 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Reinforcement: When Reward Is Sparse, It's Better to Be Dense
Oct 08, 2025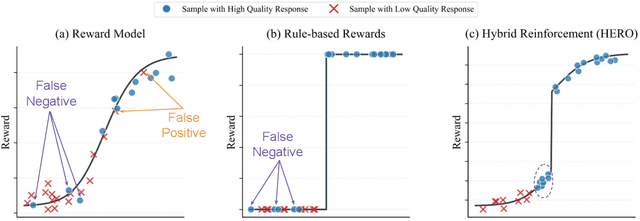
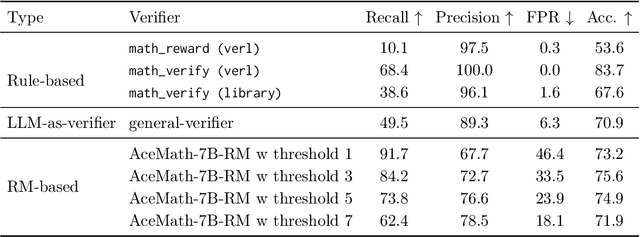
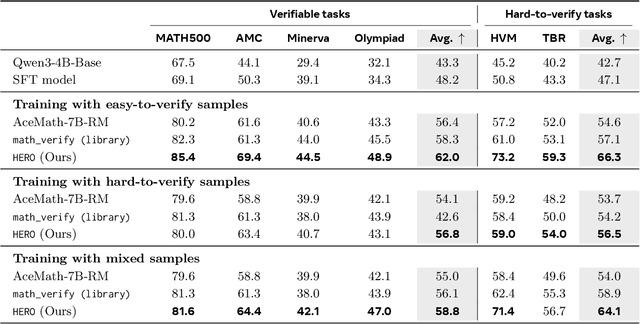
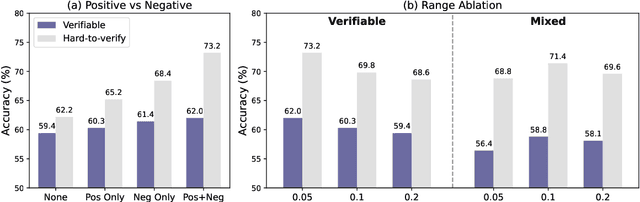
Post-training for reasoning of large language models (LLMs) increasingly relies on verifiable rewards: deterministic checkers that provide 0-1 correctness signals. While reliable, such binary feedback is brittle--many tasks admit partially correct or alternative answers that verifiers under-credit, and the resulting all-or-nothing supervision limits learning. Reward models offer richer, continuous feedback, which can serve as a complementary supervisory signal to verifiers. We introduce HERO (Hybrid Ensemble Reward Optimization), a reinforcement learning framework that integrates verifier signals with reward-model scores in a structured way. HERO employs stratified normalization to bound reward-model scores within verifier-defined groups, preserving correctness while refining quality distinctions, and variance-aware weighting to emphasize challenging prompts where dense signals matter most. Across diverse mathematical reasoning benchmarks, HERO consistently outperforms RM-only and verifier-only baselines, with strong gains on both verifiable and hard-to-verify tasks. Our results show that hybrid reward design retains the stability of verifiers while leveraging the nuance of reward models to advance reasoning.
CoT-Self-Instruct: Building high-quality synthetic prompts for reasoning and non-reasoning tasks
Jul 31, 2025We propose CoT-Self-Instruct, a synthetic data generation method that instructs LLMs to first reason and plan via Chain-of-Thought (CoT) based on the given seed tasks, and then to generate a new synthetic prompt of similar quality and complexity for use in LLM training, followed by filtering for high-quality data with automatic metrics. In verifiable reasoning, our synthetic data significantly outperforms existing training datasets, such as s1k and OpenMathReasoning, across MATH500, AMC23, AIME24 and GPQA-Diamond. For non-verifiable instruction-following tasks, our method surpasses the performance of human or standard self-instruct prompts on both AlpacaEval 2.0 and Arena-Hard.
Bridging Offline and Online Reinforcement Learning for LLMs
Jun 26, 2025We investigate the effectiveness of reinforcement learning methods for finetuning large language models when transitioning from offline to semi-online to fully online regimes for both verifiable and non-verifiable tasks. Our experiments cover training on verifiable math as well as non-verifiable instruction following with a set of benchmark evaluations for both. Across these settings, we extensively compare online and semi-online Direct Preference Optimization and Group Reward Policy Optimization objectives, and surprisingly find similar performance and convergence between these variants, which all strongly outperform offline methods. We provide a detailed analysis of the training dynamics and hyperparameter selection strategies to achieve optimal results. Finally, we show that multi-tasking with verifiable and non-verifiable rewards jointly yields improved performance across both task types.
