 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Autoencoders for Interpretable Emotion Control in Text-to-Speech
May 31, 2026Integrating large language models (LLMs) into text-to-speech (TTS) systems has improved speech expressiveness, yet interpretable emotional control remains challenging. Existing approaches primarily rely on external conditioning or global activation steering, offering limited insight into the internal representations underlying emotional control. In this work, we analyze emotion-related variation in the semantic hidden states of LLM-based TTS models using sparse autoencoders (SAEs) to identify sparse latent features. Our analysis shows that emotional variation is distributed across multiple sparse latent features, while intervening on a small subset enables interpretable emotion control. Building on this observation, we introduce a feature-level intervention framework for bidirectional emotion induction and suppression without modifying backbone parameters. We further show that distinct latent features are associated with specific acoustic attributes (e.g., pitch), suggesting that emotional expression arises from coordinated latent contributions rather than a single global shift. Empirically, steering these sparse latent features achieves comparable or superior emotion induction and suppression performance relative to global steering and existing TTS baselines.
Too Correct to Learn: Reinforcement Learning on Saturated Reasoning Data
Apr 20, 2026Reinforcement Learning (RL) enhances LLM reasoning, yet a paradox emerges as models scale: strong base models saturate standard benchmarks (e.g., MATH), yielding correct but homogeneous solutions. In such environments, the lack of failure cases causes the advantage signal in group-relative algorithms (e.g., GRPO) to vanish, driving policies into mode collapse. To address this, we propose Constrained Uniform Top-K Sampling (CUTS), a parameter-free decoding strategy enforcing structure-preserving exploration. Unlike standard sampling that follows model biases, CUTS flattens the local optimization landscape by sampling uniformly from constrained high-confidence candidates. We integrate this into Mixed-CUTS, a training framework synergizing exploitative and exploratory rollouts to amplify intra-group advantage variance. Experiments on Qwen3 models demonstrate that our approach prevents policy degeneration and significantly boosts out-of-domain generalization. Notably, Mixed-CUTS improves Pass@1 accuracy on the challenging AIME25 benchmark by up to 15.1% over standard GRPO, validating that maintaining diversity within the semantic manifold is critical for rigorous reasoning.
Locas: Your Models are Principled Initializers of Locally-Supported Parametric Memories
Feb 04, 2026In this paper, we aim to bridge test-time-training with a new type of parametric memory that can be flexibly offloaded from or merged into model parameters. We present Locas, a Locally-Supported parametric memory that shares the design of FFN blocks in modern transformers, allowing it to be flexibly permanentized into the model parameters while supporting efficient continual learning. We discuss two major variants of Locas: one with a conventional two-layer MLP design that has a clearer theoretical guarantee; the other one shares the same GLU-FFN structure with SOTA LLMs, and can be easily attached to existing models for both parameter-efficient and computation-efficient continual learning. Crucially, we show that proper initialization of such low-rank sideway-FFN-style memories -- performed in a principled way by reusing model parameters, activations and/or gradients -- is essential for fast convergence, improved generalization, and catastrophic forgetting prevention. We validate the proposed memory mechanism on the PG-19 whole-book language modeling and LoCoMo long-context dialogue question answering tasks. With only 0.02\% additional parameters in the lowest case, Locas-GLU is capable of storing the information from past context while maintaining a much smaller context window. In addition, we also test the model's general capability loss after memorizing the whole book with Locas, through comparative MMLU evaluation. Results show the promising ability of Locas to permanentize past context into parametric knowledge with minimized catastrophic forgetting of the model's existing internal knowledge.
