 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMosaicQuant: Inlier-Outlier Disaggregation for Unified 4-Bit LLM Quantization
Jun 14, 20264-bit quantization significantly reduces the memory footprint and accelerates the inference of large language models (LLMs). However, its limited bit-width representation struggles to faithfully capture both dense common values (\emph{inliers}) and rare large-magnitude values (\emph{outliers}), causing substantial accuracy degradation. Existing mixed-precision methods mitigate this by retaining outliers in high precision, but at the cost of breaking the uniformity of low-bit execution, introducing precision conversion and extra data movement that undermine practical speedup. We propose \textbf{MosaicQuant}, a unified 4-bit LLM quantization paradigm built on a novel principle of \emph{inlier--outlier disaggregation}. Rather than elevating outlier precision, MosaicQuant quantizes the full weight matrix into a dense 4-bit base component, where inliers are captured faithfully while outlier are inevitably quantized. A sparse 4-bit residual component is then introduced to compensate for these quantization errors, selectively targeting the most error-critical weight blocks where output distortion is shown to be concentrated. However, a unified representation alone is insufficient, as naïvely executing the sparse residual as a separate kernel still breaks the unified low-bit inference pipeline. To bridge this gap, we introduce \textbf{ZipperEngine}, which fuses sparse block computation into the dense 4-bit GEMM kernel via an overlapped pipeline, unifying not only the representation but also the execution into a single coherent low-bit inference pipeline. Extensive experiments on LLaMA3 and Qwen3 demonstrate that MosaicQuant preserves near-FP16 accuracy while achieving up to $1.24\times$ speedup over the W16A16 baseline.
GS-NFS: Bandwidth-adaptive Streaming of Dynamic Gaussian Splats and Point Clouds
Jun 04, 2026Dynamic 3D Gaussian Splatting (3DGS) holds great promise as a 3D video streaming technology since it can represent complex 3D scenes with high fidelity. In this approach, every frame in a 3D video represents the environment as a collection of Gaussians with position and other attributes such as scale, rotation, opacity, and color. Frames capture fine details, permit views from any arbitrary perspective, but are an order of magnitude, or more, larger than 2D video frames. A line of recent work has explored how to compress dynamic 3DGS frames, but these approaches are often slow, in part because their compression techniques are not amenable to efficient acceleration. GS-NFS accelerates dynamic 3DGS compression and decompression on a GPU, to the point where it can encode and decode at full frame rate. It achieves this by developing novel GPU-based parallelizations of existing algorithms for encoding both positions and attributes of Gaussians. As a result, it is 1-2 orders of magnitude faster than the state-of-the-art in encoding and decoding a frame, while offering competitive compression performance and rendering quality.
MVGGT: Multimodal Visual Geometry Grounded Transformer for Multiview 3D Referring Expression Segmentation
Jan 13, 2026Most existing 3D referring expression segmentation (3DRES) methods rely on dense, high-quality point clouds, while real-world agents such as robots and mobile phones operate with only a few sparse RGB views and strict latency constraints. We introduce Multi-view 3D Referring Expression Segmentation (MV-3DRES), where the model must recover scene structure and segment the referred object directly from sparse multi-view images. Traditional two-stage pipelines, which first reconstruct a point cloud and then perform segmentation, often yield low-quality geometry, produce coarse or degraded target regions, and run slowly. We propose the Multimodal Visual Geometry Grounded Transformer (MVGGT), an efficient end-to-end framework that integrates language information into sparse-view geometric reasoning through a dual-branch design. Training in this setting exposes a critical optimization barrier, termed Foreground Gradient Dilution (FGD), where sparse 3D signals lead to weak supervision. To resolve this, we introduce Per-view No-target Suppression Optimization (PVSO), which provides stronger and more balanced gradients across views, enabling stable and efficient learning. To support consistent evaluation, we build MVRefer, a benchmark that defines standardized settings and metrics for MV-3DRES. Experiments show that MVGGT establishes the first strong baseline and achieves both high accuracy and fast inference, outperforming existing alternatives. Code and models are publicly available at https://mvggt.github.io.
