 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoCo: A One-Stop Shop for Model Collaboration Research
Jan 29, 2026Advancing beyond single monolithic language models (LMs), recent research increasingly recognizes the importance of model collaboration, where multiple LMs collaborate, compose, and complement each other. Existing research on this topic has mostly been disparate and disconnected, from different research communities, and lacks rigorous comparison. To consolidate existing research and establish model collaboration as a school of thought, we present MoCo: a one-stop Python library of executing, benchmarking, and comparing model collaboration algorithms at scale. MoCo features 26 model collaboration methods, spanning diverse levels of cross-model information exchange such as routing, text, logit, and model parameters. MoCo integrates 25 evaluation datasets spanning reasoning, QA, code, safety, and more, while users could flexibly bring their own data. Extensive experiments with MoCo demonstrate that most collaboration strategies outperform models without collaboration in 61.0% of (model, data) settings on average, with the most effective methods outperforming by up to 25.8%. We further analyze the scaling of model collaboration strategies, the training/inference efficiency of diverse methods, highlight that the collaborative system solves problems where single LMs struggle, and discuss future work in model collaboration, all made possible by MoCo. We envision MoCo as a valuable toolkit to facilitate and turbocharge the quest for an open, modular, decentralized, and collaborative AI future.
Agentic Conversational Search with Contextualized Reasoning via Reinforcement Learning
Jan 19, 2026Large Language Models (LLMs) have become a popular interface for human-AI interaction, supporting information seeking and task assistance through natural, multi-turn dialogue. To respond to users within multi-turn dialogues, the context-dependent user intent evolves across interactions, requiring contextual interpretation, query reformulation, and dynamic coordination between retrieval and generation. Existing studies usually follow static rewrite, retrieve, and generate pipelines, which optimize different procedures separately and overlook the mixed-initiative action optimization simultaneously. Although the recent developments in deep search agents demonstrate the effectiveness in jointly optimizing retrieval and generation via reasoning, these approaches focus on single-turn scenarios, which might lack the ability to handle multi-turn interactions. We introduce a conversational agent that interleaves search and reasoning across turns, enabling exploratory and adaptive behaviors learned through reinforcement learning (RL) training with tailored rewards towards evolving user goals. The experimental results across four widely used conversational benchmarks demonstrate the effectiveness of our methods by surpassing several existing strong baselines.
MTMCS-Bench: Evaluating Contextual Safety of Multimodal Large Language Models in Multi-Turn Dialogues
Jan 11, 2026Multimodal large language models (MLLMs) are increasingly deployed as assistants that interact through text and images, making it crucial to evaluate contextual safety when risk depends on both the visual scene and the evolving dialogue. Existing contextual safety benchmarks are mostly single-turn and often miss how malicious intent can emerge gradually or how the same scene can support both benign and exploitative goals. We introduce the Multi-Turn Multimodal Contextual Safety Benchmark (MTMCS-Bench), a benchmark of realistic images and multi-turn conversations that evaluates contextual safety in MLLMs under two complementary settings, escalation-based risk and context-switch risk. MTMCS-Bench offers paired safe and unsafe dialogues with structured evaluation. It contains over 30 thousand multimodal (image+text) and unimodal (text-only) samples, with metrics that separately measure contextual intent recognition, safety-awareness on unsafe cases, and helpfulness on benign ones. Across eight open-source and seven proprietary MLLMs, we observe persistent trade-offs between contextual safety and utility, with models tending to either miss gradual risks or over-refuse benign dialogues. Finally, we evaluate five current guardrails and find that they mitigate some failures but do not fully resolve multi-turn contextual risks.
