 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness Risks for Group-conditionally Missing Demographics
Feb 20, 2024



Fairness-aware classification models have gained increasing attention in recent years as concerns grow on discrimination against some demographic groups. Most existing models require full knowledge of the sensitive features, which can be impractical due to privacy, legal issues, and an individual's fear of discrimination. The key challenge we will address is the group dependency of the unavailability, e.g., people of some age range may be more reluctant to reveal their age. Our solution augments general fairness risks with probabilistic imputations of the sensitive features, while jointly learning the group-conditionally missing probabilities in a variational auto-encoder. Our model is demonstrated effective on both image and tabular datasets, achieving an improved balance between accuracy and fairness.
How Does Adaptive Optimization Impact Local Neural Network Geometry?
Nov 04, 2022

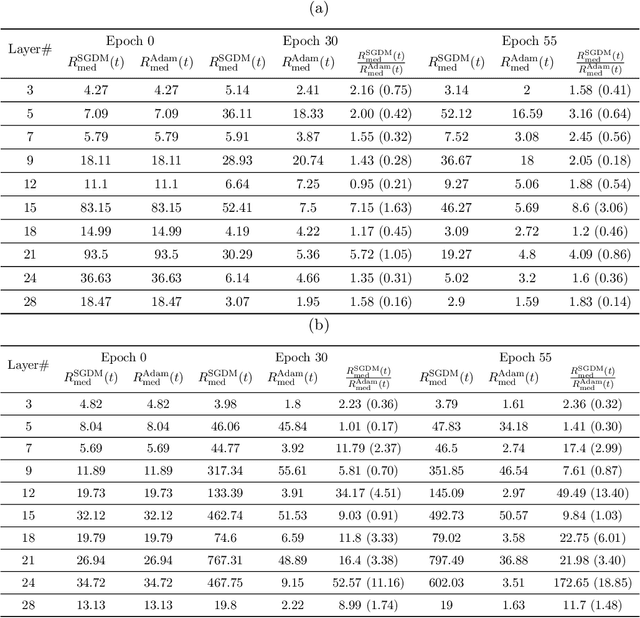
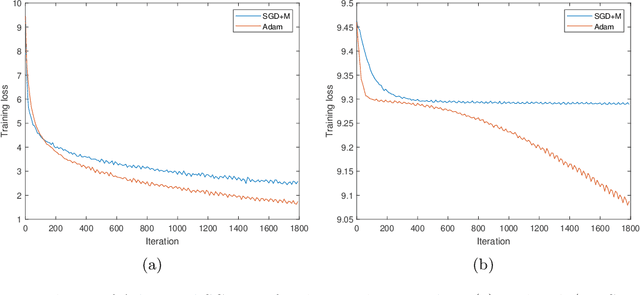
Adaptive optimization methods are well known to achieve superior convergence relative to vanilla gradient methods. The traditional viewpoint in optimization, particularly in convex optimization, explains this improved performance by arguing that, unlike vanilla gradient schemes, adaptive algorithms mimic the behavior of a second-order method by adapting to the global geometry of the loss function. We argue that in the context of neural network optimization, this traditional viewpoint is insufficient. Instead, we advocate for a local trajectory analysis. For iterate trajectories produced by running a generic optimization algorithm OPT, we introduce $R^{\text{OPT}}_{\text{med}}$, a statistic that is analogous to the condition number of the loss Hessian evaluated at the iterates. Through extensive experiments, we show that adaptive methods such as Adam bias the trajectories towards regions where $R^{\text{Adam}}_{\text{med}}$ is small, where one might expect faster convergence. By contrast, vanilla gradient methods like SGD bias the trajectories towards regions where $R^{\text{SGD}}_{\text{med}}$ is comparatively large. We complement these empirical observations with a theoretical result that provably demonstrates this phenomenon in the simplified setting of a two-layer linear network. We view our findings as evidence for the need of a new explanation of the success of adaptive methods, one that is different than the conventional wisdom.