 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward More Accurate and Generalizable Evaluation Metrics for Task-Oriented Dialogs
Jun 09, 2023
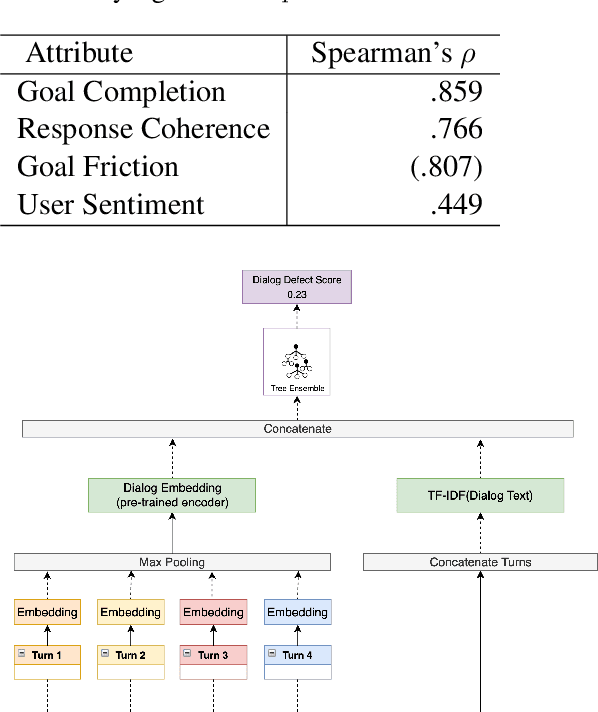

Measurement of interaction quality is a critical task for the improvement of spoken dialog systems. Existing approaches to dialog quality estimation either focus on evaluating the quality of individual turns, or collect dialog-level quality measurements from end users immediately following an interaction. In contrast to these approaches, we introduce a new dialog-level annotation workflow called Dialog Quality Annotation (DQA). DQA expert annotators evaluate the quality of dialogs as a whole, and also label dialogs for attributes such as goal completion and user sentiment. In this contribution, we show that: (i) while dialog quality cannot be completely decomposed into dialog-level attributes, there is a strong relationship between some objective dialog attributes and judgments of dialog quality; (ii) for the task of dialog-level quality estimation, a supervised model trained on dialog-level annotations outperforms methods based purely on aggregating turn-level features; and (iii) the proposed evaluation model shows better domain generalization ability compared to the baselines. On the basis of these results, we argue that having high-quality human-annotated data is an important component of evaluating interaction quality for large industrial-scale voice assistant platforms.
Impact of Acoustic Event Tagging on Scene Classification in a Multi-Task Learning Framework
Jun 27, 2022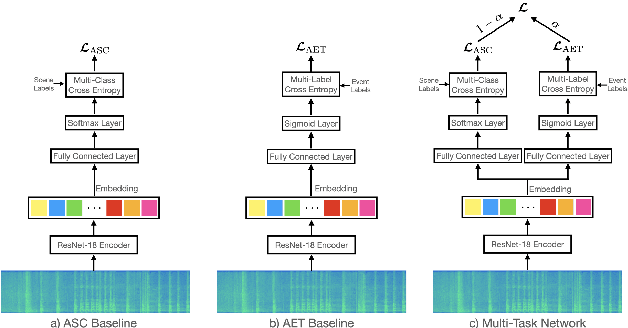
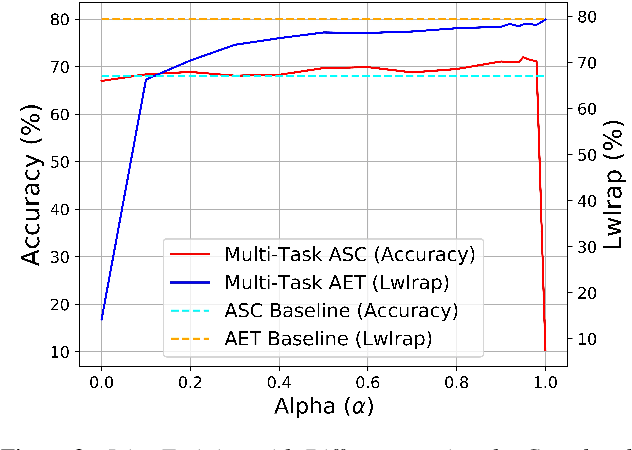
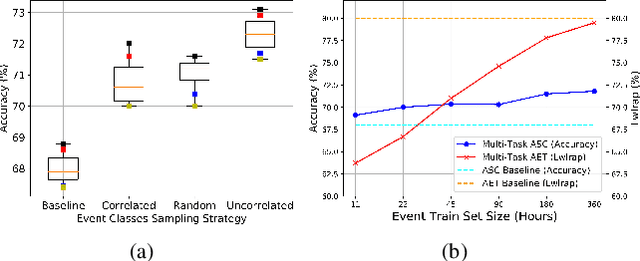
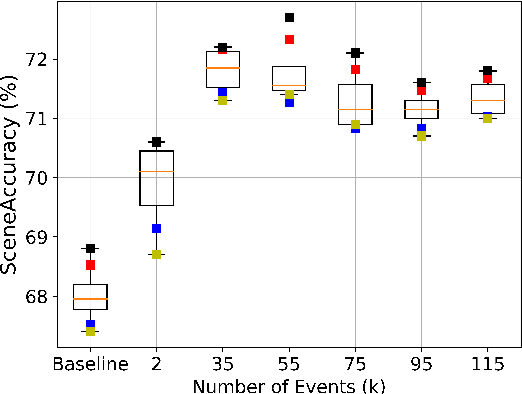
Acoustic events are sounds with well-defined spectro-temporal characteristics which can be associated with the physical objects generating them. Acoustic scenes are collections of such acoustic events in no specific temporal order. Given this natural linkage between events and scenes, a common belief is that the ability to classify events must help in the classification of scenes. This has led to several efforts