 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Functional Memorization in Code Language Models
Jun 11, 2026Large language models (LLMs) are increasingly used to generate code at scale. Meanwhile, prior work has investigated whether training data may be recoverable from model outputs, by auditing the textual overlap between training examples and model generations. Code, however, can be functionally equivalent while textually dissimilar. In this work, we study functional memorization: extraction of functional logic beyond what verbatim metrics detect. We construct a counterfactual setup for Olmo-3-32B, comparing a midtrained model (exposed to target code) against a pretrained reference (not exposed). We prompt both models with Python function signatures and measure both textual and functional similarity (i.e., LLM-as-a-judge, execution-based). Our results show clear evidence of functional memorization, highlighting the need for auditing metrics that go beyond textual overlap.
SWAN: Semantic Watermarking with Abstract Meaning Representation
May 05, 2026We introduce SWAN (Semantic Watermarking with Abstract Meaning Representation), a novel framework that embeds watermark signatures into the semantic structure of a sentence using Abstract Meaning Representation (AMR). In contrast to existing watermarking methods, which typically encode signatures by adjusting token selection preferences during text generation, SWAN embeds the signature directly in the sentence's semantic representation. As the signature is encoded at the semantic structure level, any paraphrase that preserves meaning automatically preserves the signature. SWAN is training-free: watermark injection is achieved by prompting an LLM to generate sentences guided by a selected AMR template while maintaining contextual coherence, and detection uses an off-the-shelf AMR parser followed by a simple one-proportion z-test. Empirical evaluation on the RealNews benchmark shows SWAN matches state-of-the-art detection performance on unaltered watermarked text, while significantly improving robustness against paraphrasing, increasing detection AUC by up to 13.9 percentage points compared to prior methods. These results demonstrate that SWAN's approach of anchoring watermarks in AMR semantic structures provides a simple, effective, and prompt-based method for robust text provenance verification under paraphrasing, opening new avenues for semantic-level watermarking research.
Rethinking Visual Privacy: A Compositional Privacy Risk Framework for Severity Assessment with VLMs
Mar 23, 2026Existing visual privacy benchmarks largely treat privacy as a binary property, labeling images as private or non-private based on visible sensitive content. We argue that privacy is fundamentally compositional. Attributes that are benign in isolation may combine to produce severe privacy violations. We introduce the Compositional Privacy Risk Taxonomy (CPRT), a regulation-aware framework that organizes visual attributes according to standalone identifiability and compositional harm potential. CPRT defines four graded severity levels and is paired with an interpretable scoring function that assigns continuous privacy severity scores. We further construct a taxonomy-aligned dataset of 6.7K images and derive ground-truth compositional risk scores. By evaluating frontier and open-weight VLMs we find that frontier models align well with compositional severity when provided structured guidance, but systematically underestimate composition-driven risks. Smaller models struggle to internalize graded privacy reasoning. To bridge this gap, we introduce a deployable 8B supervised fine-tuned (SFT) model that closely matches frontier-level performance on compositional privacy assessment.
