 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetBurst: Event-Centric Forecasting of Bursty, Intermittent Time Series
Oct 25, 2025Forecasting on widely used benchmark time series data (e.g., ETT, Electricity, Taxi, and Exchange Rate, etc.) has favored smooth, seasonal series, but network telemetry time series -- traffic measurements at service, IP, or subnet granularity -- are instead highly bursty and intermittent, with heavy-tailed bursts and highly variable inactive periods. These properties place the latter in the statistical regimes made famous and popularized more than 20 years ago by B.~Mandelbrot. Yet forecasting such time series with modern-day AI architectures remains underexplored. We introduce NetBurst, an event-centric framework that reformulates forecasting as predicting when bursts occur and how large they are, using quantile-based codebooks and dual autoregressors. Across large-scale sets of production network telemetry time series and compared to strong baselines, such as Chronos, NetBurst reduces Mean Average Scaled Error (MASE) by 13--605x on service-level time series while preserving burstiness and producing embeddings that cluster 5x more cleanly than Chronos. In effect, our work highlights the benefits that modern AI can reap from leveraging Mandelbrot's pioneering studies for forecasting in bursty, intermittent, and heavy-tailed regimes, where its operational value for high-stakes decision making is of paramount interest.
NetworkGym: Reinforcement Learning Environments for Multi-Access Traffic Management in Network Simulation
Oct 30, 2024



Mobile devices such as smartphones, laptops, and tablets can often connect to multiple access networks (e.g., Wi-Fi, LTE, and 5G) simultaneously. Recent advancements facilitate seamless integration of these connections below the transport layer, enhancing the experience for apps that lack inherent multi-path support. This optimization hinges on dynamically determining the traffic distribution across networks for each device, a process referred to as \textit{multi-access traffic splitting}. This paper introduces \textit{NetworkGym}, a high-fidelity network environment simulator that facilitates generating multiple network traffic flows and multi-access traffic splitting. This simulator facilitates training and evaluating different RL-based solutions for the multi-access traffic splitting problem. Our initial explorations demonstrate that the majority of existing state-of-the-art offline RL algorithms (e.g. CQL) fail to outperform certain hand-crafted heuristic policies on average. This illustrates the urgent need to evaluate offline RL algorithms against a broader range of benchmarks, rather than relying solely on popular ones such as D4RL. We also propose an extension to the TD3+BC algorithm, named Pessimistic TD3 (PTD3), and demonstrate that it outperforms many state-of-the-art offline RL algorithms. PTD3's behavioral constraint mechanism, which relies on value-function pessimism, is theoretically motivated and relatively simple to implement.
Redefining Proactivity for Information Seeking Dialogue
Oct 20, 2024



Information-Seeking Dialogue (ISD) agents aim to provide accurate responses to user queries. While proficient in directly addressing user queries, these agents, as well as LLMs in general, predominantly exhibit reactive behavior, lacking the ability to generate proactive responses that actively engage users in sustained conversations. However, existing definitions of proactive dialogue in this context do not focus on how each response actively engages the user and sustains the conversation. Hence, we present a new definition of proactivity that focuses on enhancing the `proactiveness' of each generated response via the introduction of new information related to the initial query. To this end, we construct a proactive dialogue dataset comprising 2,000 single-turn conversations, and introduce several automatic metrics to evaluate response `proactiveness' which achieved high correlation with human annotation. Additionally, we introduce two innovative Chain-of-Thought (CoT) prompts, the 3-step CoT and the 3-in-1 CoT prompts, which consistently outperform standard prompts by up to 90% in the zero-shot setting.
netFound: Foundation Model for Network Security
Oct 25, 2023
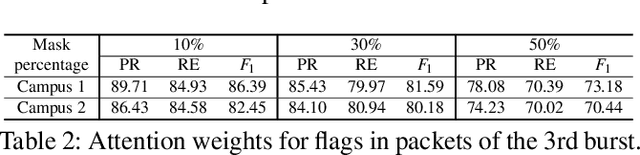


In ML for network security, traditional workflows rely on high-quality labeled data and manual feature engineering, but limited datasets and human expertise hinder feature selection, leading to models struggling to capture crucial relationships and generalize effectively. Inspired by recent advancements in ML application domains like GPT-4 and Vision Transformers, we have developed netFound, a foundational model for network security. This model undergoes pre-training using self-supervised algorithms applied to readily available unlabeled network packet traces. netFound's design incorporates hierarchical and multi-modal attributes of network traffic, effectively capturing hidden networking contexts, including application logic, communication protocols, and network conditions. With this pre-trained foundation in place, we can fine-tune netFound for a wide array of downstream tasks, even when dealing with low-quality, limited, and noisy labeled data. Our experiments demonstrate netFound's superiority over existing state-of-the-art ML-based solutions across three distinct network downstream tasks: traffic classification, network intrusion detection, and APT detection. Furthermore, we emphasize netFound's robustness against noisy and missing labels, as well as its ability to generalize across temporal variations and diverse network environments. Finally, through a series of ablation studies, we provide comprehensive insights into how our design choices enable netFound to more effectively capture hidden networking contexts, further solidifying its performance and utility in network security applications.
Mitigating Bias for Question Answering Models by Tracking Bias Influence
Oct 13, 2023



