 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling the Extraction of Memorized Data from Large Language Models via Prompt-Tuning
May 19, 2023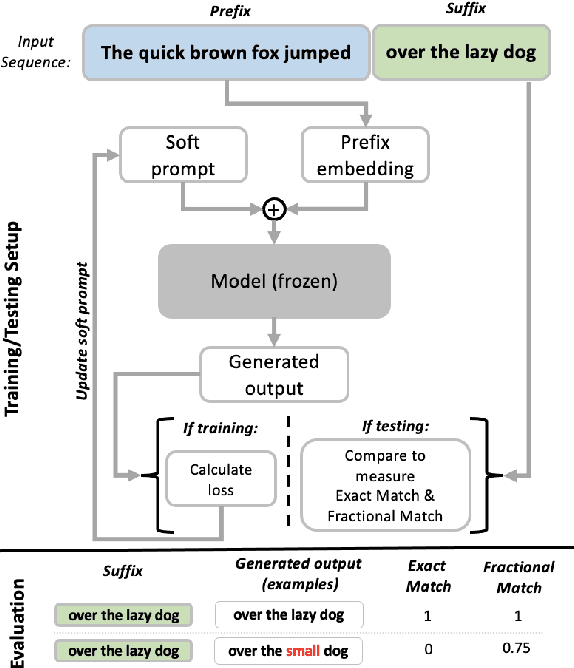
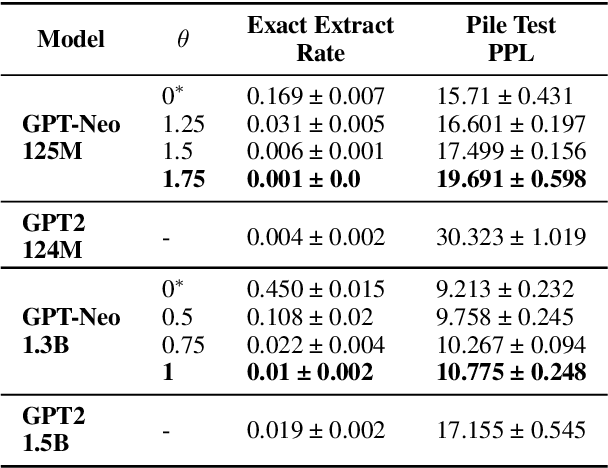
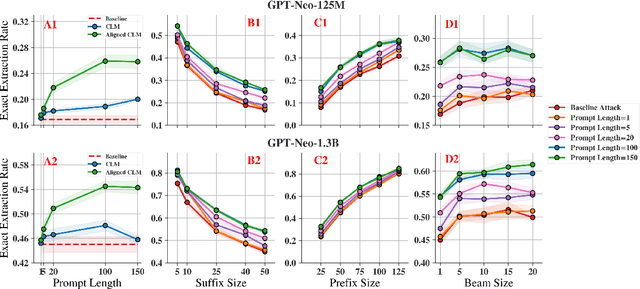
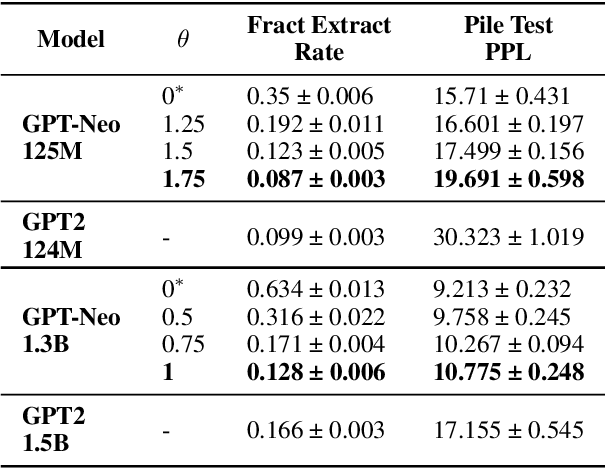
Large Language Models (LLMs) are known to memorize significant portions of their training data. Parts of this memorized content have been shown to be extractable by simply querying the model, which poses a privacy risk. We present a novel approach which uses prompt-tuning to control the extraction rates of memorized content in LLMs. We present two prompt training strategies to increase and decrease extraction rates, which correspond to an attack and a defense, respectively. We demonstrate the effectiveness of our techniques by using models from the GPT-Neo family on a public benchmark. For the 1.3B parameter GPT-Neo model, our attack yields a 9.3 percentage point increase in extraction rate compared to our baseline. Our defense can be tuned to achieve different privacy-utility trade-offs by a user-specified hyperparameter. We achieve an extraction rate reduction of up to 97.7% relative to our baseline, with a perplexity increase of 16.9%.