attempting to do well on Acoustic Event Tagging (AET) and Acoustic Scene Classification (ASC) using a multi-task network. However, in these efforts, improvement in one task does not guarantee an improvement in the other, suggesting a tension between ASC and AET. It is unclear if improvements in AET translates to improvements in ASC. We explore this conundrum through an extensive empirical study and show that under certain conditions, using AET as an auxiliary task in the multi-task network consistently improves ASC performance. Additionally, ASC performance further improves with the AET data-set size and is not sensitive to the choice of events or the number of events in the AET data-set. We conclude that this improvement in ASC performance comes from the regularization effect of using AET and not from the network's improved ability to discern between acoustic events.
Federated Self-Supervised Learning for Acoustic Event Classification
Mar 22, 2022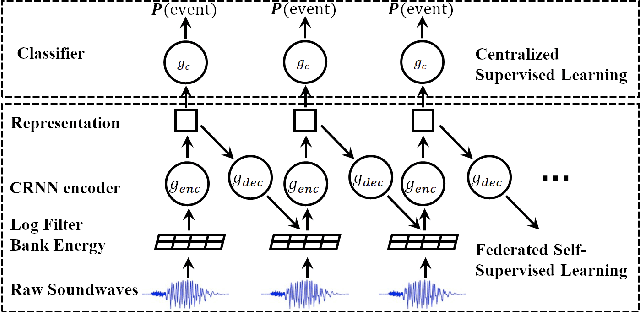

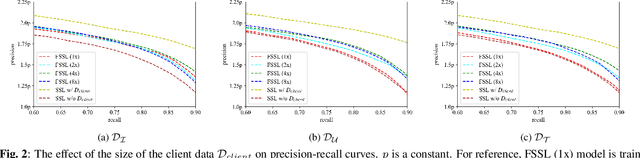
Standard acoustic event classification (AEC) solutions require large-scale collection of data from client devices for model optimization. Federated learning (FL) is a compelling framework that decouples data collection and model training to enhance customer privacy. In this work, we investigate the feasibility of applying FL to improve AEC performance while no customer data can be directly uploaded to the server. We assume no pseudo labels can be inferred from on-device user inputs, aligning with the typical use cases of AEC. We adapt self-supervised learning to the FL framework for on-device continual learning of representations, and it results in improved performance of the downstream AEC classifiers without labeled/pseudo-labeled data available. Compared to the baseline w/o FL, the proposed method improves precision up to 20.3\% relatively while maintaining the recall. Our work differs from prior work in FL in that our approach does not require user-generated learning targets, and the data we use is collected from our Beta program and is de-identified, to maximally simulate the production settings.