From Narrow Unlearning to Emergent Misalignment: Causes, Consequences, and Containment in LLMs
Nov 18, 2025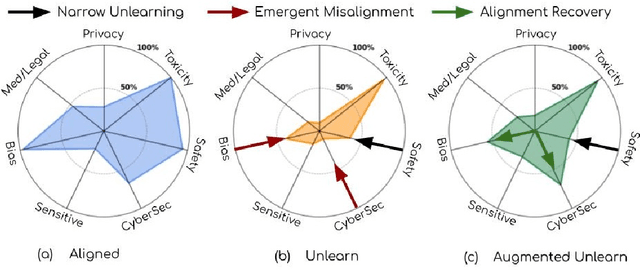
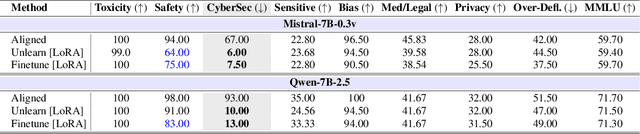
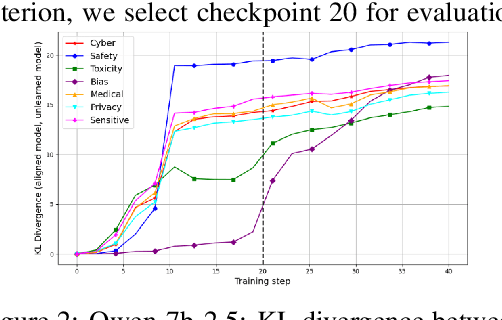
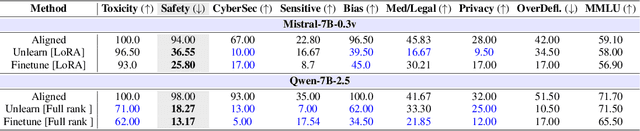
Recent work has shown that fine-tuning on insecure code data can trigger an emergent misalignment (EMA) phenomenon, where models generate malicious responses even to prompts unrelated to the original insecure code-writing task. Such cross-domain generalization of harmful behavior underscores the need for a deeper understanding of the algorithms, tasks, and datasets that induce emergent misalignment. In this work, we extend this study by demonstrating that emergent misalignment can also arise from narrow refusal unlearning in specific domains. We perform refusal unlearning on Cybersecurity and Safety concept, and evaluate EMA by monitoring refusal scores across seven responsible AI (RAI) domains, Cybersecurity, Safety, Toxicity, Bias, Sensitive Content, Medical/Legal, and Privacy. Our work shows that narrow domain unlearning can yield compliance responses for the targeted concept, however, it may also propagate EMA to unrelated domains. Among the two intervened concepts, Cybersecurity and Safety, we find that the safety concept can have larger EMA impact, i.e, causing lower refusal scores, across other unrelated domains such as bias. We observe this effect consistently across two model families, Mistral-7b-0.3v, and Qwen-7b-2.5. Further, we show that refusal unlearning augmented with cross-entropy loss function on a small set of retain data from the affected domains can largely, if not fully, restore alignment across the impacted domains while having lower refusal rate on the concept we perform unlearning on. To investigate the underlying causes of EMA, we analyze concept entanglements at the representation level via concept vectors. Our analysis reveals that concepts with higher representation similarity in earlier layers are more susceptible to EMA after intervention when the refusal stream is altered through targeted refusal unlearning.
BLUR: A Bi-Level Optimization Approach for LLM Unlearning
Jun 09, 2025Enabling large language models (LLMs) to unlearn knowledge and capabilities acquired during training has proven vital for ensuring compliance with data regulations and promoting ethical practices in generative AI. Although there are growing interests in developing various unlearning algorithms, it remains unclear how to best formulate the unlearning problem. The most popular formulation uses a weighted sum of forget and retain loss, but it often leads to performance degradation due to the inherent trade-off between forget and retain losses. In this work, we argue that it is important to model the hierarchical structure of the unlearning problem, where the forget problem (which \textit{unlearns} certain knowledge and/or capabilities) takes priority over the retain problem (which preserves model utility). This hierarchical structure naturally leads to a bi-level optimization formulation where the lower-level objective focuses on minimizing the forget loss, while the upper-level objective aims to maintain the model's utility. Based on this new formulation, we propose a novel algorithm, termed Bi-Level UnleaRning (\texttt{BLUR}), which not only possesses strong theoretical guarantees but more importantly, delivers superior performance. In particular, our extensive experiments demonstrate that \texttt{BLUR} consistently outperforms all the state-of-the-art algorithms across various unlearning tasks, models, and metrics. Codes are available at https://github.com/OptimAI-Lab/BLURLLMUnlearning.