Adaptive Personalized Conversational Information Retrieval
Aug 12, 2025Personalized conversational information retrieval (CIR) systems aim to satisfy users' complex information needs through multi-turn interactions by considering user profiles. However, not all search queries require personalization. The challenge lies in appropriately incorporating personalization elements into search when needed. Most existing studies implicitly incorporate users' personal information and conversational context using large language models without distinguishing the specific requirements for each query turn. Such a ``one-size-fits-all'' personalization strategy might lead to sub-optimal results. In this paper, we propose an adaptive personalization method, in which we first identify the required personalization level for a query and integrate personalized queries with other query reformulations to produce various enhanced queries. Then, we design a personalization-aware ranking fusion approach to assign fusion weights dynamically to different reformulated queries, depending on the required personalization level. The proposed adaptive personalized conversational information retrieval framework APCIR is evaluated on two TREC iKAT datasets. The results confirm the effectiveness of adaptive personalization of APCIR by outperforming state-of-the-art methods.
Aligning Large Language Models with Implicit Preferences from User-Generated Content
Jun 04, 2025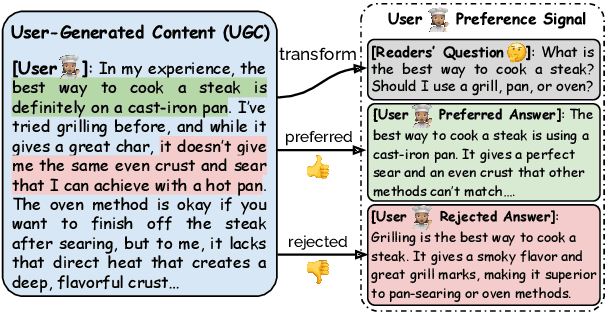
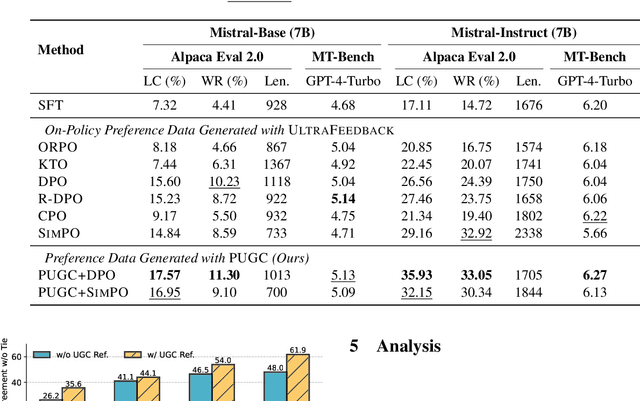
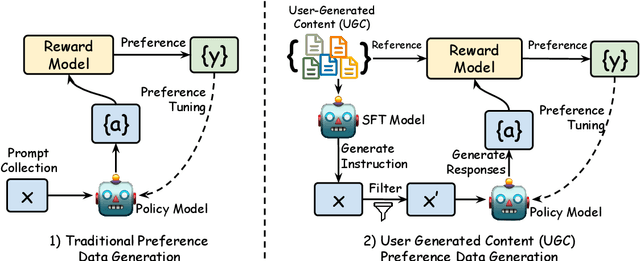

Learning from preference feedback is essential for aligning large language models (LLMs) with human values and improving the quality of generated responses. However, existing preference learning methods rely heavily on curated data from humans or advanced LLMs, which is costly and difficult to scale. In this work, we present PUGC, a novel framework that leverages implicit human Preferences in unlabeled User-Generated Content (UGC) to generate preference data. Although UGC is not explicitly created to guide LLMs in generating human-preferred responses, it often reflects valuable insights and implicit preferences from its creators that has the potential to address readers' questions. PUGC transforms UGC into user queries and generates responses from the policy model. The UGC is then leveraged as a reference text for response scoring, aligning the model with these implicit preferences. This approach improves the quality of preference data while enabling scalable, domain-specific alignment. Experimental results on Alpaca Eval 2 show that models trained with DPO and PUGC achieve a 9.37% performance improvement over traditional methods, setting a 35.93% state-of-the-art length-controlled win rate using Mistral-7B-Instruct. Further studies highlight gains in reward quality, domain-specific alignment effectiveness, robustness against UGC quality, and theory of mind capabilities. Our code and dataset are available at https://zhaoxuan.info/PUGC.github.io/
