 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreferences Order, Ratings Anchor: From Fused Expert Aesthetic Ground Truth to Self-Distillation
May 20, 2026Pairwise preferences and pointwise ratings are the two dominant annotation protocols in image aesthetic assessment (IAA), yet existing benchmarks adopt only one, leaving their complementarity unmeasured under controlled conditions. We introduce PPaint, a matched dual-protocol benchmark in which 15 domain experts, 5 per category, annotate 150 Chinese paintings under both protocols across five aesthetic dimensions, collecting 45,900 pairwise expert judgments through a locally dense preference design alongside the matched ratings. The matched design reveals complementary strengths: preferences yield more consistent ordinal rankings, while ratings anchor the absolute score scale. Fusing both signals via two independent preference-to-score methods yields a fused expert ground truth on which the two constructions converge to nearly identical scores. The same preference-to-score principle extends to label-free VLM training. PSDistill converts VLM pairwise judgments into calibrated pseudo-scores via an Elo reference pool, and trains the same VLM with confidence-weighted ranking optimization to produce a single-pass aesthetic scorer. Trained on a single painting category, the distilled Qwen3-VL-8B improves mean SRCC from 0.504 to 0.709 across all three categories, outperforming all open-source baselines including the dedicated aesthetic model ArtiMuse and matching closed-source Gemini-3.1-Pro within 0.04 SRCC at single-pass inference cost, with cross-domain transfer further validated on APDDv2. We will release the full PPaint dataset and training code.
PRBench: End-to-end Paper Reproduction in Physics Research
Mar 29, 2026AI agents powered by large language models exhibit strong reasoning and problem-solving capabilities, enabling them to assist scientific research tasks such as formula derivation and code generation. However, whether these agents can reliably perform end-to-end reproduction from real scientific papers remains an open question. We introduce PRBench, a benchmark of 30 expert-curated tasks spanning 11 subfields of physics. Each task requires an agent to comprehend the methodology of a published paper, implement the corresponding algorithms from scratch, and produce quantitative results matching the original publication. Agents are provided only with the task instruction and paper content, and operate in a sandboxed execution environment. All tasks are contributed by domain experts from over 20 research groups at the School of Physics, Peking University, each grounded in a real published paper and validated through end-to-end reproduction with verified ground-truth results and detailed scoring rubrics. Using an agentified assessment pipeline, we evaluate a set of coding agents on PRBench and analyze their capabilities across key dimensions of scientific reasoning and execution. The best-performing agent, OpenAI Codex powered by GPT-5.3-Codex, achieves a mean overall score of 34%. All agents exhibit a zero end-to-end callback success rate, with particularly poor performance in data accuracy and code correctness. We further identify systematic failure modes, including errors in formula implementation, inability to debug numerical simulations, and fabrication of output data. Overall, PRBench provides a rigorous benchmark for evaluating progress toward autonomous scientific research.
Persona-Based Simulation of Human Opinion at Population Scale
Mar 28, 2026What does it mean to model a person, not merely to predict isolated responses, preferences, or behaviors, but to simulate how an individual interprets events, forms opinions, makes judgments, and acts consistently across contexts? This question matters because social science requires not only observing and predicting human outcomes, but also simulating interventions and their consequences. Although large language models (LLMs) can generate human-like answers, most existing approaches remain predictive, relying on demographic correlations rather than representations of individuals themselves. We introduce SPIRIT (Semi-structured Persona Inference and Reasoning for Individualized Trajectories), a framework designed explicitly for simulation rather than prediction. SPIRIT infers psychologically grounded, semi-structured personas from public social media posts, integrating structured attributes (e.g., personality traits and world beliefs) with unstructured narrative text reflecting values and lived experience. These personas prompt LLM-based agents to act as specific individuals when answering survey questions or responding to events. Using the Ipsos KnowledgePanel, a nationally representative probability sample of U.S. adults, we show that SPIRIT-conditioned simulations recover self-reported responses more faithfully than demographic persona and reproduce human-like heterogeneity in response patterns. We further demonstrate that persona banks can function as virtual respondent panels for studying both stable attitudes and time-sensitive public opinion.
