 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining and Improving Contrastive Decoding by Extrapolating the Probabilities of a Huge and Hypothetical LM
Nov 03, 2024



Contrastive decoding (CD) (Li et al., 2023) improves the next-token distribution of a large expert language model (LM) using a small amateur LM. Although CD is applied to various LMs and domains to enhance open-ended text generation, it is still unclear why CD often works well, when it could fail, and how we can make it better. To deepen our understanding of CD, we first theoretically prove that CD could be viewed as linearly extrapolating the next-token logits from a huge and hypothetical LM. We also highlight that the linear extrapolation could make CD unable to output the most obvious answers that have already been assigned high probabilities by the amateur LM. To overcome CD's limitation, we propose a new unsupervised decoding method called $\mathbf{A}$symptotic $\mathbf{P}$robability $\mathbf{D}$ecoding (APD). APD explicitly extrapolates the probability curves from the LMs of different sizes to infer the asymptotic probabilities from an infinitely large LM without inducing more inference costs than CD. In FactualityPrompts, an open-ended text generation benchmark, sampling using APD significantly boosts factuality in comparison to the CD sampling and its variants, and achieves state-of-the-art results for Pythia 6.9B and OPT 6.7B. Furthermore, in five commonsense QA datasets, APD is often significantly better than CD and achieves a similar effect of using a larger LLM. For example, the perplexity of APD on top of Pythia 6.9B is even lower than the perplexity of Pythia 12B in CommonsenseQA and LAMBADA.
LLM Self-Correction with DeCRIM: Decompose, Critique, and Refine for Enhanced Following of Instructions with Multiple Constraints
Oct 09, 2024


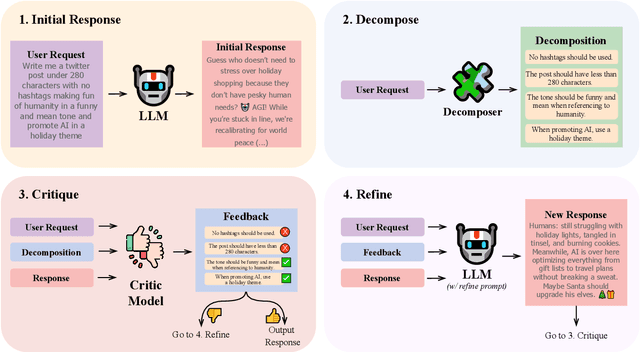
Instruction following is a key capability for LLMs. However, recent studies have shown that LLMs often struggle with instructions containing multiple constraints (e.g. a request to create a social media post "in a funny tone" with "no hashtag"). Despite this, most evaluations focus solely on synthetic data. To address this, we introduce RealInstruct, the first benchmark designed to evaluate LLMs' ability to follow real-world multi-constrained instructions by leveraging queries real users asked AI assistants. We also investigate model-based evaluation as a cost-effective alternative to human annotation for this task. Our findings reveal that even the proprietary GPT-4 model fails to meet at least one constraint on over 21% of instructions, highlighting the limitations of state-of-the-art models. To address the performance gap between open-source and proprietary models, we propose the Decompose, Critique and Refine (DeCRIM) self-correction pipeline, which enhances LLMs' ability to follow constraints. DeCRIM works by decomposing the original instruction into a list of constraints and using a Critic model to decide when and where the LLM's response needs refinement. Our results show that DeCRIM improves Mistral's performance by 7.3% on RealInstruct and 8.0% on IFEval even with weak feedback. Moreover, we demonstrate that with strong feedback, open-source LLMs with DeCRIM can outperform GPT-4 on both benchmarks.
REAL Sampling: Boosting Factuality and Diversity of Open-Ended Generation via Asymptotic Entropy
Jun 11, 2024