SOMA: Feature Gradient Enhanced Affine-Flow Matching for SAR-Optical Registration
Nov 17, 2025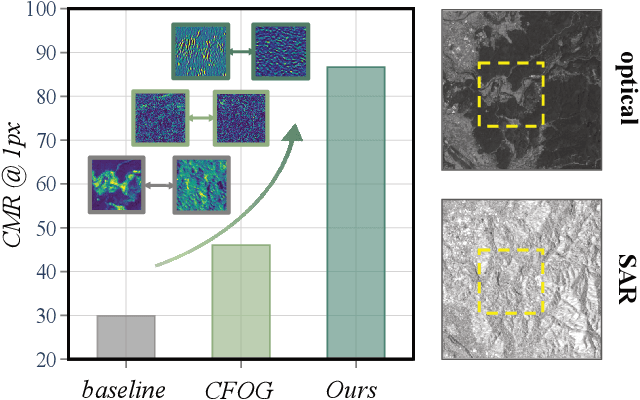
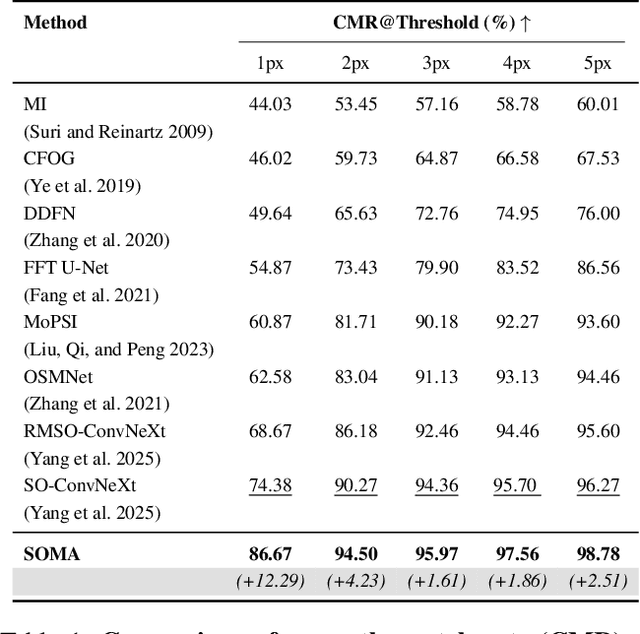
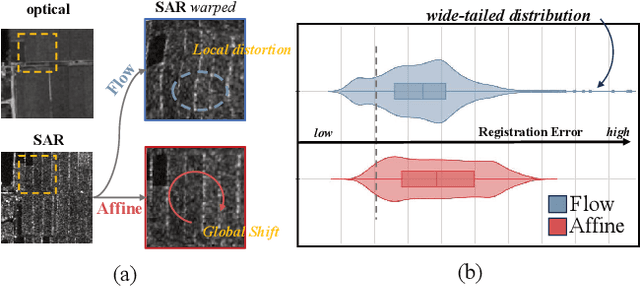
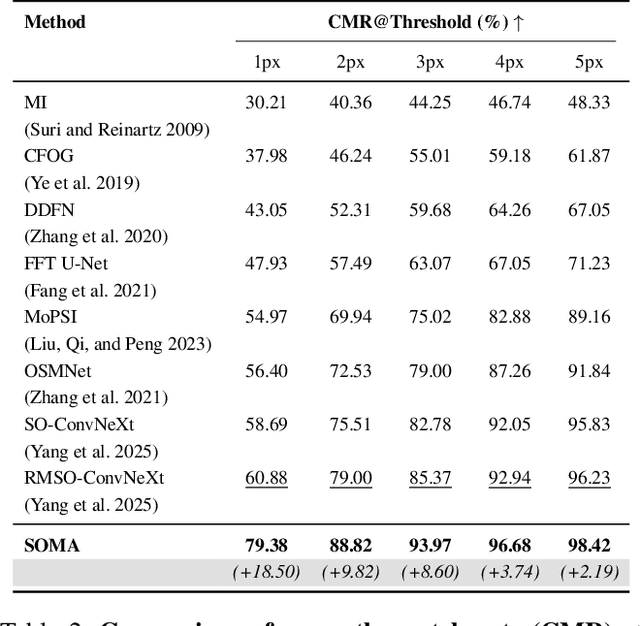
Achieving pixel-level registration between SAR and optical images remains a challenging task due to their fundamentally different imaging mechanisms and visual characteristics. Although deep learning has achieved great success in many cross-modal tasks, its performance on SAR-Optical registration tasks is still unsatisfactory. Gradient-based information has traditionally played a crucial role in handcrafted descriptors by highlighting structural differences. However, such gradient cues have not been effectively leveraged in deep learning frameworks for SAR-Optical image matching. To address this gap, we propose SOMA, a dense registration framework that integrates structural gradient priors into deep features and refines alignment through a hybrid matching strategy. Specifically, we introduce the Feature Gradient Enhancer (FGE), which embeds multi-scale, multi-directional gradient filters into the feature space using attention and reconstruction mechanisms to boost feature distinctiveness. Furthermore, we propose the Global-Local Affine-Flow Matcher (GLAM), which combines affine transformation and flow-based refinement within a coarse-to-fine architecture to ensure both structural consistency and local accuracy. Experimental results demonstrate that SOMA significantly improves registration precision, increasing the CMR@1px by 12.29% on the SEN1-2 dataset and 18.50% on the GFGE_SO dataset. In addition, SOMA exhibits strong robustness and generalizes well across diverse scenes and resolutions.
SLRTP2025 Sign Language Production Challenge: Methodology, Results, and Future Work
Aug 09, 2025Sign Language Production (SLP) is the task of generating sign language video from spoken language inputs. The field has seen a range of innovations over the last few years, with the introduction of deep learning-based approaches providing significant improvements in the realism and naturalness of generated outputs. However, the lack of standardized evaluation metrics for SLP approaches hampers meaningful comparisons across different systems. To address this, we introduce the first Sign Language Production Challenge, held as part of the third SLRTP Workshop at CVPR 2025. The competition's aims are to