Dehallu3D: Hallucination-Mitigated 3D Generation from Single Image via Cyclic View Consistency Refinement
Mar 02, 2026Large 3D reconstruction models have revolutionized the 3D content generation field, enabling broad applications in virtual reality and gaming. Just like other large models, large 3D reconstruction models suffer from hallucinations as well, introducing structural outliers (e.g., odd holes or protrusions) that deviate from the input data. However, unlike other large models, hallucinations in large 3D reconstruction models remain severely underexplored, leading to malformed 3D-printed objects or insufficient immersion in virtual scenes. Such hallucinations majorly originate from that existing methods reconstruct 3D content from sparsely generated multi-view images which suffer from large viewpoint gaps and discontinuities. To mitigate hallucinations by eliminating the outliers, we propose Dehallu3D for 3D mesh generation. Our key idea is to design a balanced multi-view continuity constraint to enforce smooth transitions across dense intermediate viewpoints, while avoiding over-smoothing that could erase sharp geometric features. Therefore, Dehallu3D employs a plug-and-play optimization module with two key constraints: (i) adjacent consistency to ensure geometric continuity across views, and (ii) adaptive smoothness to retain fine details.We further propose the Outlier Risk Measure (ORM) metric to quantify geometric fidelity in 3D generation from the perspective of outliers. Extensive experiments show that Dehallu3D achieves high-fidelity 3D generation by effectively preserving structural details while removing hallucinated outliers.
FGM-HD: Boosting Generation Diversity of Fractal Generative Models through Hausdorff Dimension Induction
Nov 18, 2025Improving the diversity of generated results while maintaining high visual quality remains a significant challenge in image generation tasks. Fractal Generative Models (FGMs) are efficient in generating high-quality images, but their inherent self-similarity limits the diversity of output images. To address this issue, we propose a novel approach based on the Hausdorff Dimension (HD), a widely recognized concept in fractal geometry used to quantify structural complexity, which aids in enhancing the diversity of generated outputs. To incorporate HD into FGM, we propose a learnable HD estimation method that predicts HD directly from image embeddings, addressing computational cost concerns. However, simply introducing HD into a hybrid loss is insufficient to enhance diversity in FGMs due to: 1) degradation of image quality, and 2) limited improvement in generation diversity. To this end, during training, we adopt an HD-based loss with a monotonic momentum-driven scheduling strategy to progressively optimize the hyperparameters, obtaining optimal diversity without sacrificing visual quality. Moreover, during inference, we employ HD-guided rejection sampling to select geometrically richer outputs. Extensive experiments on the ImageNet dataset demonstrate that our FGM-HD framework yields a 39\% improvement in output diversity compared to vanilla FGMs, while preserving comparable image quality. To our knowledge, this is the very first work introducing HD into FGM. Our method effectively enhances the diversity of generated outputs while offering a principled theoretical contribution to FGM development.
Vec2Summ: Text Summarization via Probabilistic Sentence Embeddings
Aug 09, 2025



We propose Vec2Summ, a novel method for abstractive summarization that frames the task as semantic compression. Vec2Summ represents a document collection using a single mean vector in the semantic embedding space, capturing the central meaning of the corpus. To reconstruct fluent summaries, we perform embedding inversion -- decoding this mean vector into natural language using a generative language model. To improve reconstruction quality and capture some degree of topical variability, we introduce stochasticity by sampling from a Gaussian distribution centered on the mean. This approach is loosely analogous to bagging in ensemble learning, where controlled randomness encourages more robust and varied outputs. Vec2Summ addresses key limitations of LLM-based summarization methods. It avoids context-length constraints, enables interpretable and controllable generation via semantic parameters, and scales efficiently with corpus size -- requiring only $O(d + d^2)$ parameters. Empirical results show that Vec2Summ produces coherent summaries for topically focused, order-invariant corpora, with performance comparable to direct LLM summarization in terms of thematic coverage and efficiency, albeit with less fine-grained detail. These results underscore Vec2Summ's potential in settings where scalability, semantic control, and corpus-level abstraction are prioritized.