Neural model robustness for skill routing in large-scale conversational AI systems: A design choice exploration
Mar 04, 2021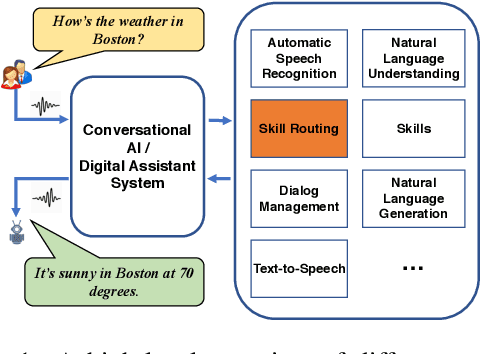

Current state-of-the-art large-scale conversational AI or intelligent digital assistant systems in industry comprises a set of components such as Automatic Speech Recognition (ASR) and Natural Language Understanding (NLU). For some of these systems that leverage a shared NLU ontology (e.g., a centralized intent/slot schema), there exists a separate skill routing component to correctly route a request to an appropriate skill, which is either a first-party or third-party application that actually executes on a user request. The skill routing component is needed as there are thousands of skills that can either subscribe to the same intent and/or subscribe to an intent under specific contextual conditions (e.g., device has a screen). Ensuring model robustness or resilience in the skill routing component is an important problem since skills may dynamically change their subscription in the ontology after the skill routing model has been deployed to production. We show how different modeling design choices impact the model robustness in the context of skill routing on a state-of-the-art commercial conversational AI system, specifically on the choices around data augmentation, model architecture, and optimization method. We show that applying data augmentation can be a very effective and practical way to drastically improve model robustness.
Contrastive Unsupervised Learning for Speech Emotion Recognition
Feb 12, 2021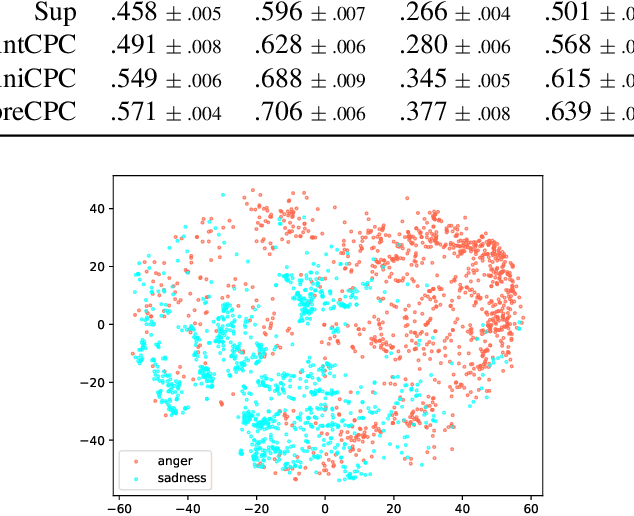

Speech emotion recognition (SER) is a key technology to enable more natural human-machine communication. However, SER has long suffered from a lack of public large-scale labeled datasets. To circumvent this problem, we investigate how unsupervised representation learning on unlabeled datasets can benefit SER. We show that the contrastive predictive coding (CPC) method can learn salient representations from unlabeled datasets, which improves emotion recognition performance. In our experiments, this method achieved state-of-the-art concordance correlation coefficient (CCC) performance for all emotion primitives (activation, valence, and dominance) on IEMOCAP. Additionally, on the MSP- Podcast dataset, our method obtained considerable performance improvements compared to baselines.