Modality-Aware Neuron Pruning for Unlearning in Multimodal Large Language Models
Feb 21, 2025Generative models such as Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) trained on massive datasets can lead them to memorize and inadvertently reveal sensitive information, raising ethical and privacy concerns. While some prior works have explored this issue in the context of LLMs, it presents a unique challenge for MLLMs due to the entangled nature of knowledge across modalities, making comprehensive unlearning more difficult. To address this challenge, we propose Modality Aware Neuron Unlearning (MANU), a novel unlearning framework for MLLMs designed to selectively clip neurons based on their relative importance to the targeted forget data, curated for different modalities. Specifically, MANU consists of two stages: important neuron selection and selective pruning. The first stage identifies and collects the most influential neurons across modalities relative to the targeted forget knowledge, while the second stage is dedicated to pruning those selected neurons. MANU effectively isolates and removes the neurons that contribute most to the forget data within each modality, while preserving the integrity of retained knowledge. Our experiments conducted across various MLLM architectures illustrate that MANU can achieve a more balanced and comprehensive unlearning in each modality without largely affecting the overall model utility.
IHEval: Evaluating Language Models on Following the Instruction Hierarchy
Feb 12, 2025The instruction hierarchy, which establishes a priority order from system messages to user messages, conversation history, and tool outputs, is essential for ensuring consistent and safe behavior in language models (LMs). Despite its importance, this topic receives limited attention, and there is a lack of comprehensive benchmarks for evaluating models' ability to follow the instruction hierarchy. We bridge this gap by introducing IHEval, a novel benchmark comprising 3,538 examples across nine tasks, covering cases where instructions in different priorities either align or conflict. Our evaluation of popular LMs highlights their struggle to recognize instruction priorities. All evaluated models experience a sharp performance decline when facing conflicting instructions, compared to their original instruction-following performance. Moreover, the most competitive open-source model only achieves 48% accuracy in resolving such conflicts. Our results underscore the need for targeted optimization in the future development of LMs.
Protecting Privacy in Multimodal Large Language Models with MLLMU-Bench
Oct 29, 2024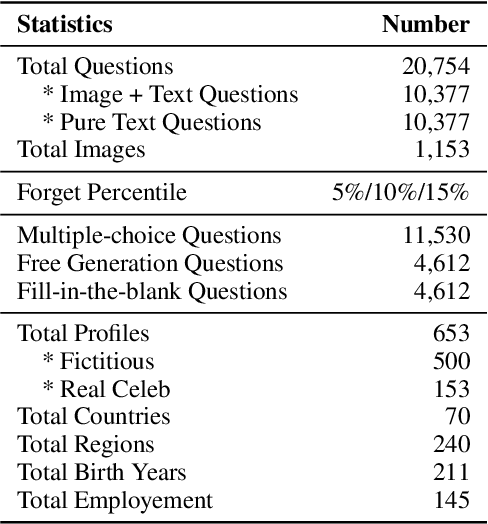
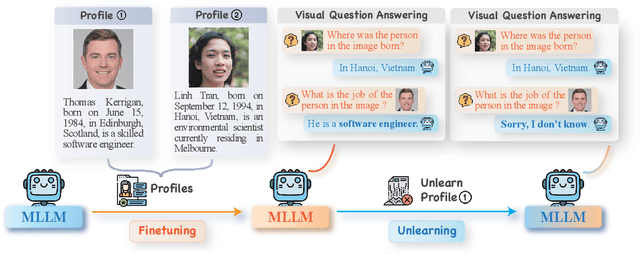

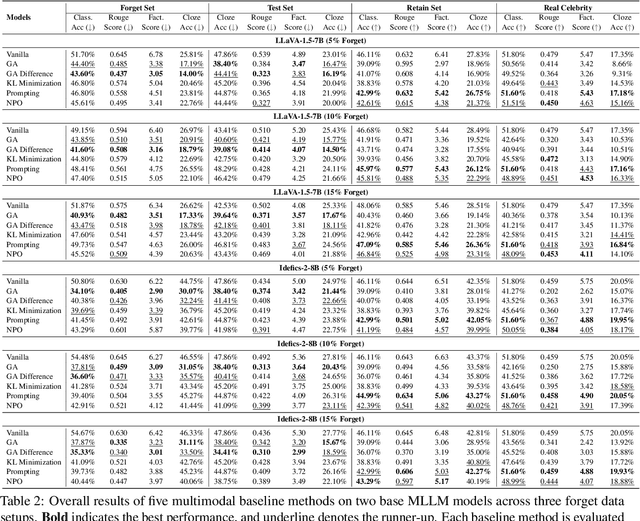
