 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Domain Text Evaluation via Meta Distribution Modeling
Paper and Code
Jun 20, 2023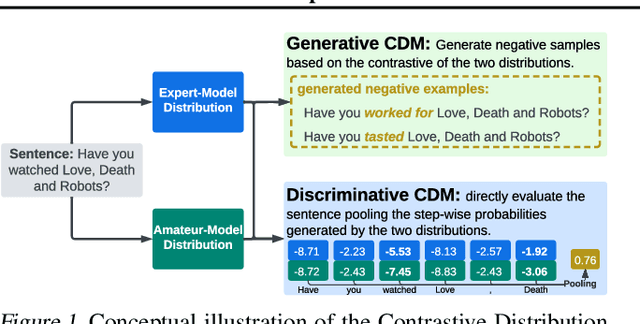

Recent advances in open-domain text generation models powered by large pre-trained language models (LLMs) have achieved remarkable performance. However, evaluating and controlling these models for desired attributes remains a challenge, as traditional reference-based metrics such as BLEU, ROUGE, and METEOR are insufficient for open-ended generation tasks. Similarly, while trainable discriminator-based evaluation metrics show promise, obtaining high-quality training data is a non-trivial task. In this paper, we introduce a novel approach to evaluate open-domain generation - the Meta-Distribution Methods (MDM). Drawing on the correlation between the rising parameter counts and the improving performance of LLMs, MDM creates a mapping from the contrast of two probabilistic distributions -- one known to be superior to the other -- to quality measures, which can be viewed as a distribution of distributions i.e. Meta-Distribution. We investigate MDM for open-domain text generation evaluation under two paradigms: 1) \emph{Generative} MDM, which leverages the Meta-Distribution Methods to generate in-domain negative samples for training discriminator-based metrics; 2) \emph{Discriminative} MDM, which directly uses distribution discrepancies between two language models for evaluation. Our experiments on multi-turn dialogue and factuality in abstractive summarization demonstrate that MDMs correlate better with human judgment than existing automatic evaluation metrics on both tasks, highlighting the strong performance and generalizability of such methods.