A Scalable Framework for Learning From Implicit User Feedback to Improve Natural Language Understanding in Large-Scale Conversational AI Systems
Oct 23, 2020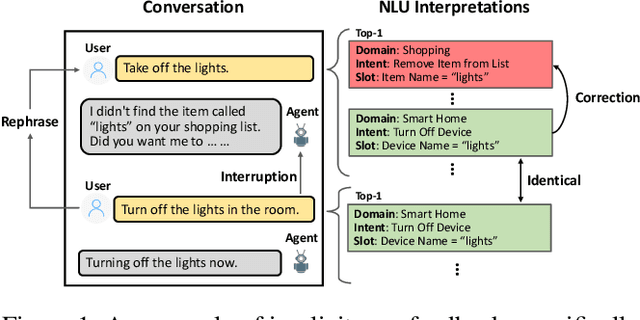
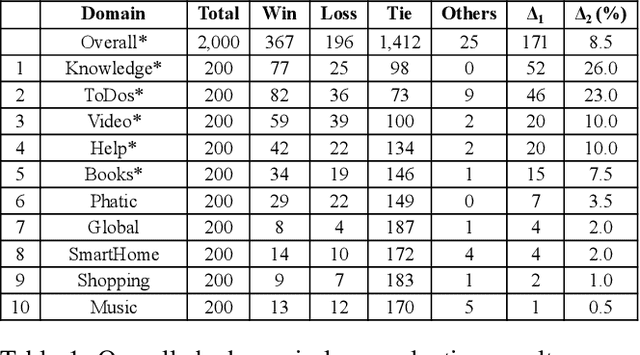
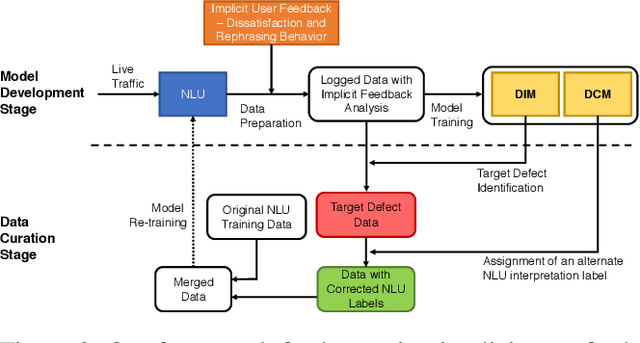
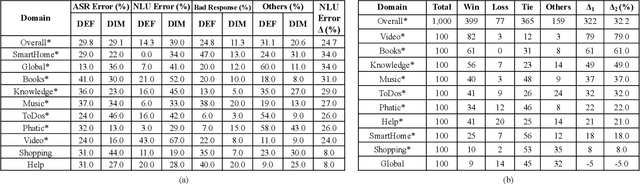
Natural Language Understanding (NLU) is an established component within a conversational AI or digital assistant system, and it is responsible for producing semantic understanding of a user request. We propose a scalable and automatic approach for improving NLU in a large-scale conversational AI system by leveraging implicit user feedback, with an insight that user interaction data and dialog context have rich information embedded from which user satisfaction and intention can be inferred. In particular, we propose a general domain-agnostic framework for curating new supervision data for improving NLU from live production traffic. With an extensive set of experiments, we show the results of applying the framework and improving NLU for a large-scale production system and show its impact across 10 domains.
Towards Data-efficient Modeling for Wake Word Spotting
Oct 13, 2020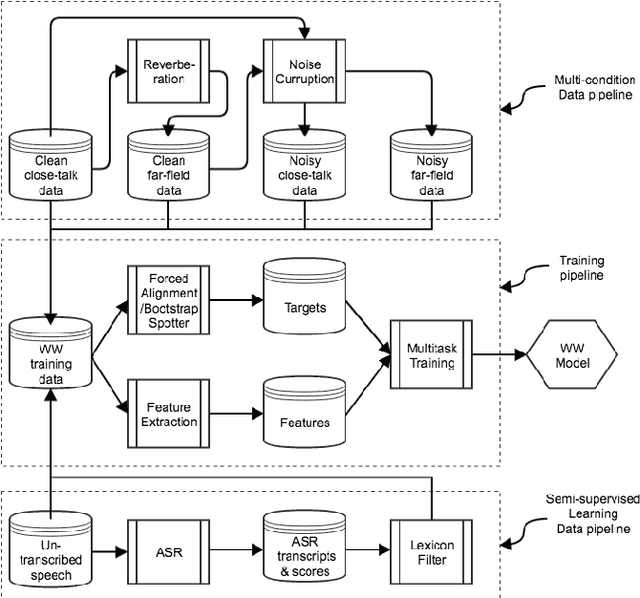
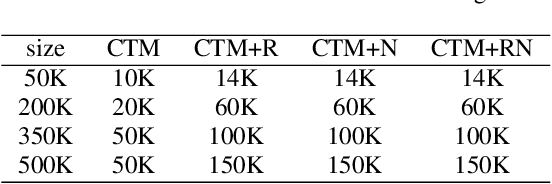
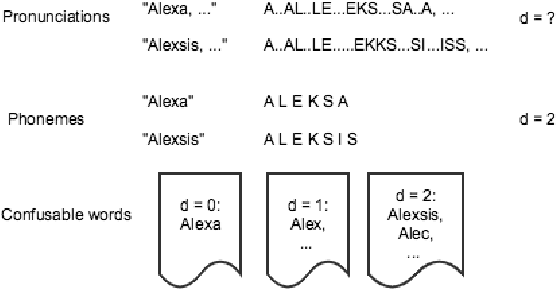

Wake word (WW) spotting is challenging in far-field not only because of the interference in signal transmission but also the complexity in acoustic environments. Traditional WW model training requires large amount of in-domain WW-specific data with substantial human annotations therefore it is hard to build WW models without such data. In this paper we present data-efficient solutions to address the challenges in WW modeling, such as domain-mismatch, noisy conditions, limited annotation, etc. Our proposed system is composed of a multi-condition training pipeline with a stratified data augmentation, which improves the model robustness to a variety of predefined acoustic conditions, together with a semi-supervised learning pipeline to accurately extract the WW and confusable examples from untranscribed speech corpus. Starting from only 10 hours of domain-mismatched WW audio, we are able to enlarge and enrich the training dataset by 20-100 times to capture the acoustic complexity. Our experiments on real user data show that the proposed solutions can achieve comparable performance of a production-grade model by saving 97\% of the amount of WW-specific data collection and 86\% of the bandwidth for annotation.