evaluate architectures that translate from spoken language sentences to a sequence of skeleton poses, known as Text-to-Pose (T2P) translation, over a range of metrics. For our evaluation data, we use the RWTH-PHOENIX-Weather-2014T dataset, a German Sign Language - Deutsche Gebardensprache (DGS) weather broadcast dataset. In addition, we curate a custom hidden test set from a similar domain of discourse. This paper presents the challenge design and the winning methodologies. The challenge attracted 33 participants who submitted 231 solutions, with the top-performing team achieving BLEU-1 scores of 31.40 and DTW-MJE of 0.0574. The winning approach utilized a retrieval-based framework and a pre-trained language model. As part of the workshop, we release a standardized evaluation network, including high-quality skeleton extraction-based keypoints establishing a consistent baseline for the SLP field, which will enable future researchers to compare their work against a broader range of methods.
Flow-CDNet: A Novel Network for Detecting Both Slow and Fast Changes in Bitemporal Images
Jul 03, 2025Change detection typically involves identifying regions with changes between bitemporal images taken at the same location. Besides significant changes, slow changes in bitemporal images are also important in real-life scenarios. For instance, weak changes often serve as precursors to major hazards in scenarios like slopes, dams, and tailings ponds. Therefore, designing a change detection network that simultaneously detects slow and fast changes presents a novel challenge. In this paper, to address this challenge, we propose a change detection network named Flow-CDNet, consisting of two branches: optical flow branch and binary change detection branch. The first branch utilizes a pyramid structure to extract displacement changes at multiple scales. The second one combines a ResNet-based network with the optical flow branch's output to generate fast change outputs. Subsequently, to supervise and evaluate this new change detection framework, a self-built change detection dataset Flow-Change, a loss function combining binary tversky loss and L2 norm loss, along with a new evaluation metric called FEPE are designed. Quantitative experiments conducted on Flow-Change dataset demonstrated that our approach outperforms the existing methods. Furthermore, ablation experiments verified that the two branches can promote each other to enhance the detection performance.