Impact of Acoustic Event Tagging on Scene Classification in a Multi-Task Learning Framework
Jun 27, 2022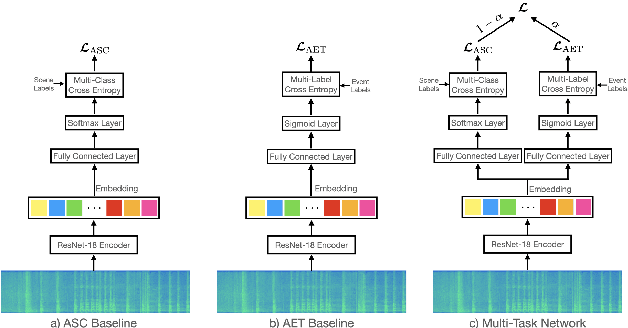
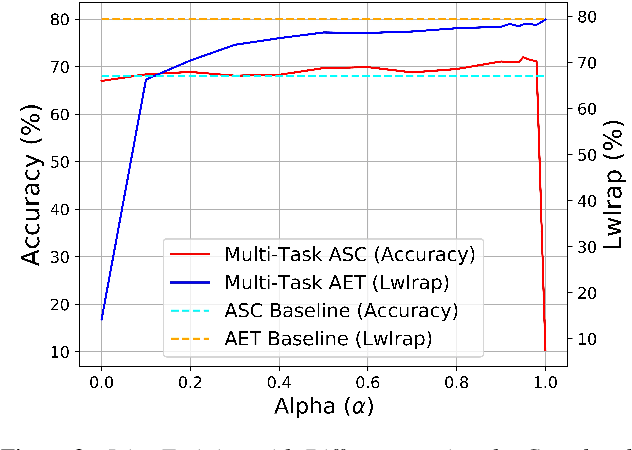
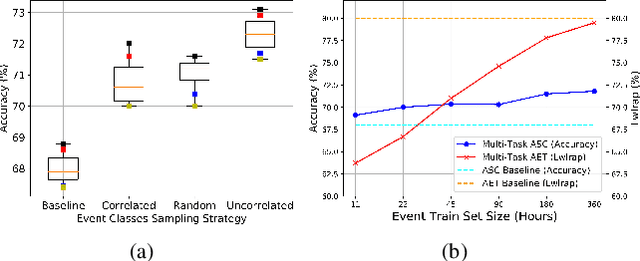
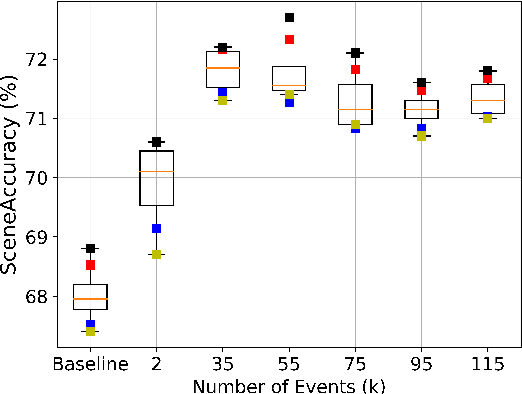
Acoustic events are sounds with well-defined spectro-temporal characteristics which can be associated with the physical objects generating them. Acoustic scenes are collections of such acoustic events in no specific temporal order. Given this natural linkage between events and scenes, a common belief is that the ability to classify events must help in the classification of scenes. This has led to several efforts attempting to do well on Acoustic Event Tagging (AET) and Acoustic Scene Classification (ASC) using a multi-task network. However, in these efforts, improvement in one task does not guarantee an improvement in the other, suggesting a tension between ASC and AET. It is unclear if improvements in AET translates to improvements in ASC. We explore this conundrum through an extensive empirical study and show that under certain conditions, using AET as an auxiliary task in the multi-task network consistently improves ASC performance. Additionally, ASC performance further improves with the AET data-set size and is not sensitive to the choice of events or the number of events in the AET data-set. We conclude that this improvement in ASC performance comes from the regularization effect of using AET and not from the network's improved ability to discern between acoustic events.