Shopping MMLU: A Massive Multi-Task Online Shopping Benchmark for Large Language Models
Oct 28, 2024



Online shopping is a complex multi-task, few-shot learning problem with a wide and evolving range of entities, relations, and tasks. However, existing models and benchmarks are commonly tailored to specific tasks, falling short of capturing the full complexity of online shopping. Large Language Models (LLMs), with their multi-task and few-shot learning abilities, have the potential to profoundly transform online shopping by alleviating task-specific engineering efforts and by providing users with interactive conversations. Despite the potential, LLMs face unique challenges in online shopping, such as domain-specific concepts, implicit knowledge, and heterogeneous user behaviors. Motivated by the potential and challenges, we propose Shopping MMLU, a diverse multi-task online shopping benchmark derived from real-world Amazon data. Shopping MMLU consists of 57 tasks covering 4 major shopping skills: concept understanding, knowledge reasoning, user behavior alignment, and multi-linguality, and can thus comprehensively evaluate the abilities of LLMs as general shop assistants. With Shopping MMLU, we benchmark over 20 existing LLMs and uncover valuable insights about practices and prospects of building versatile LLM-based shop assistants. Shopping MMLU can be publicly accessed at https://github.com/KL4805/ShoppingMMLU. In addition, with Shopping MMLU, we host a competition in KDD Cup 2024 with over 500 participating teams. The winning solutions and the associated workshop can be accessed at our website https://amazon-kddcup24.github.io/.
Saliency Guided Optimization of Diffusion Latents
Oct 14, 2024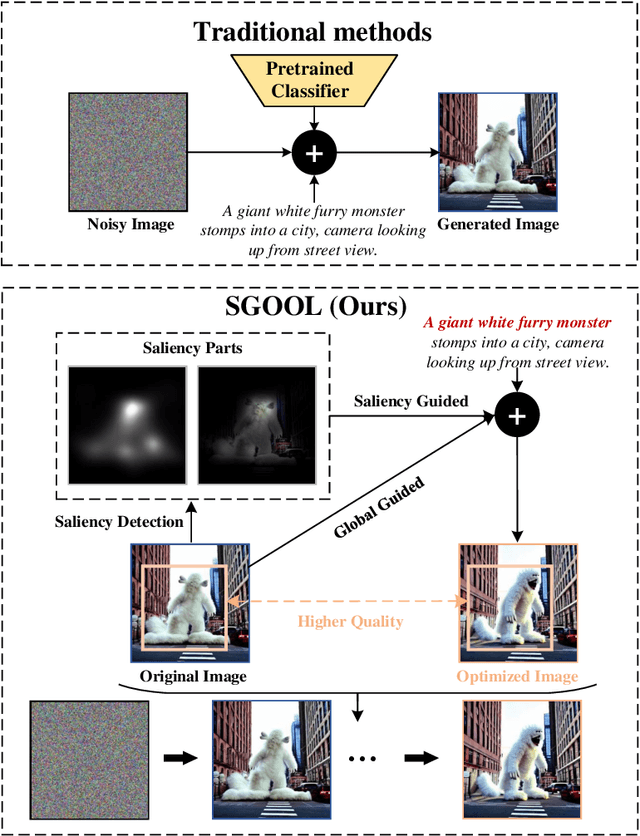

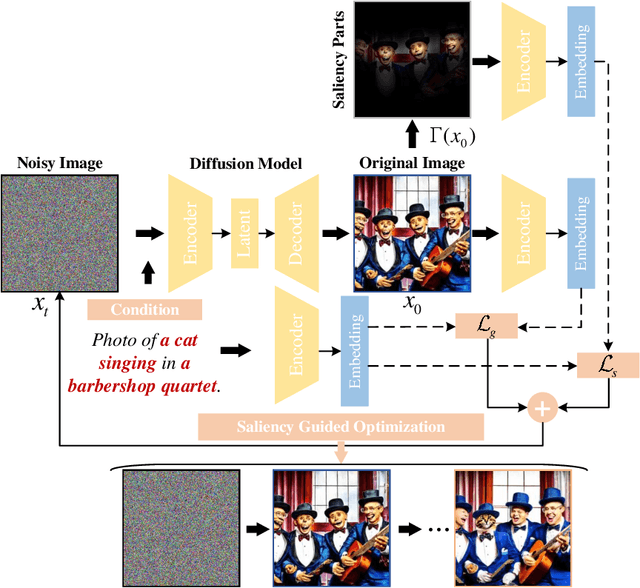
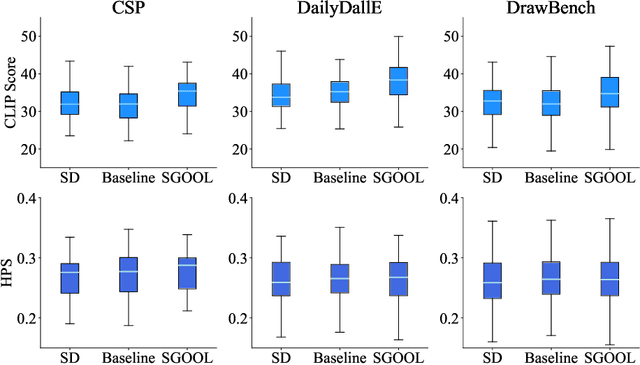
With the rapid advances in diffusion models, generating decent images from text prompts is no longer challenging. The key to text-to-image generation is how to optimize the results of a text-to-image generation model so that they can be better aligned with human intentions or prompts. Existing optimization methods commonly treat the entire image uniformly and conduct global optimization. These methods overlook the fact that when viewing an image, the human visual system naturally prioritizes attention toward salient areas, often neglecting less or non-salient regions. That is, humans are likely to neglect optimizations in non-salient areas. Consequently, although model retaining is conducted under the guidance of additional large and multimodality models, existing methods, which perform uniform optimizations, yield sub-optimal results. To address this alignment challenge effectively and efficiently, we propose Saliency Guided Optimization Of Diffusion Latents (SGOOL). We first employ a saliency detector to mimic the human visual attention system and mark out the salient regions. To avoid retraining an additional model, our method directly optimizes the diffusion latents. Besides, SGOOL utilizes an invertible diffusion process and endows it with the merits of constant memory implementation. Hence, our method becomes a parameter-efficient and plug-and-play fine-tuning method. Extensive experiments have been done with several metrics and human evaluation. Experimental results demonstrate the superiority of SGOOL in image quality and prompt alignment.
