 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of Acoustic Event Tagging on Scene Classification in a Multi-Task Learning Framework
Jun 27, 2022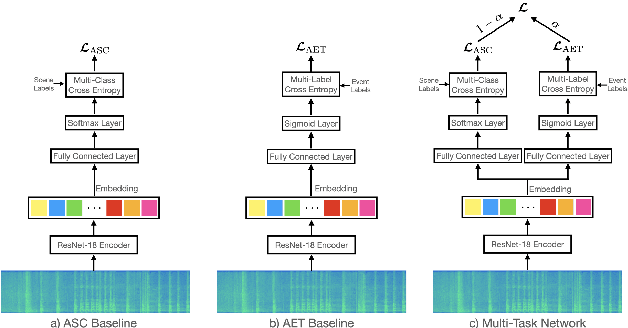
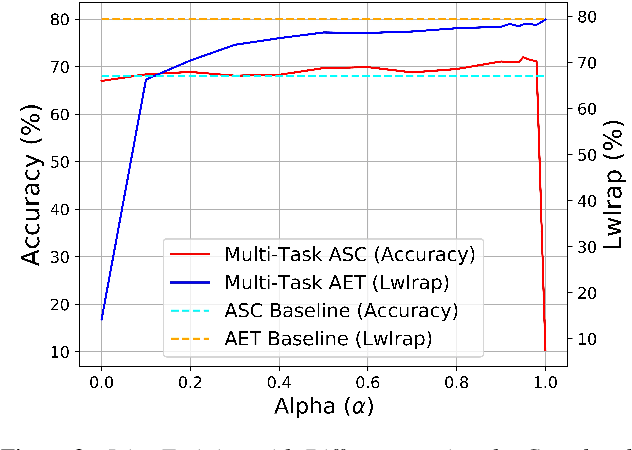
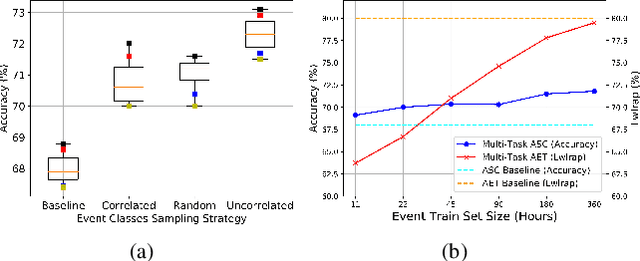
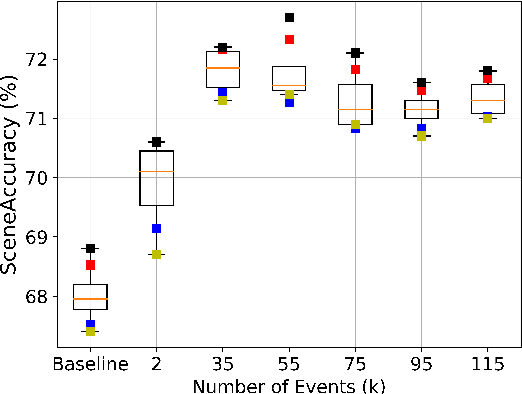
Acoustic events are sounds with well-defined spectro-temporal characteristics which can be associated with the physical objects generating them. Acoustic scenes are collections of such acoustic events in no specific temporal order. Given this natural linkage between events and scenes, a common belief is that the ability to classify events must help in the classification of scenes. This has led to several efforts attempting to do well on Acoustic Event Tagging (AET) and Acoustic Scene Classification (ASC) using a multi-task network. However, in these efforts, improvement in one task does not guarantee an improvement in the other, suggesting a tension between ASC and AET. It is unclear if improvements in AET translates to improvements in ASC. We explore this conundrum through an extensive empirical study and show that under certain conditions, using AET as an auxiliary task in the multi-task network consistently improves ASC performance. Additionally, ASC performance further improves with the AET data-set size and is not sensitive to the choice of events or the number of events in the AET data-set. We conclude that this improvement in ASC performance comes from the regularization effect of using AET and not from the network's improved ability to discern between acoustic events.
Who Spoke What? A Latent Variable Framework for the Joint Decoding of Multiple Speakers and their Keywords
Apr 29, 2015
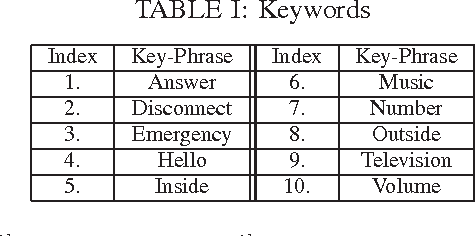
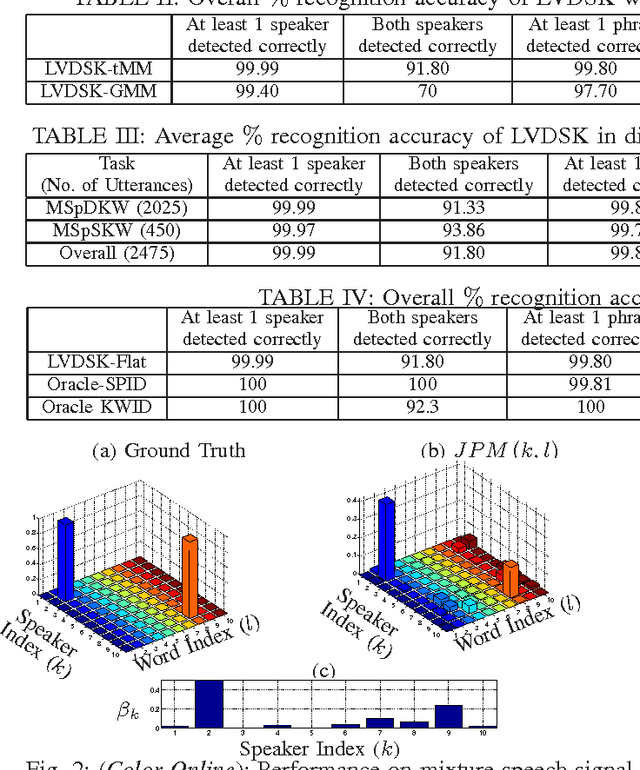
In this paper, we present a latent variable (LV) framework to identify all the speakers and their keywords given a multi-speaker mixture signal. We introduce two separate LVs to denote active speakers and the keywords uttered. The dependency of a spoken keyword on the speaker is modeled through a conditional probability mass function. The distribution of the mixture signal is expressed in terms of the LV mass functions and speaker-specific-keyword models. The proposed framework admits stochastic models, representing the probability density function of the observation vectors given that a particular speaker uttered a specific keyword, as speaker-specific-keyword models. The LV mass functions are estimated in a Maximum Likelihood framework using the Expectation Maximization (EM) algorithm. The active speakers and their keywords are detected as modes of the joint distribution of the two LVs. In mixture signals, containing two speakers uttering the keywords simultaneously, the proposed framework achieves an accuracy of 82% for detecting both the speakers and their respective keywords, using Student's-t mixture models as speaker-specific-keyword models.