Constrained Entropic Unlearning: A Primal-Dual Framework for Large Language Models
Jun 05, 2025Large Language Models (LLMs) deployed in real-world settings increasingly face the need to unlearn sensitive, outdated, or proprietary information. Existing unlearning methods typically formulate forgetting and retention as a regularized trade-off, combining both objectives into a single scalarized loss. This often leads to unstable optimization and degraded performance on retained data, especially under aggressive forgetting. We propose a new formulation of LLM unlearning as a constrained optimization problem: forgetting is enforced via a novel logit-margin flattening loss that explicitly drives the output distribution toward uniformity on a designated forget set, while retention is preserved through a hard constraint on a separate retain set. Compared to entropy-based objectives, our loss is softmax-free, numerically stable, and maintains non-vanishing gradients, enabling more efficient and robust optimization. We solve the constrained problem using a scalable primal-dual algorithm that exposes the trade-off between forgetting and retention through the dynamics of the dual variable. Evaluations on the TOFU and MUSE benchmarks across diverse LLM architectures demonstrate that our approach consistently matches or exceeds state-of-the-art baselines, effectively removing targeted information while preserving downstream utility.
Towards Safety Reasoning in LLMs: AI-agentic Deliberation for Policy-embedded CoT Data Creation
May 27, 2025Safety reasoning is a recent paradigm where LLMs reason over safety policies before generating responses, thereby mitigating limitations in existing safety measures such as over-refusal and jailbreak vulnerabilities. However, implementing this paradigm is challenging due to the resource-intensive process of creating high-quality policy-embedded chain-of-thought (CoT) datasets while ensuring reasoning remains accurate and free from hallucinations or policy conflicts. To tackle this, we propose AIDSAFE: Agentic Iterative Deliberation for Safety Reasoning, a novel data generation recipe that leverages multi-agent deliberation to iteratively expand reasoning on safety policies. A data refiner stage in AIDSAFE ensures high-quality outputs by eliminating repetitive, redundant, and deceptive thoughts. AIDSAFE-generated CoTs provide a strong foundation for supervised fine-tuning (SFT)-based safety training. Additionally, to address the need of preference data in alignment stages, such as DPO training, we introduce a supplemental recipe that uses belief augmentation to create distinct selected and rejected CoT samples. Our evaluations demonstrate that AIDSAFE-generated CoTs achieve superior policy adherence and reasoning quality. Consequently, we show that fine-tuning open-source LLMs on these CoTs can significantly improve safety generalization and jailbreak robustness while maintaining acceptable utility and over-refusal accuracy. AIDSAFE-generated CoT datasets can be found here: https://huggingface.co/datasets/AmazonScience/AIDSAFE
LUME: LLM Unlearning with Multitask Evaluations
Feb 20, 2025
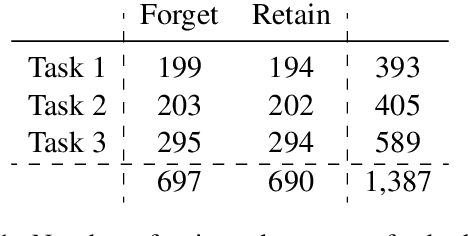
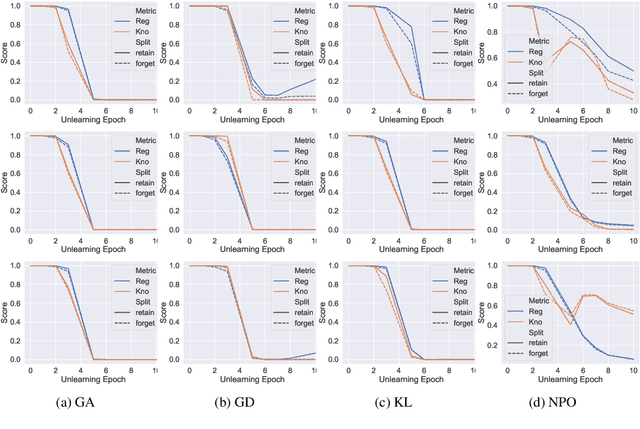
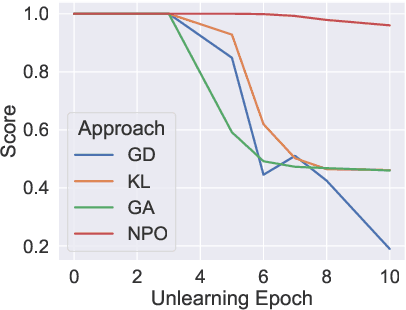
Unlearning aims to remove copyrighted, sensitive, or private content from large language models (LLMs) without a full retraining. In this work, we develop a multi-task unlearning benchmark (LUME) which features three tasks: (1) unlearn synthetically generated creative short novels, (2) unlearn synthetic biographies with sensitive information, and (3) unlearn a collection of public biographies. We further release two fine-tuned LLMs of 1B and 7B parameter sizes as the target models. We conduct detailed evaluations of several recently proposed unlearning algorithms and present results on carefully crafted metrics to understand their behavior and limitations.