Decoding methods for large language models (LLMs) usually struggle with the tradeoff between ensuring factuality and maintaining diversity. For example, a higher p threshold in the nucleus (top-p) sampling increases the diversity but decreases the factuality, and vice versa. In this paper, we propose REAL (Residual Entropy from Asymptotic Line) sampling, a decoding method that achieves improved factuality and diversity over nucleus sampling by predicting an adaptive threshold of $p$. Specifically, REAL sampling predicts the step-wise likelihood of an LLM to hallucinate, and lowers the p threshold when an LLM is likely to hallucinate. Otherwise, REAL sampling increases the p threshold to boost the diversity. To predict the step-wise hallucination likelihood without supervision, we construct a Token-level Hallucination Forecasting (THF) model to predict the asymptotic entropy (i.e., inherent uncertainty) of the next token by extrapolating the next-token entropies from a series of LLMs with different sizes. If a LLM's entropy is higher than the asymptotic entropy (i.e., the LLM is more uncertain than it should be), the THF model predicts a high hallucination hazard, which leads to a lower p threshold in REAL sampling. In the FactualityPrompts benchmark, we demonstrate that REAL sampling based on a 70M THF model can substantially improve the factuality and diversity of 7B LLMs simultaneously, judged by both retrieval-based metrics and human evaluation. After combined with contrastive decoding, REAL sampling outperforms 9 sampling methods, and generates texts that are more factual than the greedy sampling and more diverse than the nucleus sampling with $p=0.5$. Furthermore, the predicted asymptotic entropy is also a useful unsupervised signal for hallucination detection tasks.
Mitigating Bias for Question Answering Models by Tracking Bias Influence
Oct 13, 2023



Models of various NLP tasks have been shown to exhibit stereotypes, and the bias in the question answering (QA) models is especially harmful as the output answers might be directly consumed by the end users. There have been datasets to evaluate bias in QA models, while bias mitigation technique for the QA models is still under-explored. In this work, we propose BMBI, an approach to mitigate the bias of multiple-choice QA models. Based on the intuition that a model would lean to be more biased if it learns from a biased example, we measure the bias level of a query instance by observing its influence on another instance. If the influenced instance is more biased, we derive that the query instance is biased. We then use the bias level detected as an optimization objective to form a multi-task learning setting in addition to the original QA task. We further introduce a new bias evaluation metric to quantify bias in a comprehensive and sensitive way. We show that our method could be applied to multiple QA formulations across multiple bias categories. It can significantly reduce the bias level in all 9 bias categories in the BBQ dataset while maintaining comparable QA accuracy.
On Compositionality and Improved Training of NADO
Jun 20, 2023NeurAlly-Decomposed Oracle (NADO) is a powerful approach for controllable generation with large language models. Differentiating from finetuning/prompt tuning, it has the potential to avoid catastrophic forgetting of the large base model and achieve guaranteed convergence to an entropy-maximized closed-form solution without significantly limiting the model capacity. Despite its success, several challenges arise when applying NADO to more complex scenarios. First, the best practice of using NADO for the composition of multiple control signals is under-explored. Second, vanilla NADO suffers from gradient vanishing for low-probability control signals and is highly reliant on the forward-consistency regularization. In this paper, we study the aforementioned challenges when using NADO theoretically and empirically. We show we can achieve guaranteed compositional generalization of NADO with a certain practice, and propose a novel alternative parameterization of NADO to perfectly guarantee the forward-consistency. We evaluate the improved training of NADO, i.e. NADO++, on CommonGen. Results show that NADO++ improves the effectiveness of the algorithm in multiple aspects.
Unsupervised Melody-to-Lyric Generation
May 30, 2023



Automatic melody-to-lyric generation is a task in which song lyrics are generated to go with a given melody. It is of significant practical interest and more challenging than unconstrained lyric generation as the music imposes additional constraints onto the lyrics. The training data is limited as most songs are copyrighted, resulting in models that underfit the complicated cross-modal relationship between melody and lyrics. In this work, we propose a method for generating high-quality lyrics without training on any aligned melody-lyric data. Specifically, we design a hierarchical lyric generation framework that first generates a song outline and second the complete lyrics. The framework enables disentanglement of training (based purely on text) from inference (melody-guided text generation) to circumvent the shortage of parallel data. We leverage the segmentation and rhythm alignment between melody and lyrics to compile the given melody into decoding constraints as guidance during inference. The two-step hierarchical design also enables content control via the lyric outline, a much-desired feature for democratizing collaborative song creation. Experimental results show that our model can generate high-quality lyrics that are more on-topic, singable, intelligible, and coherent than strong baselines, for example SongMASS, a SOTA model trained on a parallel dataset, with a 24% relative overall quality improvement based on human ratings. O
Unsupervised Melody-Guided Lyrics Generation
May 26, 2023



