains graph learning models on unlabeled graph data in a self-supervised manner and then adapts them to specific downstream tasks. During the adaptation phase, graph prompting emerges as a promising approach that learns trainable prompts while keeping the pre-trained graph learning models unchanged. In this paper, we present a systematic review of recent advancements in graph prompting. First, we introduce representative graph pre-training methods that serve as the foundation step of graph prompting. Next, we review mainstream techniques in graph prompting and elaborate on how they design learnable prompts for graph prompting. Furthermore, we summarize the real-world applications of graph prompting from different domains. Finally, we discuss several open challenges in existing studies with promising future directions in this field.
A Survey of Scaling in Large Language Model Reasoning
Apr 02, 2025The rapid advancements in large Language models (LLMs) have significantly enhanced their reasoning capabilities, driven by various strategies such as multi-agent collaboration. However, unlike the well-established performance improvements achieved through scaling data and model size, the scaling of reasoning in LLMs is more complex and can even negatively impact reasoning performance, introducing new challenges in model alignment and robustness. In this survey, we provide a comprehensive examination of scaling in LLM reasoning, categorizing it into multiple dimensions and analyzing how and to what extent different scaling strategies contribute to improving reasoning capabilities. We begin by exploring scaling in input size, which enables LLMs to process and utilize more extensive context for improved reasoning. Next, we analyze scaling in reasoning steps that improves multi-step inference and logical consistency. We then examine scaling in reasoning rounds, where iterative interactions refine reasoning outcomes. Furthermore, we discuss scaling in training-enabled reasoning, focusing on optimization through iterative model improvement. Finally, we review applications of scaling across domains and outline future directions for further advancing LLM reasoning. By synthesizing these diverse perspectives, this survey aims to provide insights into how scaling strategies fundamentally enhance the reasoning capabilities of LLMs and further guide the development of next-generation AI systems.
Harnessing Large Language Models for Disaster Management: A Survey
Jan 12, 2025



Large language models (LLMs) have revolutionized scientific research with their exceptional capabilities and transformed various fields. Among their practical applications, LLMs have been playing a crucial role in mitigating threats to human life, infrastructure, and the environment. Despite growing research in disaster LLMs, there remains a lack of systematic review and in-depth analysis of LLMs for natural disaster management. To address the gap, this paper presents a comprehensive survey of existing LLMs in natural disaster management, along with a taxonomy that categorizes existing works based on disaster phases and application scenarios. By collecting public datasets and identifying key challenges and opportunities, this study aims to guide the professional community in developing advanced LLMs for disaster management to enhance the resilience against natural disasters.
BrainMAP: Learning Multiple Activation Pathways in Brain Networks
Dec 23, 2024Functional Magnetic Resonance Image (fMRI) is commonly employed to study human brain activity, since it offers insight into the relationship between functional fluctuations and human behavior. To enhance analysis and comprehension of brain activity, Graph Neural Networks (GNNs) have been widely applied to the analysis of functional connectivities (FC) derived from fMRI data, due to their ability to capture the synergistic interactions among brain regions. However, in the human brain, performing complex tasks typically involves the activation of certain pathways, which could be represented as paths across graphs. As such, conventional GNNs struggle to learn from these pathways due to the long-range dependencies of multiple pathways. To address these challenges, we introduce a novel framework BrainMAP to learn Multiple Activation Pathways in Brain networks. BrainMAP leverages sequential models to identify long-range correlations among sequentialized brain regions and incorporates an aggregation module based on Mixture of Experts (MoE) to learn from multiple pathways. Our comprehensive experiments highlight BrainMAP's superior performance. Furthermore, our framework enables explanatory analyses of crucial brain regions involved in tasks. Our code is provided at https://github.com/LzyFischer/Graph-Mamba.
ST-FiT: Inductive Spatial-Temporal Forecasting with Limited Training Data
Dec 17, 2024Spatial-temporal graphs are widely used in a variety of real-world applications. Spatial-Temporal Graph Neural Networks (STGNNs) have emerged as a powerful tool to extract meaningful insights from this data. However, in real-world applications, most nodes may not possess any available temporal data during training. For example, the pandemic dynamics of most cities on a geographical graph may not be available due to the asynchronous nature of outbreaks. Such a phenomenon disagrees with the training requirements of most existing spatial-temporal forecasting methods, which jeopardizes their effectiveness and thus blocks broader deployment. In this paper, we propose to formulate a novel problem of inductive forecasting with limited training data. In particular, given a spatial-temporal graph, we aim to learn a spatial-temporal forecasting model that can be easily generalized onto those nodes without any available temporal training data. To handle this problem, we propose a principled framework named ST-FiT. ST-FiT consists of two key learning components: temporal data augmentation and spatial graph topology learning. With such a design, ST-FiT can be used on top of any existing STGNNs to achieve superior performance on the nodes without training data. Extensive experiments verify the effectiveness of ST-FiT in multiple key perspectives.