Save the Good Prefix: Precise Error Penalization via Process-Supervised RL to Enhance LLM Reasoning
Jan 26, 2026Reinforcement learning (RL) has emerged as a powerful framework for improving the reasoning capabilities of large language models (LLMs). However, most existing RL approaches rely on sparse outcome rewards, which fail to credit correct intermediate steps in partially successful solutions. Process reward models (PRMs) offer fine-grained step-level supervision, but their scores are often noisy and difficult to evaluate. As a result, recent PRM benchmarks focus on a more objective capability: detecting the first incorrect step in a reasoning path. However, this evaluation target is misaligned with how PRMs are typically used in RL, where their step-wise scores are treated as raw rewards to maximize. To bridge this gap, we propose Verifiable Prefix Policy Optimization (VPPO), which uses PRMs only to localize the first error during RL. Given an incorrect rollout, VPPO partitions the trajectory into a verified correct prefix and an erroneous suffix based on the first error, rewarding the former while applying targeted penalties only after the detected mistake. This design yields stable, interpretable learning signals and improves credit assignment. Across multiple reasoning benchmarks, VPPO consistently outperforms sparse-reward RL and prior PRM-guided baselines on both Pass@1 and Pass@K.
Can LLMs Guide Their Own Exploration? Gradient-Guided Reinforcement Learning for LLM Reasoning
Dec 17, 2025
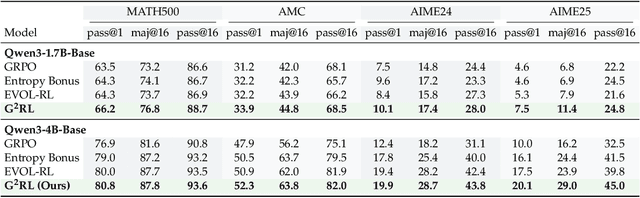
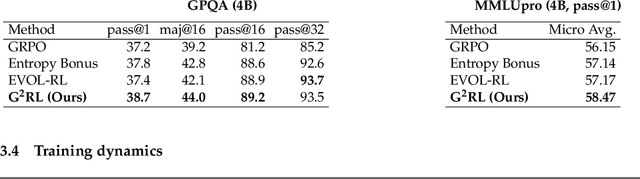
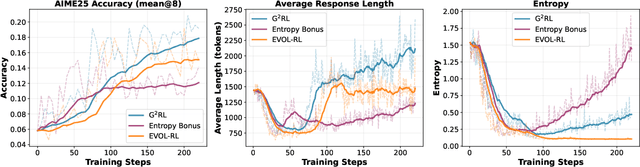
Reinforcement learning has become essential for strengthening the reasoning abilities of large language models, yet current exploration mechanisms remain fundamentally misaligned with how these models actually learn. Entropy bonuses and external semantic comparators encourage surface level variation but offer no guarantee that sampled trajectories differ in the update directions that shape optimization. We propose G2RL, a gradient guided reinforcement learning framework in which exploration is driven not by external heuristics but by the model own first order update geometry. For each response, G2RL constructs a sequence level feature from the model final layer sensitivity, obtainable at negligible cost from a standard forward pass, and measures how each trajectory would reshape the policy by comparing these features within a sampled group. Trajectories that introduce novel gradient directions receive a bounded multiplicative reward scaler, while redundant or off manifold updates are deemphasized, yielding a self referential exploration signal that is naturally aligned with PPO style stability and KL control. Across math and general reasoning benchmarks (MATH500, AMC, AIME24, AIME25, GPQA, MMLUpro) on Qwen3 base 1.7B and 4B models, G2RL consistently improves pass@1, maj@16, and pass@k over entropy based GRPO and external embedding methods. Analyzing the induced geometry, we find that G2RL expands exploration into substantially more orthogonal and often opposing gradient directions while maintaining semantic coherence, revealing that a policy own update space provides a far more faithful and effective basis for guiding exploration in large language model reinforcement learning.