An Empirical Analysis on the Vulnerabilities of End-to-End Speech Segregation Models
Jun 20, 2022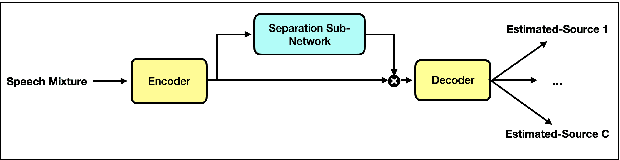
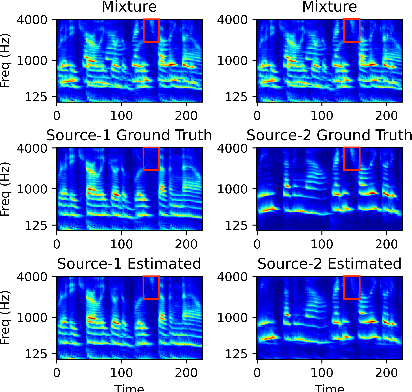
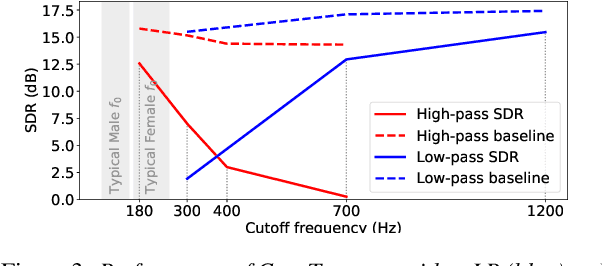
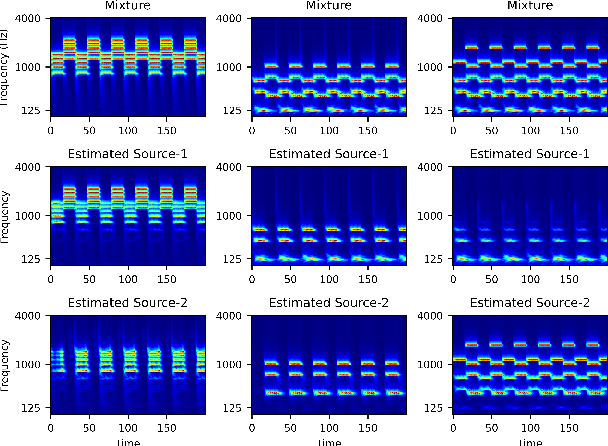
End-to-end learning models have demonstrated a remarkable capability in performing speech segregation. Despite their wide-scope of real-world applications, little is known about the mechanisms they employ to group and consequently segregate individual speakers. Knowing that harmonicity is a critical cue for these networks to group sources, in this work, we perform a thorough investigation on ConvTasnet and DPT-Net to analyze how they perform a harmonic analysis of the input mixture. We perform ablation studies where we apply low-pass, high-pass, and band-stop filters of varying pass-bands to empirically analyze the harmonics most critical for segregation. We also investigate how these networks decide which output channel to assign to an estimated source by introducing discontinuities in synthetic mixtures. We find that end-to-end networks are highly unstable, and perform poorly when confronted with deformations which are imperceptible to humans. Replacing the encoder in these networks with a spectrogram leads to lower overall performance, but much higher stability. This work helps us to understand what information these network rely on for speech segregation, and exposes two sources of generalization-errors. It also pinpoints the encoder as the part of the network responsible for these errors, allowing for a redesign with expert knowledge or transfer learning.