Joint Turn and Dialogue level User Satisfaction Estimation on Multi-Domain Conversations
Oct 08, 2020
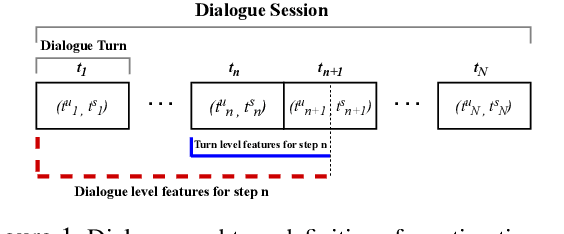
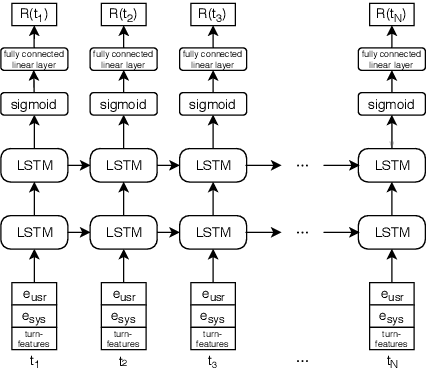
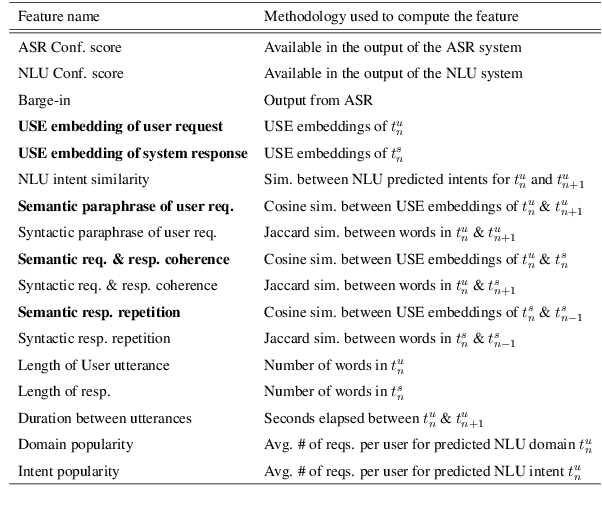
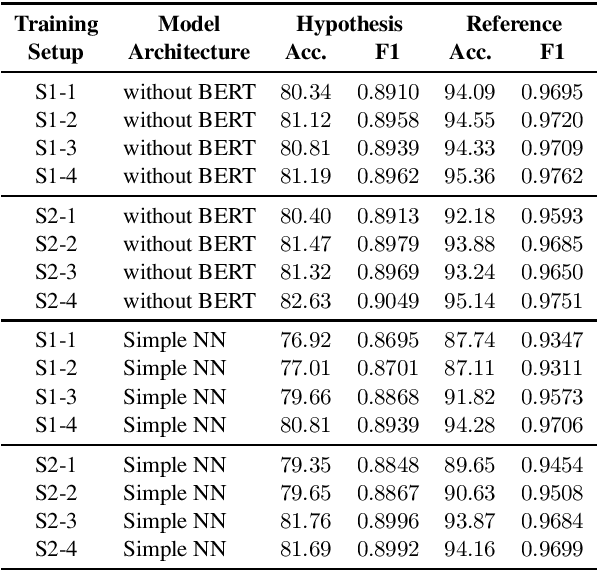
Dialogue level quality estimation is vital for optimizing data driven dialogue management. Current automated methods to estimate turn and dialogue level user satisfaction employ hand-crafted features and rely on complex annotation schemes, which reduce the generalizability of the trained models. We propose a novel user satisfaction estimation approach which minimizes an adaptive multi-task loss function in order to jointly predict turn-level Response Quality labels provided by experts and explicit dialogue-level ratings provided by end users. The proposed BiLSTM based deep neural net model automatically weighs each turn's contribution towards the estimated dialogue-level rating, implicitly encodes temporal dependencies, and removes the need to hand-craft features. On dialogues sampled from 28 Alexa domains, two dialogue systems and three user groups, the joint dialogue-level satisfaction estimation model achieved up to an absolute 27% (0.43->0.70) and 7% (0.63->0.70) improvement in linear correlation performance over baseline deep neural net and benchmark Gradient boosting regression models, respectively.