Open-Domain Text Evaluation via Meta Distribution Modeling
Jun 20, 2023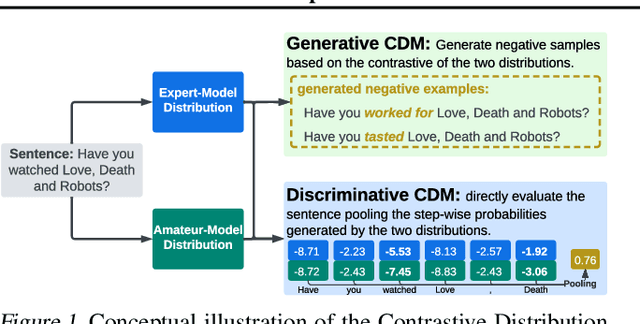

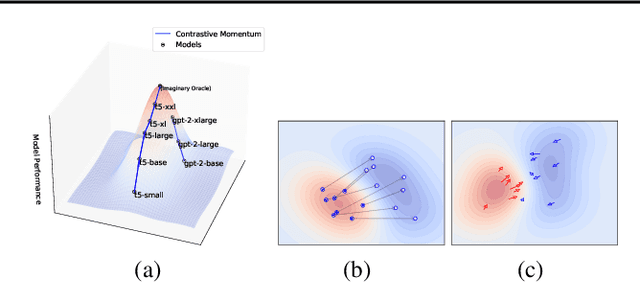
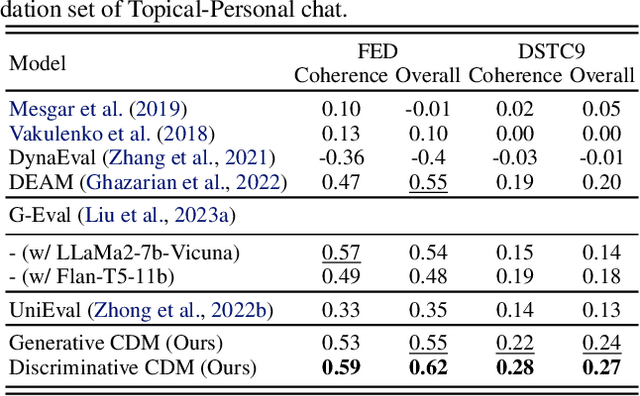
Recent advances in open-domain text generation models powered by large pre-trained language models (LLMs) have achieved remarkable performance. However, evaluating and controlling these models for desired attributes remains a challenge, as traditional reference-based metrics such as BLEU, ROUGE, and METEOR are insufficient for open-ended generation tasks. Similarly, while trainable discriminator-based evaluation metrics show promise, obtaining high-quality training data is a non-trivial task. In this paper, we introduce a novel approach to evaluate open-domain generation - the Meta-Distribution Methods (MDM). Drawing on the correlation between the rising parameter counts and the improving performance of LLMs, MDM creates a mapping from the contrast of two probabilistic distributions -- one known to be superior to the other -- to quality measures, which can be viewed as a distribution of distributions i.e. Meta-Distribution. We investigate MDM for open-domain text generation evaluation under two paradigms: 1) \emph{Generative} MDM, which leverages the Meta-Distribution Methods to generate in-domain negative samples for training discriminator-based metrics; 2) \emph{Discriminative} MDM, which directly uses distribution discrepancies between two language models for evaluation. Our experiments on multi-turn dialogue and factuality in abstractive summarization demonstrate that MDMs correlate better with human judgment than existing automatic evaluation metrics on both tasks, highlighting the strong performance and generalizability of such methods.
