 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Compositionality and Improved Training of NADO
Jun 20, 2023NeurAlly-Decomposed Oracle (NADO) is a powerful approach for controllable generation with large language models. Differentiating from finetuning/prompt tuning, it has the potential to avoid catastrophic forgetting of the large base model and achieve guaranteed convergence to an entropy-maximized closed-form solution without significantly limiting the model capacity. Despite its success, several challenges arise when applying NADO to more complex scenarios. First, the best practice of using NADO for the composition of multiple control signals is under-explored. Second, vanilla NADO suffers from gradient vanishing for low-probability control signals and is highly reliant on the forward-consistency regularization. In this paper, we study the aforementioned challenges when using NADO theoretically and empirically. We show we can achieve guaranteed compositional generalization of NADO with a certain practice, and propose a novel alternative parameterization of NADO to perfectly guarantee the forward-consistency. We evaluate the improved training of NADO, i.e. NADO++, on CommonGen. Results show that NADO++ improves the effectiveness of the algorithm in multiple aspects.
A Practical Framework for Relation Extraction with Noisy Labels Based on Doubly Transitional Loss
Apr 28, 2020

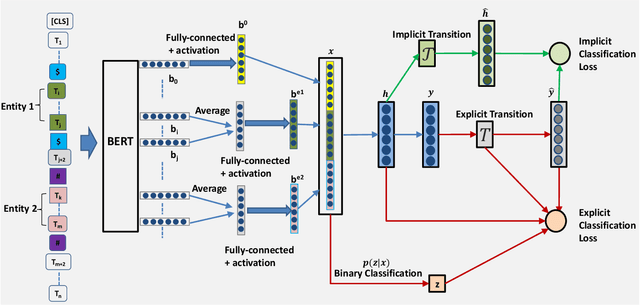

Either human annotation or rule based automatic labeling is an effective method to augment data for relation extraction. However, the inevitable wrong labeling problem for example by distant supervision may deteriorate the performance of many existing methods. To address this issue, we introduce a practical end-to-end deep learning framework, including a standard feature extractor and a novel noisy classifier with our proposed doubly transitional mechanism. One transition is basically parameterized by a non-linear transformation between hidden layers that implicitly represents the conversion between the true and noisy labels, and it can be readily optimized together with other model parameters. Another is an explicit probability transition matrix that captures the direct conversion between labels but needs to be derived from an EM algorithm. We conduct experiments on the NYT dataset and SemEval 2018 Task 7. The empirical results show comparable or better performance over state-of-the-art methods.
Enriching Pre-trained Language Model with Entity Information for Relation Classification
May 20, 2019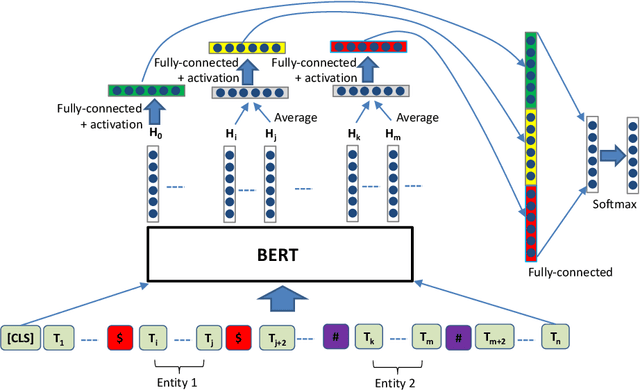