Aligning Large Language Models with Implicit Preferences from User-Generated Content
Jun 04, 2025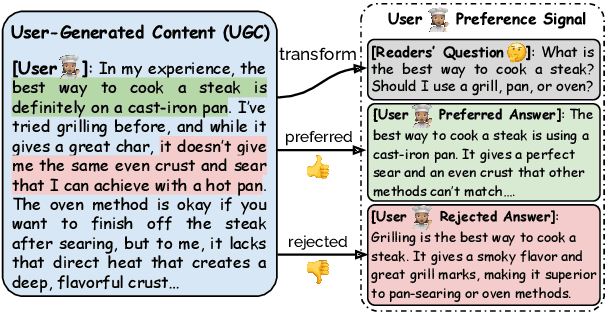
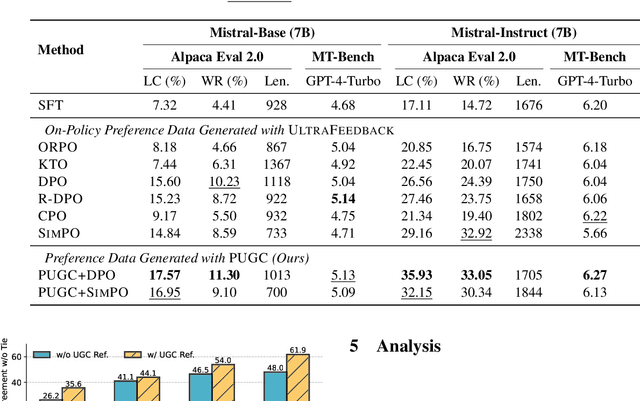
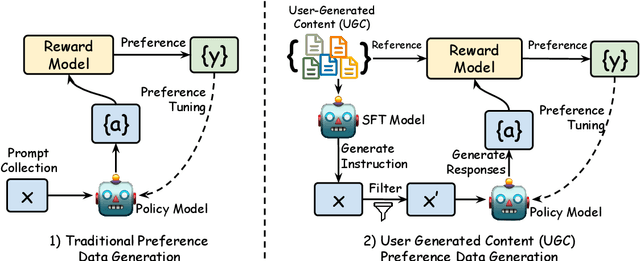

Learning from preference feedback is essential for aligning large language models (LLMs) with human values and improving the quality of generated responses. However, existing preference learning methods rely heavily on curated data from humans or advanced LLMs, which is costly and difficult to scale. In this work, we present PUGC, a novel framework that leverages implicit human Preferences in unlabeled User-Generated Content (UGC) to generate preference data. Although UGC is not explicitly created to guide LLMs in generating human-preferred responses, it often reflects valuable insights and implicit preferences from its creators that has the potential to address readers' questions. PUGC transforms UGC into user queries and generates responses from the policy model. The UGC is then leveraged as a reference text for response scoring, aligning the model with these implicit preferences. This approach improves the quality of preference data while enabling scalable, domain-specific alignment. Experimental results on Alpaca Eval 2 show that models trained with DPO and PUGC achieve a 9.37% performance improvement over traditional methods, setting a 35.93% state-of-the-art length-controlled win rate using Mistral-7B-Instruct. Further studies highlight gains in reward quality, domain-specific alignment effectiveness, robustness against UGC quality, and theory of mind capabilities. Our code and dataset are available at https://zhaoxuan.info/PUGC.github.io/
D$^{2}$MoE: Dual Routing and Dynamic Scheduling for Efficient On-Device MoE-based LLM Serving
Apr 17, 2025
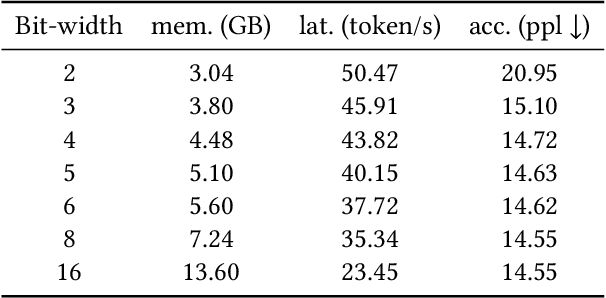


The mixture of experts (MoE) model is a sparse variant of large language models (LLMs), designed to hold a better balance between intelligent capability and computational overhead. Despite its benefits, MoE is still too expensive to deploy on resource-constrained edge devices, especially with the demands of on-device inference services. Recent research efforts often apply model compression techniques, such as quantization, pruning and merging, to restrict MoE complexity. Unfortunately, due to their predefined static model optimization strategies, they cannot always achieve the desired quality-overhead trade-off when handling multiple requests, finally degrading the on-device quality of service. These limitations motivate us to propose the D$^2$MoE, an algorithm-system co-design framework that matches diverse task requirements by dynamically allocating the most proper bit-width to each expert. Specifically, inspired by the nested structure of matryoshka dolls, we propose the matryoshka weight quantization (MWQ) to progressively compress expert weights in a bit-nested manner and reduce the required runtime memory. On top of it, we further optimize the I/O-computation pipeline and design a heuristic scheduling algorithm following our hottest-expert-bit-first (HEBF) principle, which maximizes the expert parallelism between I/O and computation queue under constrained memory budgets, thus significantly reducing the idle temporal bubbles waiting for the experts to load. Evaluations on real edge devices show that D$^2$MoE improves the overall inference throughput by up to 1.39$\times$ and reduces the peak memory footprint by up to 53% over the latest on-device inference frameworks, while still preserving comparable serving accuracy as its INT8 counterparts.