Canary Extraction in Natural Language Understanding Models
Mar 25, 2022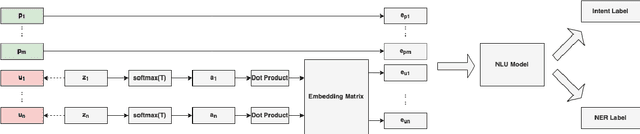
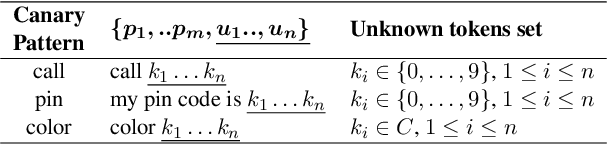
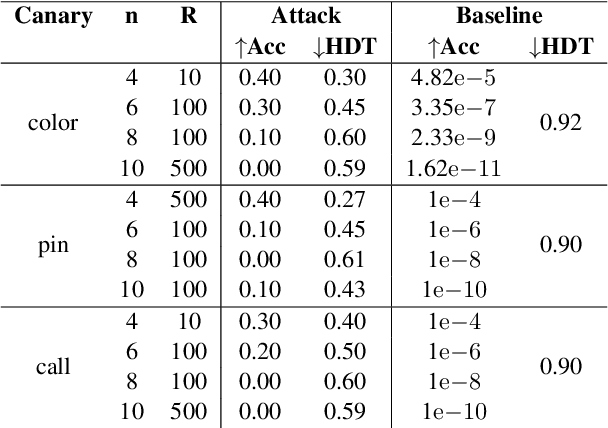
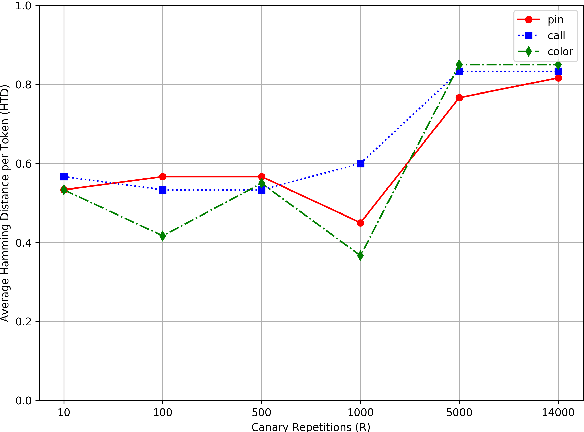
Natural Language Understanding (NLU) models can be trained on sensitive information such as phone numbers, zip-codes etc. Recent literature has focused on Model Inversion Attacks (ModIvA) that can extract training data from model parameters. In this work, we present a version of such an attack by extracting canaries inserted in NLU training data. In the attack, an adversary with open-box access to the model reconstructs the canaries contained in the model's training set. We evaluate our approach by performing text completion on canaries and demonstrate that by using the prefix (non-sensitive) tokens of the canary, we can generate the full canary. As an example, our attack is able to reconstruct a four digit code in the training dataset of the NLU model with a probability of 0.5 in its best configuration. As countermeasures, we identify several defense mechanisms that, when combined, effectively eliminate the risk of ModIvA in our experiments.
Acoustic To Articulatory Speech Inversion Using Multi-Resolution Spectro-Temporal Representations Of Speech Signals
Mar 11, 2022

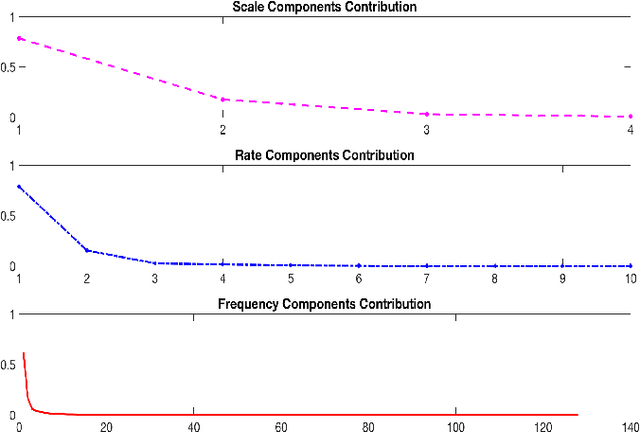

Multi-resolution spectro-temporal features of a speech signal represent how the brain perceives sounds by tuning cortical cells to different spectral and temporal modulations. These features produce a higher dimensional representation of the speech signals. The purpose of this paper is to evaluate how well the auditory cortex representation of speech signals contribute to estimate articulatory features of those corresponding signals. Since obtaining articulatory features from acoustic features of speech signals has been a challenging topic of interest for different speech communities, we investigate the possibility of using this multi-resolution representation of speech signals as acoustic features. We used U. of Wisconsin X-ray Microbeam (XRMB) database of clean speech signals to train a feed-forward deep neural network (DNN) to estimate articulatory trajectories of six tract variables. The optimal set of multi-resolution spectro-temporal features to train the model were chosen using appropriate scale and rate vector parameters to obtain the best performing model. Experiments achieved a correlation of 0.675 with ground-truth tract variables. We compared the performance of this speech inversion system with prior experiments conducted using Mel Frequency Cepstral Coefficients (MFCCs).