Towards LLM Unlearning Resilient to Relearning Attacks: A Sharpness-Aware Minimization Perspective and Beyond
Feb 07, 2025The LLM unlearning technique has recently been introduced to comply with data regulations and address the safety and ethical concerns of LLMs by removing the undesired data-model influence. However, state-of-the-art unlearning methods face a critical vulnerability: they are susceptible to ``relearning'' the removed information from a small number of forget data points, known as relearning attacks. In this paper, we systematically investigate how to make unlearned models robust against such attacks. For the first time, we establish a connection between robust unlearning and sharpness-aware minimization (SAM) through a unified robust optimization framework, in an analogy to adversarial training designed to defend against adversarial attacks. Our analysis for SAM reveals that smoothness optimization plays a pivotal role in mitigating relearning attacks. Thus, we further explore diverse smoothing strategies to enhance unlearning robustness. Extensive experiments on benchmark datasets, including WMDP and MUSE, demonstrate that SAM and other smoothness optimization approaches consistently improve the resistance of LLM unlearning to relearning attacks. Notably, smoothness-enhanced unlearning also helps defend against (input-level) jailbreaking attacks, broadening our proposal's impact in robustifying LLM unlearning. Codes are available at https://github.com/OPTML-Group/Unlearn-Smooth.
Explaining and Improving Contrastive Decoding by Extrapolating the Probabilities of a Huge and Hypothetical LM
Nov 03, 2024



Contrastive decoding (CD) (Li et al., 2023) improves the next-token distribution of a large expert language model (LM) using a small amateur LM. Although CD is applied to various LMs and domains to enhance open-ended text generation, it is still unclear why CD often works well, when it could fail, and how we can make it better. To deepen our understanding of CD, we first theoretically prove that CD could be viewed as linearly extrapolating the next-token logits from a huge and hypothetical LM. We also highlight that the linear extrapolation could make CD unable to output the most obvious answers that have already been assigned high probabilities by the amateur LM. To overcome CD's limitation, we propose a new unsupervised decoding method called $\mathbf{A}$symptotic $\mathbf{P}$robability $\mathbf{D}$ecoding (APD). APD explicitly extrapolates the probability curves from the LMs of different sizes to infer the asymptotic probabilities from an infinitely large LM without inducing more inference costs than CD. In FactualityPrompts, an open-ended text generation benchmark, sampling using APD significantly boosts factuality in comparison to the CD sampling and its variants, and achieves state-of-the-art results for Pythia 6.9B and OPT 6.7B. Furthermore, in five commonsense QA datasets, APD is often significantly better than CD and achieves a similar effect of using a larger LLM. For example, the perplexity of APD on top of Pythia 6.9B is even lower than the perplexity of Pythia 12B in CommonsenseQA and LAMBADA.