 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARES: Adaptive Red-Teaming and End-to-End Repair of Policy-Reward System
Apr 20, 2026Reinforcement Learning from Human Feedback (RLHF) is central to aligning Large Language Models (LLMs), yet it introduces a critical vulnerability: an imperfect Reward Model (RM) can become a single point of failure when it fails to penalize unsafe behaviors. While existing red-teaming approaches primarily target policy-level weaknesses, they overlook what we term systemic weaknesses cases where both the core LLM and the RM fail in tandem. We present ARES, a framework that systematically discovers and mitigates such dual vulnerabilities. ARES employs a ``Safety Mentor'' that dynamically composes semantically coherent adversarial prompts by combining structured component types (topics, personas, tactics, goals) and generates corresponding malicious and safe responses. This dual-targeting approach exposes weaknesses in both the core LLM and the RM simultaneously. Using the vulnerabilities gained, ARES implements a two-stage repair process: first fine-tuning the RM to better detect harmful content, then leveraging the improved RM to optimize the core model. Experiments across multiple adversarial safety benchmarks demonstrate that ARES substantially enhances safety robustness while preserving model capabilities, establishing a new paradigm for comprehensive RLHF safety alignment.
Defenses Against Prompt Attacks Learn Surface Heuristics
Jan 12, 2026Large language models (LLMs) are increasingly deployed in security-sensitive applications, where they must follow system- or developer-specified instructions that define the intended task behavior, while completing benign user requests. When adversarial instructions appear in user queries or externally retrieved content, models may override intended logic. Recent defenses rely on supervised fine-tuning with benign and malicious labels. Although these methods achieve high attack rejection rates, we find that they rely on narrow correlations in defense data rather than harmful intent, leading to systematic rejection of safe inputs. We analyze three recurring shortcut behaviors induced by defense fine-tuning. \emph{Position bias} arises when benign content placed later in a prompt is rejected at much higher rates; across reasoning benchmarks, suffix-task rejection rises from below \textbf{10\%} to as high as \textbf{90\%}. \emph{Token trigger bias} occurs when strings common in attack data raise rejection probability even in benign contexts; inserting a single trigger token increases false refusals by up to \textbf{50\%}. \emph{Topic generalization bias} reflects poor generalization beyond the defense data distribution, with defended models suffering test-time accuracy drops of up to \textbf{40\%}. These findings suggest that current prompt-injection defenses frequently respond to attack-like surface patterns rather than the underlying intent. We introduce controlled diagnostic datasets and a systematic evaluation across two base models and multiple defense pipelines, highlighting limitations of supervised fine-tuning for reliable LLM security.
Towards Safety Reasoning in LLMs: AI-agentic Deliberation for Policy-embedded CoT Data Creation
May 27, 2025Safety reasoning is a recent paradigm where LLMs reason over safety policies before generating responses, thereby mitigating limitations in existing safety measures such as over-refusal and jailbreak vulnerabilities. However, implementing this paradigm is challenging due to the resource-intensive process of creating high-quality policy-embedded chain-of-thought (CoT) datasets while ensuring reasoning remains accurate and free from hallucinations or policy conflicts. To tackle this, we propose AIDSAFE: Agentic Iterative Deliberation for Safety Reasoning, a novel data generation recipe that leverages multi-agent deliberation to iteratively expand reasoning on safety policies. A data refiner stage in AIDSAFE ensures high-quality outputs by eliminating repetitive, redundant, and deceptive thoughts. AIDSAFE-generated CoTs provide a strong foundation for supervised fine-tuning (SFT)-based safety training. Additionally, to address the need of preference data in alignment stages, such as DPO training, we introduce a supplemental recipe that uses belief augmentation to create distinct selected and rejected CoT samples. Our evaluations demonstrate that AIDSAFE-generated CoTs achieve superior policy adherence and reasoning quality. Consequently, we show that fine-tuning open-source LLMs on these CoTs can significantly improve safety generalization and jailbreak robustness while maintaining acceptable utility and over-refusal accuracy. AIDSAFE-generated CoT datasets can be found here: https://huggingface.co/datasets/AmazonScience/AIDSAFE
Evaluating Differentially Private Synthetic Data Generation in High-Stakes Domains
Oct 10, 2024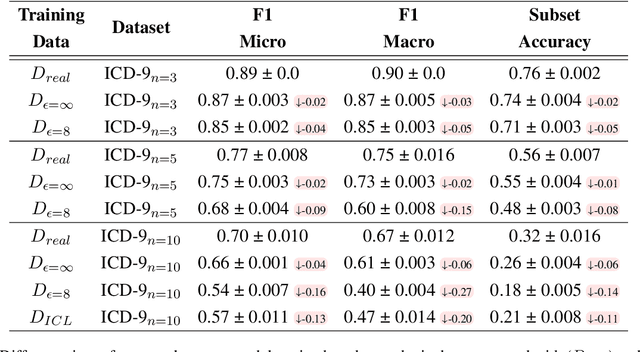


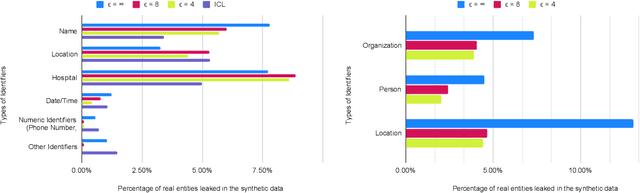
The difficulty of anonymizing text data hinders the development and deployment of NLP in high-stakes domains that involve private data, such as healthcare and social services. Poorly anonymized sensitive data cannot be easily shared with annotators or external researchers, nor can it be used to train public models. In this work, we explore the feasibility of using synthetic data generated from differentially private language models in place of real data to facilitate the development of NLP in these domains without compromising privacy. In contrast to prior work, we generate synthetic data for real high-stakes domains, and we propose and conduct use-inspired evaluations to assess data quality. Our results show that prior simplistic evaluations have failed to highlight utility, privacy, and fairness issues in the synthetic data. Overall, our work underscores the need for further improvements to synthetic data generation for it to be a viable way to enable privacy-preserving data sharing.