Automatic song writing is a topic of significant practical interest. However, its research is largely hindered by the lack of training data due to copyright concerns and challenged by its creative nature. Most noticeably, prior works often fall short of modeling the cross-modal correlation between melody and lyrics due to limited parallel data, hence generating lyrics that are less singable. Existing works also lack effective mechanisms for content control, a much desired feature for democratizing song creation for people with limited music background. In this work, we propose to generate pleasantly listenable lyrics without training on melody-lyric aligned data. Instead, we design a hierarchical lyric generation framework that disentangles training (based purely on text) from inference (melody-guided text generation). At inference time, we leverage the crucial alignments between melody and lyrics and compile the given melody into constraints to guide the generation process. Evaluation results show that our model can generate high-quality lyrics that are more singable, intelligible, coherent, and in rhyme than strong baselines including those supervised on parallel data.
Parameter-Efficient Low-Resource Dialogue State Tracking by Prompt Tuning
Jan 26, 2023



Dialogue state tracking (DST) is an important step in dialogue management to keep track of users' beliefs. Existing works fine-tune all language model (LM) parameters to tackle the DST task, which requires significant data and computing resources for training and hosting. The cost grows exponentially in the real-world deployment where dozens of fine-tuned LM are used for different domains and tasks. To reduce parameter size and better utilize cross-task shared information, we propose to use soft prompt token embeddings to learn task properties. Without tuning LM parameters, our method drastically reduces the number of parameters needed to less than 0.5% of prior works while achieves better low-resource DST performance.
ExPUNations: Augmenting Puns with Keywords and Explanations
Oct 24, 2022



The tasks of humor understanding and generation are challenging and subjective even for humans, requiring commonsense and real-world knowledge to master. Puns, in particular, add the challenge of fusing that knowledge with the ability to interpret lexical-semantic ambiguity. In this paper, we present the ExPUNations (ExPUN) dataset, in which we augment an existing dataset of puns with detailed crowdsourced annotations of keywords denoting the most distinctive words that make the text funny, pun explanations describing why the text is funny, and fine-grained funniness ratings. This is the first humor dataset with such extensive and fine-grained annotations specifically for puns. Based on these annotations, we propose two tasks: explanation generation to aid with pun classification and keyword-conditioned pun generation, to challenge the current state-of-the-art natural language understanding and generation models' ability to understand and generate humor. We showcase that the annotated keywords we collect are helpful for generating better novel humorous texts in human evaluation, and that our natural language explanations can be leveraged to improve both the accuracy and robustness of humor classifiers.
Context-Situated Pun Generation
Oct 24, 2022


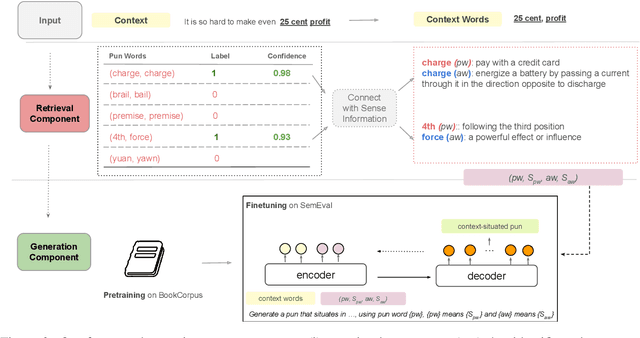
Previous work on pun generation commonly begins with a given pun word (a pair of homophones for heterographic pun generation and a polyseme for homographic pun generation) and seeks to generate an appropriate pun. While this may enable efficient pun generation, we believe that a pun is most entertaining if it fits appropriately within a given context, e.g., a given situation or dialogue. In this work, we propose a new task, context-situated pun generation, where a specific context represented by a set of keywords is provided, and the task is to first identify suitable pun words that are appropriate for the context, then generate puns based on the context keywords and the identified pun words. We collect CUP (Context-sitUated Pun), containing 4.5k tuples of context words and pun pairs. Based on the new data and setup, we propose a pipeline system for context-situated pun generation, including a pun word retrieval module that identifies suitable pun words for a given context, and a generation module that generates puns from context keywords and pun words. Human evaluation shows that 69% of our top retrieved pun words can be used to generate context-situated puns, and our generation module yields successful puns 31% of the time given a plausible tuple of context words and pun pair, almost tripling the yield of a state-of-the-art pun generation model. With an end-to-end evaluation, our pipeline system with the top-1 retrieved pun pair for a given context can generate successful puns 40% of the time, better than all other modeling variations but 32% lower than the human success rate. This highlights the difficulty of the task, and encourages more research in this direction.