J1: Incentivizing Thinking in LLM-as-a-Judge via Reinforcement Learning
May 15, 2025The progress of AI is bottlenecked by the quality of evaluation, and powerful LLM-as-a-Judge models have proved to be a core solution. Improved judgment ability is enabled by stronger chain-of-thought reasoning, motivating the need to find the best recipes for training such models to think. In this work we introduce J1, a reinforcement learning approach to training such models. Our method converts both verifiable and non-verifiable prompts to judgment tasks with verifiable rewards that incentivize thinking and mitigate judgment bias. In particular, our approach outperforms all other existing 8B or 70B models when trained at those sizes, including models distilled from DeepSeek-R1. J1 also outperforms o1-mini, and even R1 on some benchmarks, despite training a smaller model. We provide analysis and ablations comparing Pairwise-J1 vs Pointwise-J1 models, offline vs online training recipes, reward strategies, seed prompts, and variations in thought length and content. We find that our models make better judgments by learning to outline evaluation criteria, comparing against self-generated reference answers, and re-evaluating the correctness of model responses.
Multi-Token Attention
Apr 01, 2025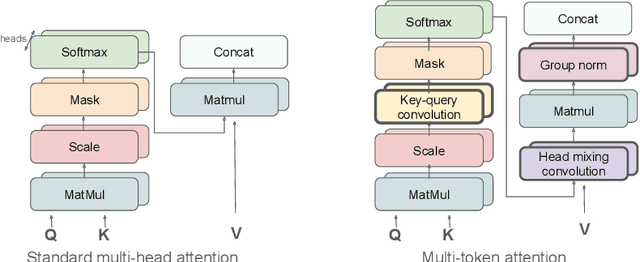

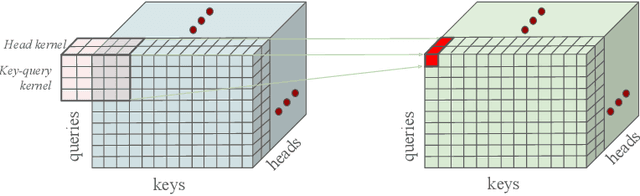
Soft attention is a critical mechanism powering LLMs to locate relevant parts within a given context. However, individual attention weights are determined by the similarity of only a single query and key token vector. This "single token attention" bottlenecks the amount of information used in distinguishing a relevant part from the rest of the context. To address this issue, we propose a new attention method, Multi-Token Attention (MTA), which allows LLMs to condition their attention weights on multiple query and key vectors simultaneously. This is achieved by applying convolution operations over queries, keys and heads, allowing nearby queries and keys to affect each other's attention weights for more precise attention. As a result, our method can locate relevant context using richer, more nuanced information that can exceed a single vector's capacity. Through extensive evaluations, we demonstrate that MTA achieves enhanced performance on a range of popular benchmarks. Notably, it outperforms Transformer baseline models on standard language modeling tasks, and on tasks that require searching for information within long contexts, where our method's ability to leverage richer information proves particularly beneficial.
Learning to Plan & Reason for Evaluation with Thinking-LLM-as-a-Judge
Jan 30, 2025



LLM-as-a-Judge models generate chain-of-thought (CoT) sequences intended to capture the step-bystep reasoning process that underlies the final evaluation of a response. However, due to the lack of human annotated CoTs for evaluation, the required components and structure of effective reasoning traces remain understudied. Consequently, previous approaches often (1) constrain reasoning traces to hand-designed components, such as a list of criteria, reference answers, or verification questions and (2) structure them such that planning is intertwined with the reasoning for evaluation. In this work, we propose EvalPlanner, a preference optimization algorithm for Thinking-LLM-as-a-Judge that first generates an unconstrained evaluation plan, followed by its execution, and then the final judgment. In a self-training loop, EvalPlanner iteratively optimizes over synthetically constructed evaluation plans and executions, leading to better final verdicts. Our method achieves a new state-of-the-art performance for generative reward models on RewardBench (with a score of 93.9), despite being trained on fewer amount of, and synthetically generated, preference pairs. Additional experiments on other benchmarks like RM-Bench, JudgeBench, and FollowBenchEval further highlight the utility of both planning and reasoning for building robust LLM-as-a-Judge reasoning models.