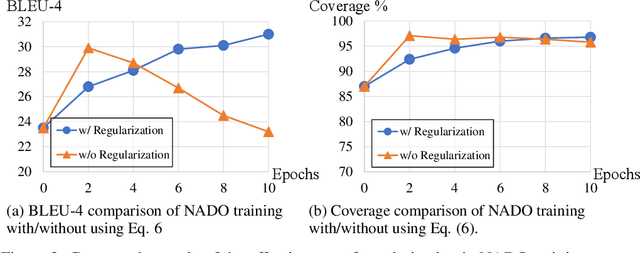
On Compositionality and Improved Training of NADO
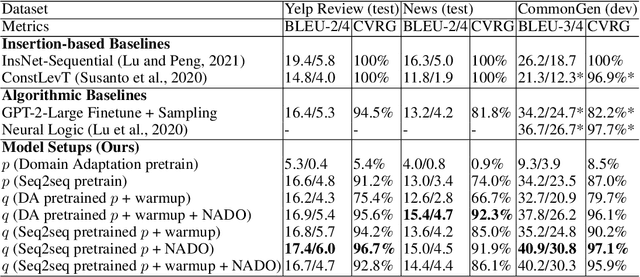
Jun 20, 2023NeurAlly-Decomposed Oracle (NADO) is a powerful approach for controllable generation with large language models. Differentiating from finetuning/prompt tuning, it has the potential to avoid catastrophic forgetting of the large base model and achieve guaranteed convergence to an entropy-maximized closed-form solution without significantly limiting the model capacity. Despite its success, several challenges arise when applying NADO to more complex scenarios. First, the best practice of using NADO for the composition of multiple control signals is under-explored. Second, vanilla NADO suffers from gradient vanishing for low-probability control signals and is highly reliant on the forward-consistency regularization. In this paper, we study the aforementioned challenges when using NADO theoretically and empirically. We show we can achieve guaranteed compositional generalization of NADO with a certain practice, and propose a novel alternative parameterization of NADO to perfectly guarantee the forward-consistency. We evaluate the improved training of NADO, i.e. NADO++, on CommonGen. Results show that NADO++ improves the effectiveness of the algorithm in multiple aspects.
Controllable Text Generation with Neurally-Decomposed Oracle
May 27, 2022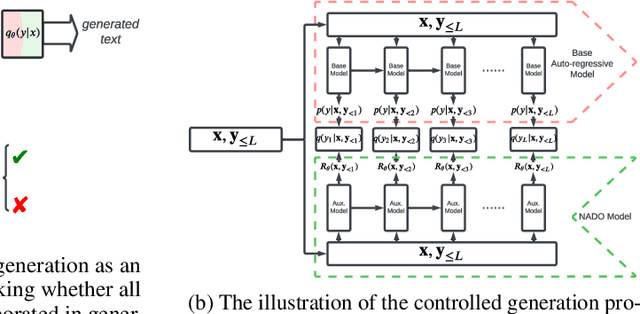

We propose a general and efficient framework to control auto-regressive generation models with NeurAlly-Decomposed Oracle (NADO). Given a pre-trained base language model and a sequence-level boolean oracle function, we propose to decompose the oracle function into token-level guidance to steer the base model in text generation. Specifically, the token-level guidance is approximated by a neural model trained with examples sampled from the base model, demanding no additional auxiliary labeled data. We present the closed-form optimal solution to incorporate the token-level guidance into the base model for controllable generation. We further provide a theoretical analysis of how the approximation quality of NADO affects the controllable generation results. Experiments conducted on two applications: (1) text generation with lexical constraints and (2) machine translation with formality control demonstrate that our framework efficiently guides the base model towards the given oracle while maintaining high generation quality.