IHEval: Evaluating Language Models on Following the Instruction Hierarchy
Feb 12, 2025The instruction hierarchy, which establishes a priority order from system messages to user messages, conversation history, and tool outputs, is essential for ensuring consistent and safe behavior in language models (LMs). Despite its importance, this topic receives limited attention, and there is a lack of comprehensive benchmarks for evaluating models' ability to follow the instruction hierarchy. We bridge this gap by introducing IHEval, a novel benchmark comprising 3,538 examples across nine tasks, covering cases where instructions in different priorities either align or conflict. Our evaluation of popular LMs highlights their struggle to recognize instruction priorities. All evaluated models experience a sharp performance decline when facing conflicting instructions, compared to their original instruction-following performance. Moreover, the most competitive open-source model only achieves 48% accuracy in resolving such conflicts. Our results underscore the need for targeted optimization in the future development of LMs.
Shopping MMLU: A Massive Multi-Task Online Shopping Benchmark for Large Language Models
Oct 28, 2024



Online shopping is a complex multi-task, few-shot learning problem with a wide and evolving range of entities, relations, and tasks. However, existing models and benchmarks are commonly tailored to specific tasks, falling short of capturing the full complexity of online shopping. Large Language Models (LLMs), with their multi-task and few-shot learning abilities, have the potential to profoundly transform online shopping by alleviating task-specific engineering efforts and by providing users with interactive conversations. Despite the potential, LLMs face unique challenges in online shopping, such as domain-specific concepts, implicit knowledge, and heterogeneous user behaviors. Motivated by the potential and challenges, we propose Shopping MMLU, a diverse multi-task online shopping benchmark derived from real-world Amazon data. Shopping MMLU consists of 57 tasks covering 4 major shopping skills: concept understanding, knowledge reasoning, user behavior alignment, and multi-linguality, and can thus comprehensively evaluate the abilities of LLMs as general shop assistants. With Shopping MMLU, we benchmark over 20 existing LLMs and uncover valuable insights about practices and prospects of building versatile LLM-based shop assistants. Shopping MMLU can be publicly accessed at https://github.com/KL4805/ShoppingMMLU. In addition, with Shopping MMLU, we host a competition in KDD Cup 2024 with over 500 participating teams. The winning solutions and the associated workshop can be accessed at our website https://amazon-kddcup24.github.io/.