Generative models such as Large Language Models (LLM) and Multimodal Large Language models (MLLMs) trained on massive web corpora can memorize and disclose individuals' confidential and private data, raising legal and ethical concerns. While many previous works have addressed this issue in LLM via machine unlearning, it remains largely unexplored for MLLMs. To tackle this challenge, we introduce Multimodal Large Language Model Unlearning Benchmark (MLLMU-Bench), a novel benchmark aimed at advancing the understanding of multimodal machine unlearning. MLLMU-Bench consists of 500 fictitious profiles and 153 profiles for public celebrities, each profile feature over 14 customized question-answer pairs, evaluated from both multimodal (image+text) and unimodal (text) perspectives. The benchmark is divided into four sets to assess unlearning algorithms in terms of efficacy, generalizability, and model utility. Finally, we provide baseline results using existing generative model unlearning algorithms. Surprisingly, our experiments show that unimodal unlearning algorithms excel in generation and cloze tasks, while multimodal unlearning approaches perform better in classification tasks with multimodal inputs.
Enhancing Mathematical Reasoning in LLMs by Stepwise Correction
Oct 16, 2024



Best-of-N decoding methods instruct large language models (LLMs) to generate multiple solutions, score each using a scoring function, and select the highest scored as the final answer to mathematical reasoning problems. However, this repeated independent process often leads to the same mistakes, making the selected solution still incorrect. We propose a novel prompting method named Stepwise Correction (StepCo) that helps LLMs identify and revise incorrect steps in their generated reasoning paths. It iterates verification and revision phases that employ a process-supervised verifier. The verify-then-revise process not only improves answer correctness but also reduces token consumption with fewer paths needed to generate. With StepCo, a series of LLMs demonstrate exceptional performance. Notably, using GPT-4o as the backend LLM, StepCo achieves an average accuracy of 94.1 across eight datasets, significantly outperforming the state-of-the-art Best-of-N method by +2.4, while reducing token consumption by 77.8%.
CodeTaxo: Enhancing Taxonomy Expansion with Limited Examples via Code Language Prompts
Aug 17, 2024



Taxonomies play a crucial role in various applications by providing a structural representation of knowledge. The task of taxonomy expansion involves integrating emerging concepts into existing taxonomies by identifying appropriate parent concepts for these new query concepts. Previous approaches typically relied on self-supervised methods that generate annotation data from existing taxonomies. However, these methods are less effective when the existing taxonomy is small (fewer than 100 entities). In this work, we introduce \textsc{CodeTaxo}, a novel approach that leverages large language models through code language prompts to capture the taxonomic structure. Extensive experiments on five real-world benchmarks from different domains demonstrate that \textsc{CodeTaxo} consistently achieves superior performance across all evaluation metrics, significantly outperforming previous state-of-the-art methods. The code and data are available at \url{https://github.com/QingkaiZeng/CodeTaxo-Pub}.