Calibrate to Discriminate: Improve In-Context Learning with Label-Free Comparative Inference
Oct 03, 2024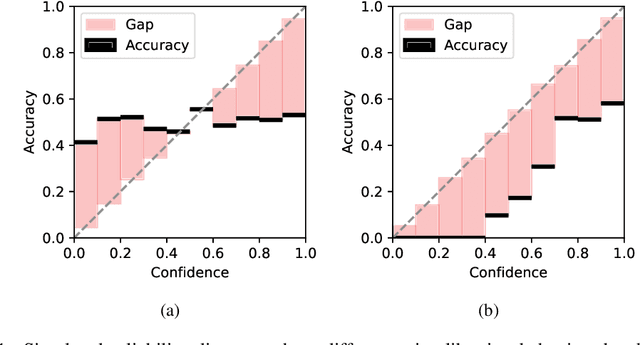
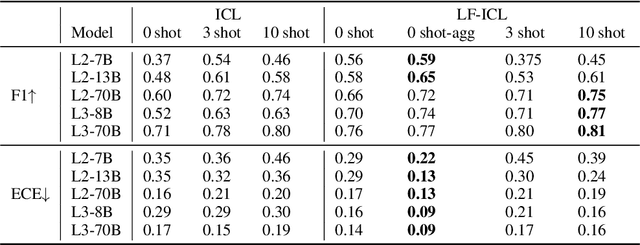
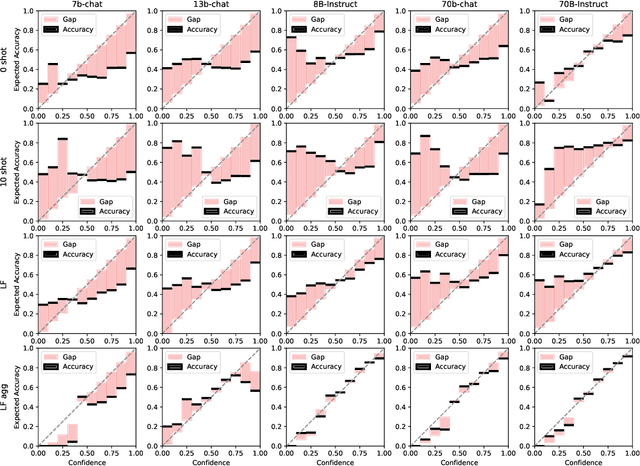
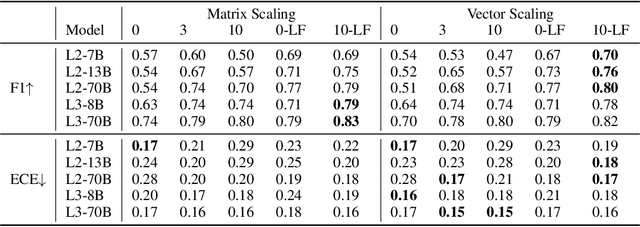
While in-context learning with large language models (LLMs) has shown impressive performance, we have discovered a unique miscalibration behavior where both correct and incorrect predictions are assigned the same level of confidence. We refer to this phenomenon as indiscriminate miscalibration. We found that traditional calibration metrics, such as Expected Calibrated Errors (ECEs), are unable to capture this behavior effectively. To address this issue, we propose new metrics to measure the severity of indiscriminate miscalibration. Additionally, we develop a novel in-context comparative inference method to alleviate miscalibrations and improve classification performance. Through extensive experiments on five datasets, we demonstrate that our proposed method can achieve more accurate and calibrated predictions compared to regular zero-shot and few-shot prompting.