Data Augmentation for Training Dialog Models Robust to Speech Recognition Errors
Jun 10, 2020
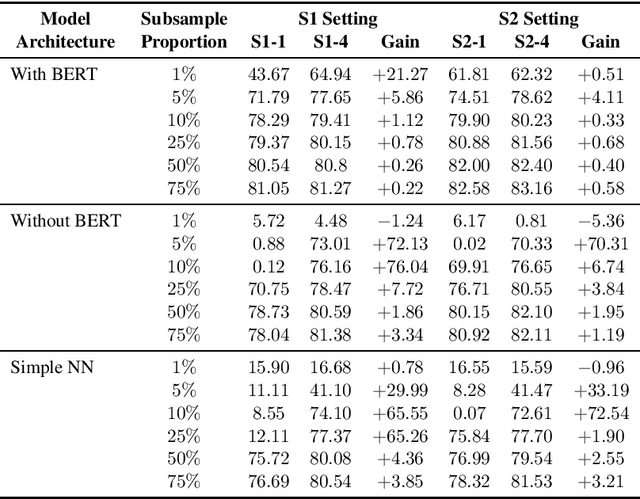
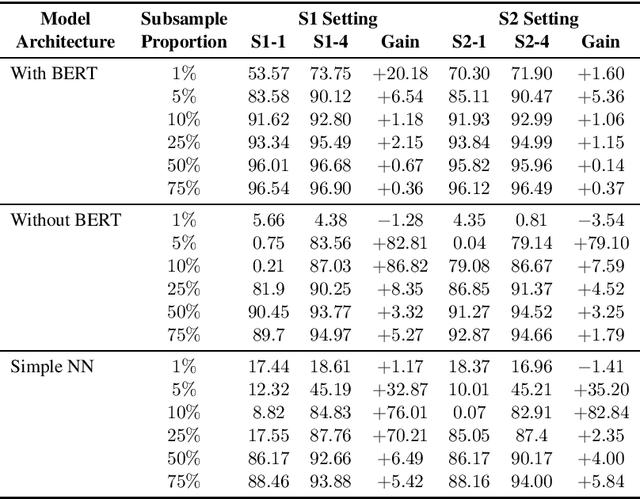
Speech-based virtual assistants, such as Amazon Alexa, Google assistant, and Apple Siri, typically convert users' audio signals to text data through automatic speech recognition (ASR) and feed the text to downstream dialog models for natural language understanding and response generation. The ASR output is error-prone; however, the downstream dialog models are often trained on error-free text data, making them sensitive to ASR errors during inference time. To bridge the gap and make dialog models more robust to ASR errors, we leverage an ASR error simulator to inject noise into the error-free text data, and subsequently train the dialog models with the augmented data. Compared to other approaches for handling ASR errors, such as using ASR lattice or end-to-end methods, our data augmentation approach does not require any modification to the ASR or downstream dialog models; our approach also does not introduce any additional latency during inference time. We perform extensive experiments on benchmark data and show that our approach improves the performance of downstream dialog models in the presence of ASR errors, and it is particularly effective in the low-resource situations where there are constraints on model size or the training data is scarce.
Few-shot acoustic event detection via meta-learning
Feb 21, 2020



We study few-shot acoustic event detection (AED) in this paper. Few-shot learning enables detection of new events with very limited labeled data. Compared to other research areas like computer vision, few-shot learning for audio recognition has been under-studied. We formulate few-shot AED problem and explore different ways of utilizing traditional supervised methods for this setting as well as a variety of meta-learning approaches, which are conventionally used to solve few-shot classification problem. Compared to supervised baselines, meta-learning models achieve superior performance, thus showing its effectiveness on generalization to new audio events. Our analysis including impact of initialization and domain discrepancy further validate the advantage of meta-learning approaches in few-shot AED.