FastLexRank: Efficient Lexical Ranking for Structuring Social Media Posts
Oct 02, 2024



We present FastLexRank\footnote{https://github.com/LiMaoUM/FastLexRank}, an efficient and scalable implementation of the LexRank algorithm for text ranking. Designed to address the computational and memory complexities of the original LexRank method, FastLexRank significantly reduces time and memory requirements from $\mathcal{O}(n^2)$ to $\mathcal{O}(n)$ without compromising the quality or accuracy of the results. By employing an optimized approach to calculating the stationary distribution of sentence graphs, FastLexRank maintains an identical results with the original LexRank scores while enhancing computational efficiency. This paper details the algorithmic improvements that enable the processing of large datasets, such as social media corpora, in real-time. Empirical results demonstrate its effectiveness, and we propose its use in identifying central tweets, which can be further analyzed using advanced NLP techniques. FastLexRank offers a scalable solution for text centrality calculation, addressing the growing need for efficient processing of digital content.
Advancing Annotation of Stance in Social Media Posts: A Comparative Analysis of Large Language Models and Crowd Sourcing
Jun 11, 2024In the rapidly evolving landscape of Natural Language Processing (NLP), the use of Large Language Models (LLMs) for automated text annotation in social media posts has garnered significant interest. Despite the impressive innovations in developing LLMs like ChatGPT, their efficacy, and accuracy as annotation tools are not well understood. In this paper, we analyze the performance of eight open-source and proprietary LLMs for annotating the stance expressed in social media posts, benchmarking their performance against human annotators' (i.e., crowd-sourced) judgments. Additionally, we investigate the conditions under which LLMs are likely to disagree with human judgment. A significant finding of our study is that the explicitness of text expressing a stance plays a critical role in how faithfully LLMs' stance judgments match humans'. We argue that LLMs perform well when human annotators do, and when LLMs fail, it often corresponds to situations in which human annotators struggle to reach an agreement. We conclude with recommendations for a comprehensive approach that combines the precision of human expertise with the scalability of LLM predictions. This study highlights the importance of improving the accuracy and comprehensiveness of automated stance detection, aiming to advance these technologies for more efficient and unbiased analysis of social media.