Self-Taught Evaluators
Aug 05, 2024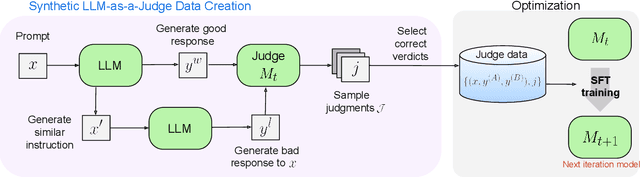
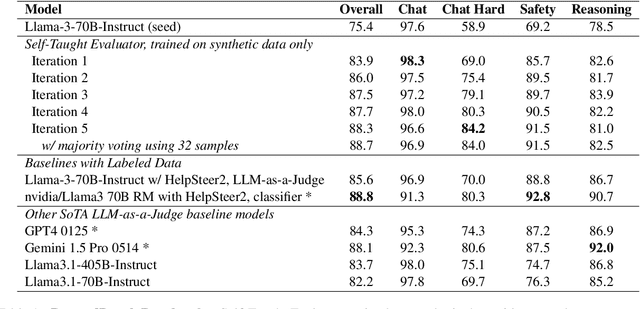

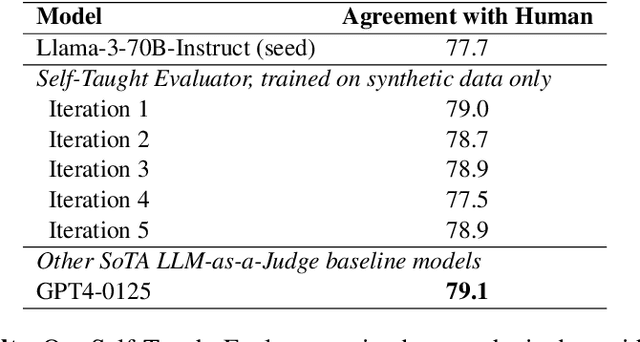
Model-based evaluation is at the heart of successful model development -- as a reward model for training, and as a replacement for human evaluation. To train such evaluators, the standard approach is to collect a large amount of human preference judgments over model responses, which is costly and the data becomes stale as models improve. In this work, we present an approach that aims to im-prove evaluators without human annotations, using synthetic training data only. Starting from unlabeled instructions, our iterative self-improvement scheme generates contrasting model outputs and trains an LLM-as-a-Judge to produce reasoning traces and final judgments, repeating this training at each new iteration using the improved predictions. Without any labeled preference data, our Self-Taught Evaluator can improve a strong LLM (Llama3-70B-Instruct) from 75.4 to 88.3 (88.7 with majority vote) on RewardBench. This outperforms commonly used LLM judges such as GPT-4 and matches the performance of the top-performing reward models trained with labeled examples.
Contextual Position Encoding: Learning to Count What's Important
May 29, 2024

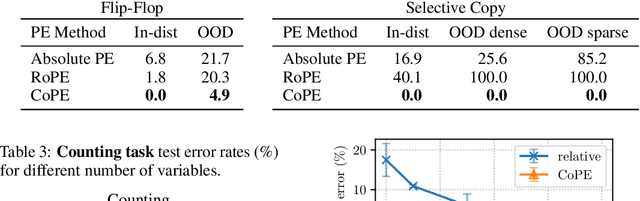

The attention mechanism is a critical component of Large Language Models (LLMs) that allows tokens in a sequence to interact with each other, but is order-invariant. Incorporating position encoding (PE) makes it possible to address by position, such as attending to the i-th token. However, current PE methods use token counts to derive position, and thus cannot generalize to higher levels of abstraction, such as attending to the i-th sentence. In this paper, we propose a new position encoding method, Contextual Position Encoding (CoPE), that allows positions to be conditioned on context by incrementing position only on certain tokens determined by the model. This allows more general position addressing such as attending to the $i$-th particular word, noun, or sentence. We show that CoPE can solve the selective copy, counting and Flip-Flop tasks where popular position embeddings fail, and improves perplexity on language modeling and coding tasks.
Efficient Tool Use with Chain-of-Abstraction Reasoning
Jan 30, 2024



To achieve faithful reasoning that aligns with human expectations, large language models (LLMs) need to ground their reasoning to real-world knowledge (e.g., web facts, math and physical rules). Tools help LLMs access this external knowledge, but there remains challenges for fine-tuning LLM agents (e.g., Toolformer) to invoke tools in multi-step reasoning problems, where inter-connected tool calls require holistic and efficient tool usage planning. In this work, we propose a new method for LLMs to better leverage tools in multi-step reasoning. Our method, Chain-of-Abstraction (CoA), trains LLMs to first decode reasoning chains with abstract placeholders, and then call domain tools to reify each reasoning chain by filling in specific knowledge. This planning with abstract chains enables LLMs to learn more general reasoning strategies, which are robust to shifts of domain knowledge (e.g., math results) relevant to different reasoning questions. It also allows LLMs to perform decoding and calling of external tools in parallel, which avoids the inference delay caused by waiting for tool responses. In mathematical reasoning and Wiki QA domains, we show that our method consistently outperforms previous chain-of-thought and tool-augmented baselines on both in-distribution and out-of-distribution test sets, with an average ~6% absolute QA accuracy improvement. LLM agents trained with our method also show more efficient tool use, with inference speed being on average ~1.4x faster than baseline tool-augmented LLMs.