Reinforcement Learning for Adaptive Video Compressive Sensing
May 18, 2021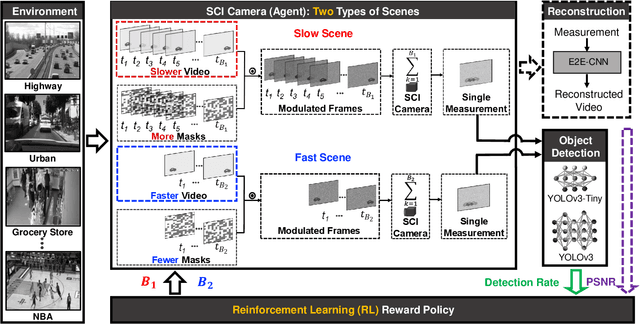


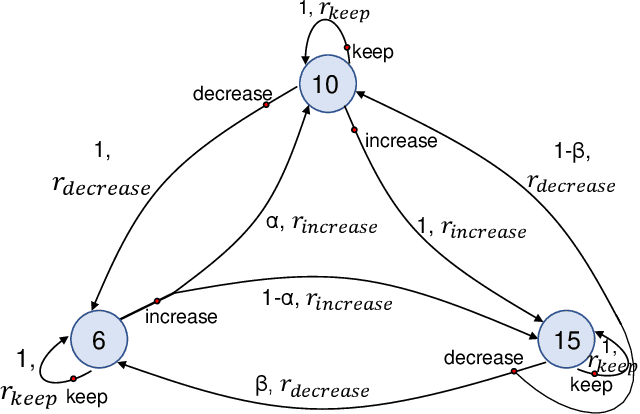
We apply reinforcement learning to video compressive sensing to adapt the compression ratio. Specifically, video snapshot compressive imaging (SCI), which captures high-speed video using a low-speed camera is considered in this work, in which multiple (B) video frames can be reconstructed from a snapshot measurement. One research gap in previous studies is how to adapt B in the video SCI system for different scenes. In this paper, we fill this gap utilizing reinforcement learning (RL). An RL model, as well as various convolutional neural networks for reconstruction, are learned to achieve adaptive sensing of video SCI systems. Furthermore, the performance of an object detection network using directly the video SCI measurements without reconstruction is also used to perform RL-based adaptive video compressive sensing. Our proposed adaptive SCI method can thus be implemented in low cost and real time. Our work takes the technology one step further towards real applications of video SCI.
On Efficient Training, Controllability and Compositional Generalization of Insertion-based Language Generators
Mar 01, 2021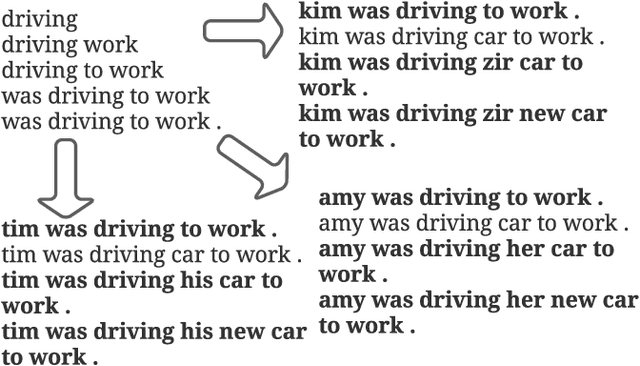

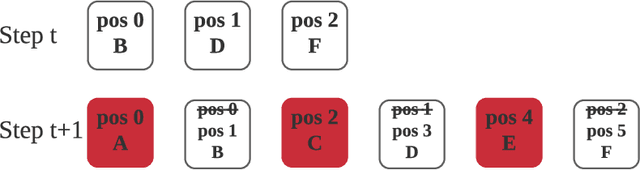
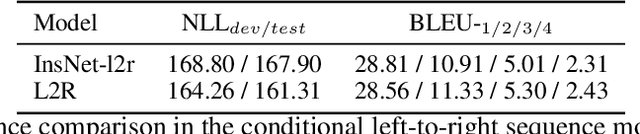
Auto-regressive language models with the left-to-right generation order have been a predominant paradigm for language generation. Recently, out-of-order text generation beyond the traditional left-to-right paradigm has attracted extensive attention, with a notable variation of insertion-based generation, where a model is used to gradually extend the context into a complete sentence purely with insertion operations. However, since insertion operations disturb the position information of each token, it is often believed that each step of the insertion-based likelihood estimation requires a bi-directional \textit{re-encoding} of the whole generated sequence. This computational overhead prohibits the model from scaling up to generate long, diverse texts such as stories, news articles, and reports. To address this issue, we propose InsNet, an insertion-based sequence model that can be trained as efficiently as traditional transformer decoders while maintaining the same performance as that with a bi-directional context encoder. We evaluate InsNet on story generation and CleVR-CoGENT captioning, showing the advantages of InsNet in several dimensions, including computational costs, generation quality, the ability to perfectly incorporate lexical controls, and better compositional generalization.