Attribute Controlled Fine-tuning for Large Language Models: A Case Study on Detoxification
Oct 07, 2024



We propose a constraint learning schema for fine-tuning Large Language Models (LLMs) with attribute control. Given a training corpus and control criteria formulated as a sequence-level constraint on model outputs, our method fine-tunes the LLM on the training corpus while enhancing constraint satisfaction with minimal impact on its utility and generation quality. Specifically, our approach regularizes the LLM training by penalizing the KL divergence between the desired output distribution, which satisfies the constraints, and the LLM's posterior. This regularization term can be approximated by an auxiliary model trained to decompose the sequence-level constraints into token-level guidance, allowing the term to be measured by a closed-form formulation. To further improve efficiency, we design a parallel scheme for concurrently updating both the LLM and the auxiliary model. We evaluate the empirical performance of our approach by controlling the toxicity when training an LLM. We show that our approach leads to an LLM that produces fewer inappropriate responses while achieving competitive performance on benchmarks and a toxicity detection task.
Tree-of-Traversals: A Zero-Shot Reasoning Algorithm for Augmenting Black-box Language Models with Knowledge Graphs
Jul 31, 2024



Knowledge graphs (KGs) complement Large Language Models (LLMs) by providing reliable, structured, domain-specific, and up-to-date external knowledge. However, KGs and LLMs are often developed separately and must be integrated after training. We introduce Tree-of-Traversals, a novel zero-shot reasoning algorithm that enables augmentation of black-box LLMs with one or more KGs. The algorithm equips a LLM with actions for interfacing a KG and enables the LLM to perform tree search over possible thoughts and actions to find high confidence reasoning paths. We evaluate on two popular benchmark datasets. Our results show that Tree-of-Traversals significantly improves performance on question answering and KG question answering tasks. Code is available at \url{https://github.com/amazon-science/tree-of-traversals}
Partial Federated Learning
Mar 03, 2024
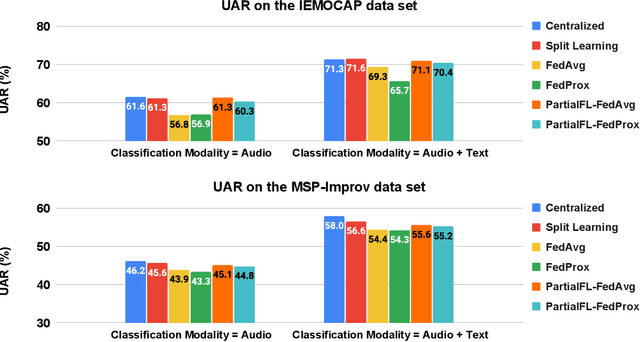
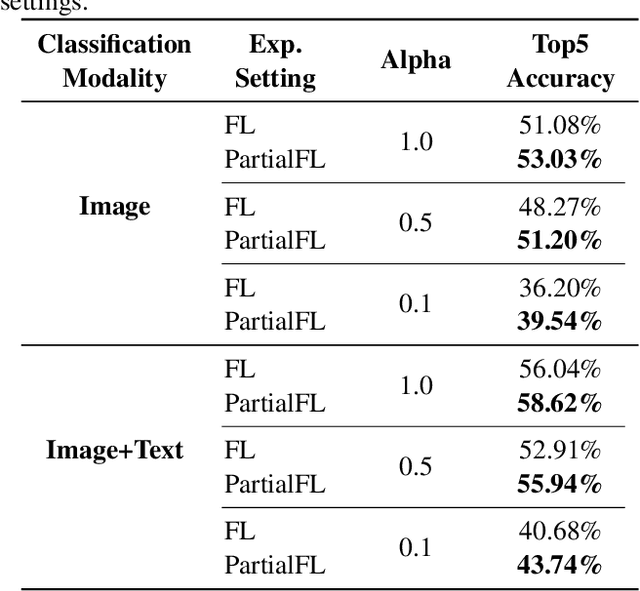
Federated Learning (FL) is a popular algorithm to train machine learning models on user data constrained to edge devices (for example, mobile phones) due to privacy concerns. Typically, FL is trained with the assumption that no part of the user data can be egressed from the edge. However, in many production settings, specific data-modalities/meta-data are limited to be on device while others are not. For example, in commercial SLU systems, it is typically desired to prevent transmission of biometric signals (such as audio recordings of the input prompt) to the cloud, but egress of locally (i.e. on the edge device) transcribed text to the cloud may be possible. In this work, we propose a new algorithm called Partial Federated Learning (PartialFL), where a machine learning model is trained using data where a subset of data modalities or their intermediate representations can be made available to the server. We further restrict our model training by preventing the egress of data labels to the cloud for better privacy, and instead use a contrastive learning based model objective. We evaluate our approach on two different multi-modal datasets and show promising results with our proposed approach.