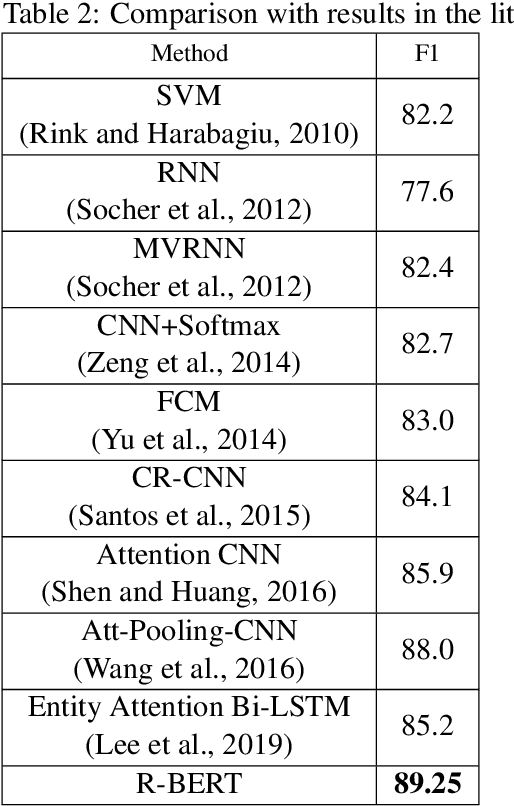

Relation classification is an important NLP task to extract relations between entities. The state-of-the-art methods for relation classification are primarily based on Convolutional or Recurrent Neural Networks. Recently, the pre-trained BERT model achieves very successful results in many NLP classification / sequence labeling tasks. Relation classification differs from those tasks in that it relies on information of both the sentence and the two target entities. In this paper, we propose a model that both leverages the pre-trained BERT language model and incorporates information from the target entities to tackle the relation classification task. We locate the target entities and transfer the information through the pre-trained architecture and incorporate the corresponding encoding of the two entities. We achieve significant improvement over the state-of-the-art method on the SemEval-2010 task 8 relational dataset.
Improving Distantly Supervised Relation Extraction with Neural Noise Converter and Conditional Optimal Selector
Nov 14, 2018

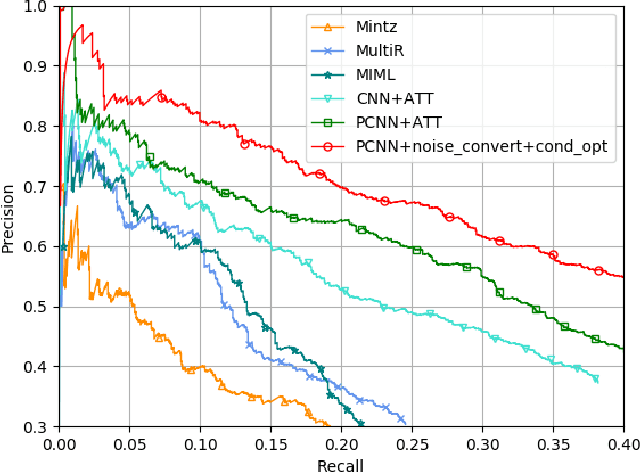
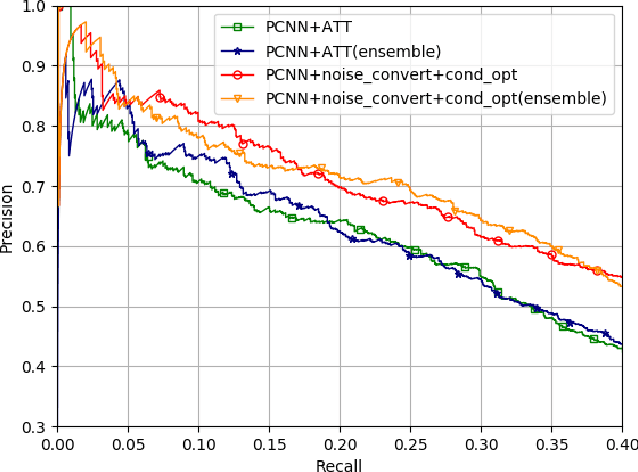
Distant supervised relation extraction has been successfully applied to large corpus with thousands of relations. However, the inevitable wrong labeling problem by distant supervision will hurt the performance of relation extraction. In this paper, we propose a method with neural noise converter to alleviate the impact of noisy data, and a conditional optimal selector to make proper prediction. Our noise converter learns the structured transition matrix on logit level and captures the property of distant supervised relation extraction dataset. The conditional optimal selector on the other hand helps to make proper prediction decision of an entity pair even if the group of sentences is overwhelmed by no-relation sentences. We conduct experiments on a widely used dataset and the results show significant improvement over competitive baseline methods.