 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrate to Discriminate: Improve In-Context Learning with Label-Free Comparative Inference
Oct 03, 2024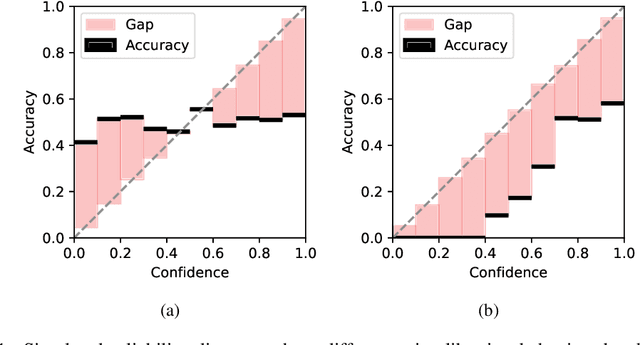
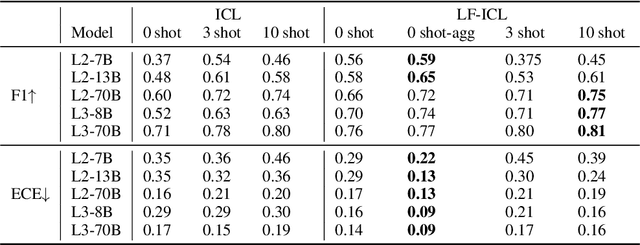
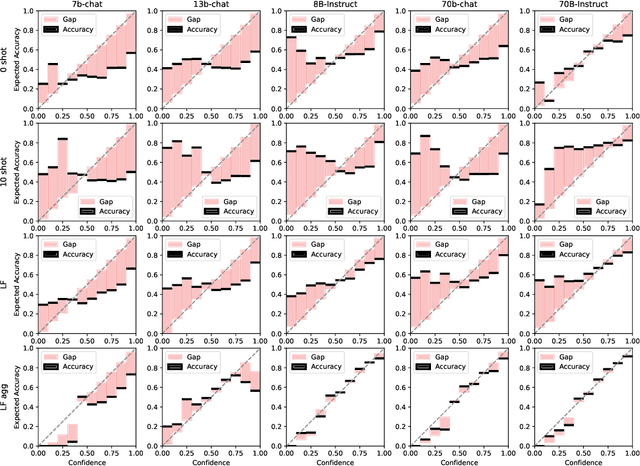
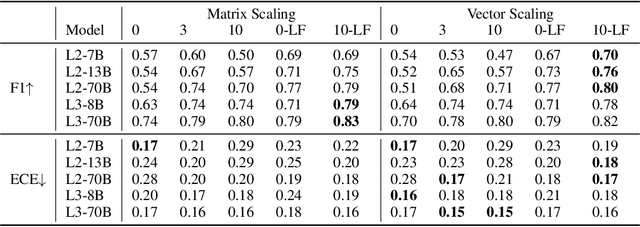
While in-context learning with large language models (LLMs) has shown impressive performance, we have discovered a unique miscalibration behavior where both correct and incorrect predictions are assigned the same level of confidence. We refer to this phenomenon as indiscriminate miscalibration. We found that traditional calibration metrics, such as Expected Calibrated Errors (ECEs), are unable to capture this behavior effectively. To address this issue, we propose new metrics to measure the severity of indiscriminate miscalibration. Additionally, we develop a novel in-context comparative inference method to alleviate miscalibrations and improve classification performance. Through extensive experiments on five datasets, we demonstrate that our proposed method can achieve more accurate and calibrated predictions compared to regular zero-shot and few-shot prompting.
ProS: Facial Omni-Representation Learning via Prototype-based Self-Distillation
Nov 07, 2023



This paper presents a novel approach, called Prototype-based Self-Distillation (ProS), for unsupervised face representation learning. The existing supervised methods heavily rely on a large amount of annotated training facial data, which poses challenges in terms of data collection and privacy concerns. To address these issues, we propose ProS, which leverages a vast collection of unlabeled face images to learn a comprehensive facial omni-representation. In particular, ProS consists of two vision-transformers (teacher and student models) that are trained with different augmented images (cropping, blurring, coloring, etc.). Besides, we build a face-aware retrieval system along with augmentations to obtain the curated images comprising predominantly facial areas. To enhance the discrimination of learned features, we introduce a prototype-based matching loss that aligns the similarity distributions between features (teacher or student) and a set of learnable prototypes. After pre-training, the teacher vision transformer serves as a backbone for downstream tasks, including attribute estimation, expression recognition, and landmark alignment, achieved through simple fine-tuning with additional layers. Extensive experiments demonstrate that our method achieves state-of-the-art performance on various tasks, both in full and few-shot settings. Furthermore, we investigate pre-training with synthetic face images, and ProS exhibits promising performance in this scenario as well.