On the steerability of large language models toward data-driven personas
Nov 08, 2023The recent surge in Large Language Model (LLM) related applications has led to a concurrent escalation in expectations for LLMs to accommodate a myriad of personas and encompass a broad spectrum of perspectives. An important first step towards addressing this demand is to align language models with specific personas, be it groups of users or individuals. Towards this goal, we first present a new conceptualization of a persona. Moving beyond the traditional reliance on demographics like age, gender, or political party affiliation, we introduce a data-driven persona definition methodology built on collaborative-filtering. In this methodology, users are embedded into a continuous vector space based on their opinions and clustered into cohorts that manifest coherent views across specific inquiries. This methodology allows for a more nuanced understanding of different latent social groups present in the overall population (as opposed to simply using demographic groups) and enhances the applicability of model steerability. Finally, we present an efficient method to steer LLMs towards a particular persona. We learn a soft-prompting model to map the continuous representation of users into sequences of virtual tokens which, when prepended to the LLM input, enables the LLM to produce responses aligned with a given user. Our results show that our steerability algorithm is superior in performance compared to a collection of baselines.
Coordinated Replay Sample Selection for Continual Federated Learning
Oct 23, 2023



Continual Federated Learning (CFL) combines Federated Learning (FL), the decentralized learning of a central model on a number of client devices that may not communicate their data, and Continual Learning (CL), the learning of a model from a continual stream of data without keeping the entire history. In CL, the main challenge is \textit{forgetting} what was learned from past data. While replay-based algorithms that keep a small pool of past training data are effective to reduce forgetting, only simple replay sample selection strategies have been applied to CFL in prior work, and no previous work has explored coordination among clients for better sample selection. To bridge this gap, we adapt a replay sample selection objective based on loss gradient diversity to CFL and propose a new relaxation-based selection of samples to optimize the objective. Next, we propose a practical algorithm to coordinate gradient-based replay sample selection across clients without communicating private data. We benchmark our coordinated and uncoordinated replay sample selection algorithms against random sampling-based baselines with language models trained on a large scale de-identified real-world text dataset. We show that gradient-based sample selection methods both boost performance and reduce forgetting compared to random sampling methods, with our coordination method showing gains early in the low replay size regime (when the budget for storing past data is small).
Holistic Survey of Privacy and Fairness in Machine Learning
Jul 28, 2023Privacy and fairness are two crucial pillars of responsible Artificial Intelligence (AI) and trustworthy Machine Learning (ML). Each objective has been independently studied in the literature with the aim of reducing utility loss in achieving them. Despite the significant interest attracted from both academia and industry, there remains an immediate demand for more in-depth research to unravel how these two objectives can be simultaneously integrated into ML models. As opposed to well-accepted trade-offs, i.e., privacy-utility and fairness-utility, the interrelation between privacy and fairness is not well-understood. While some works suggest a trade-off between the two objective functions, there are others that demonstrate the alignment of these functions in certain scenarios. To fill this research gap, we provide a thorough review of privacy and fairness in ML, including supervised, unsupervised, semi-supervised, and reinforcement learning. After examining and consolidating the literature on both objectives, we present a holistic survey on the impact of privacy on fairness, the impact of fairness on privacy, existing architectures, their interaction in application domains, and algorithms that aim to achieve both objectives while minimizing the utility sacrificed. Finally, we identify research challenges in achieving privacy and fairness concurrently in ML, particularly focusing on large language models.