Models of various NLP tasks have been shown to exhibit stereotypes, and the bias in the question answering (QA) models is especially harmful as the output answers might be directly consumed by the end users. There have been datasets to evaluate bias in QA models, while bias mitigation technique for the QA models is still under-explored. In this work, we propose BMBI, an approach to mitigate the bias of multiple-choice QA models. Based on the intuition that a model would lean to be more biased if it learns from a biased example, we measure the bias level of a query instance by observing its influence on another instance. If the influenced instance is more biased, we derive that the query instance is biased. We then use the bias level detected as an optimization objective to form a multi-task learning setting in addition to the original QA task. We further introduce a new bias evaluation metric to quantify bias in a comprehensive and sensitive way. We show that our method could be applied to multiple QA formulations across multiple bias categories. It can significantly reduce the bias level in all 9 bias categories in the BBQ dataset while maintaining comparable QA accuracy.
On Compositionality and Improved Training of NADO
Jun 20, 2023NeurAlly-Decomposed Oracle (NADO) is a powerful approach for controllable generation with large language models. Differentiating from finetuning/prompt tuning, it has the potential to avoid catastrophic forgetting of the large base model and achieve guaranteed convergence to an entropy-maximized closed-form solution without significantly limiting the model capacity. Despite its success, several challenges arise when applying NADO to more complex scenarios. First, the best practice of using NADO for the composition of multiple control signals is under-explored. Second, vanilla NADO suffers from gradient vanishing for low-probability control signals and is highly reliant on the forward-consistency regularization. In this paper, we study the aforementioned challenges when using NADO theoretically and empirically. We show we can achieve guaranteed compositional generalization of NADO with a certain practice, and propose a novel alternative parameterization of NADO to perfectly guarantee the forward-consistency. We evaluate the improved training of NADO, i.e. NADO++, on CommonGen. Results show that NADO++ improves the effectiveness of the algorithm in multiple aspects.
In Search of netUnicorn: A Data-Collection Platform to Develop Generalizable ML Models for Network Security Problems
Jun 15, 2023



The remarkable success of the use of machine learning-based solutions for network security problems has been impeded by the developed ML models' inability to maintain efficacy when used in different network environments exhibiting different network behaviors. This issue is commonly referred to as the generalizability problem of ML models. The community has recognized the critical role that training datasets play in this context and has developed various techniques to improve dataset curation to overcome this problem. Unfortunately, these methods are generally ill-suited or even counterproductive in the network security domain, where they often result in unrealistic or poor-quality datasets. To address this issue, we propose an augmented ML pipeline that leverages explainable ML tools to guide the network data collection in an iterative fashion. To ensure the data's realism and quality, we require that the new datasets should be endogenously collected in this iterative process, thus advocating for a gradual removal of data-related problems to improve model generalizability. To realize this capability, we develop a data-collection platform, netUnicorn, that takes inspiration from the classic "hourglass" model and is implemented as its "thin waist" to simplify data collection for different learning problems from diverse network environments. The proposed system decouples data-collection intents from the deployment mechanisms and disaggregates these high-level intents into smaller reusable, self-contained tasks. We demonstrate how netUnicorn simplifies collecting data for different learning problems from multiple network environments and how the proposed iterative data collection improves a model's generalizability.
Parameter-Efficient Low-Resource Dialogue State Tracking by Prompt Tuning
Jan 26, 2023