Harmonicity Plays a Critical Role in DNN Based Versus in Biologically-Inspired Monaural Speech Segregation Systems
Mar 08, 2022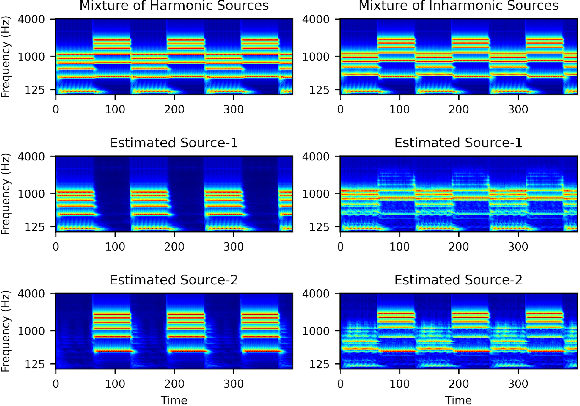
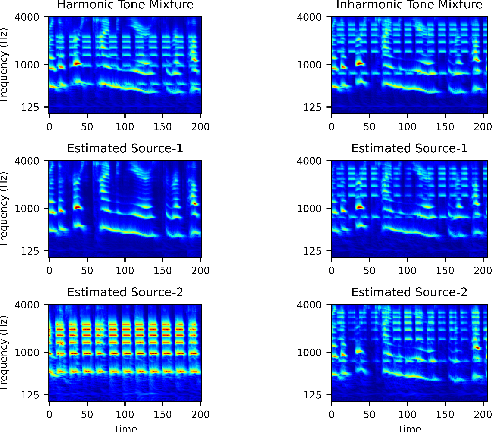
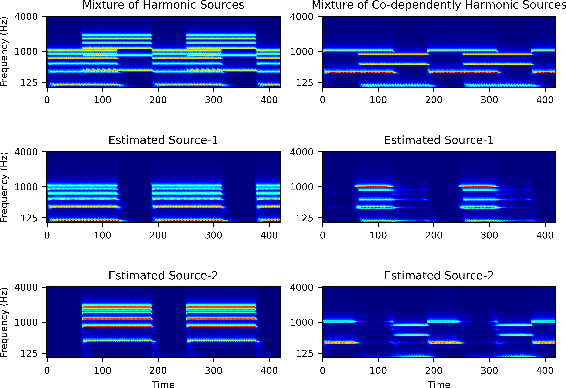
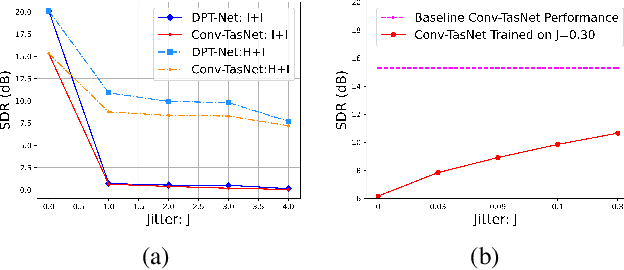
Recent advancements in deep learning have led to drastic improvements in speech segregation models. Despite their success and growing applicability, few efforts have been made to analyze the underlying principles that these networks learn to perform segregation. Here we analyze the role of harmonicity on two state-of-the-art Deep Neural Networks (DNN)-based models- Conv-TasNet and DPT-Net. We evaluate their performance with mixtures of natural speech versus slightly manipulated inharmonic speech, where harmonics are slightly frequency jittered. We find that performance deteriorates significantly if one source is even slightly harmonically jittered, e.g., an imperceptible 3% harmonic jitter degrades performance of Conv-TasNet from 15.4 dB to 0.70 dB. Training the model on inharmonic speech does not remedy this sensitivity, instead resulting in worse performance on natural speech mixtures, making inharmonicity a powerful adversarial factor in DNN models. Furthermore, additional analyses reveal that DNN algorithms deviate markedly from biologically inspired algorithms that rely primarily on timing cues and not harmonicity to segregate speech.