Dialogue state tracking (DST) is an important step in dialogue management to keep track of users' beliefs. Existing works fine-tune all language model (LM) parameters to tackle the DST task, which requires significant data and computing resources for training and hosting. The cost grows exponentially in the real-world deployment where dozens of fine-tuned LM are used for different domains and tasks. To reduce parameter size and better utilize cross-task shared information, we propose to use soft prompt token embeddings to learn task properties. Without tuning LM parameters, our method drastically reduces the number of parameters needed to less than 0.5% of prior works while achieves better low-resource DST performance.
A dataset for resolving referring expressions in spoken dialogue via contextual query rewrites (CQR)
Apr 01, 2019
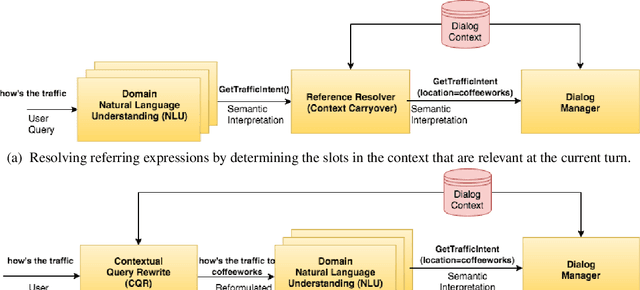
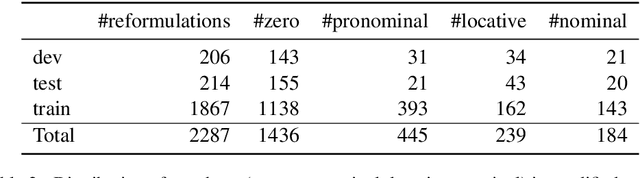
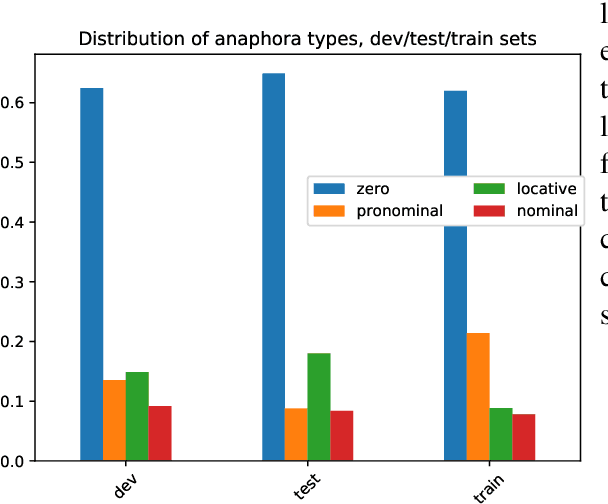
We present Contextual Query Rewrite (CQR) a dataset for multi-domain task-oriented spoken dialogue systems that is an extension of the Stanford dialog corpus (Eric et al., 2017a). While previous approaches have addressed the issue of diverse schemas by learning candidate transformations (Naik et al., 2018), we instead model the reference resolution task as a user query reformulation task, where the dialog state is serialized into a natural language query that can be executed by the downstream spoken language understanding system. In this paper, we describe our methodology for creating the query reformulation extension to the dialog corpus, and present an initial set of experiments to establish a baseline for the CQR task. We have released the corpus to the public [1] to support further research in this area.
Scaling Multi-Domain Dialogue State Tracking via Query Reformulation
Mar 29, 2019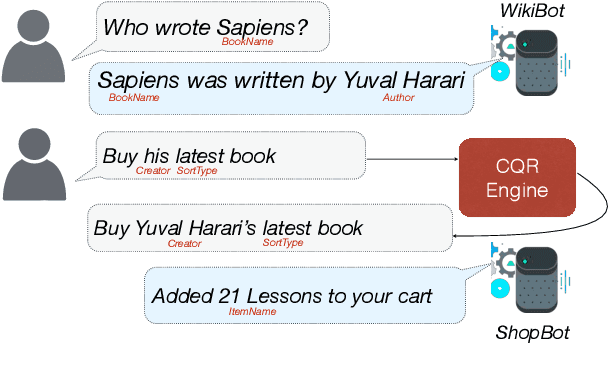
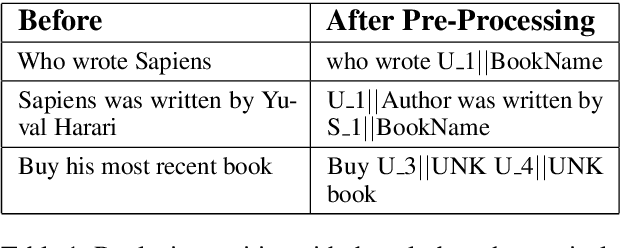

We present a novel approach to dialogue state tracking and referring expression resolution tasks. Successful contextual understanding of multi-turn spoken dialogues requires resolving referring expressions across turns and tracking the entities relevant to the conversation across turns. Tracking conversational state is particularly challenging in a multi-domain scenario when there exist multiple spoken language understanding (SLU) sub-systems, and each SLU sub-system operates on its domain-specific meaning representation. While previous approaches have addressed the disparate schema issue by learning candidate transformations of the meaning representation, in this paper, we instead model the reference resolution as a dialogue context-aware user query reformulation task -- the dialog state is serialized to a sequence of natural language tokens representing the conversation. We develop our model for query reformulation using a pointer-generator network and a novel multi-task learning setup. In our experiments, we show a significant improvement in absolute F1 on an internal as well as a, soon to be released, public benchmark respectively.