 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrate to Discriminate: Improve In-Context Learning with Label-Free Comparative Inference
Oct 03, 2024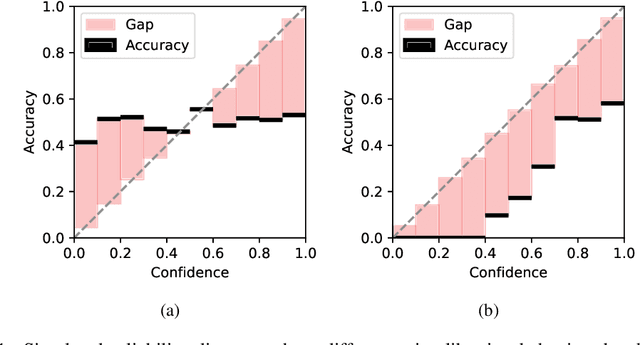
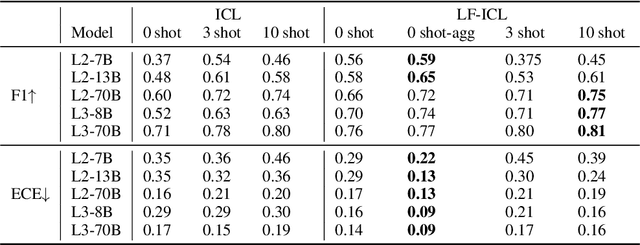
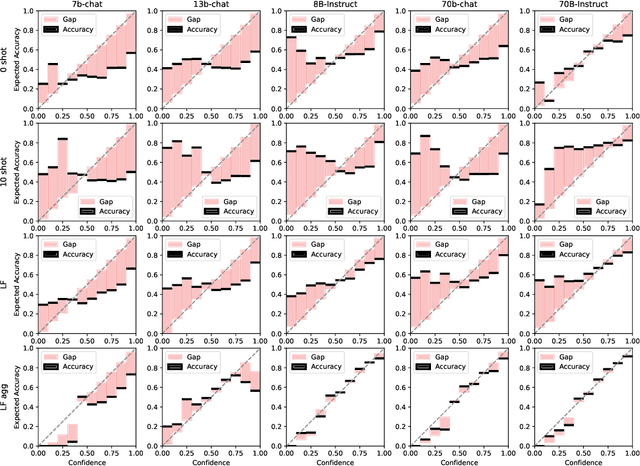
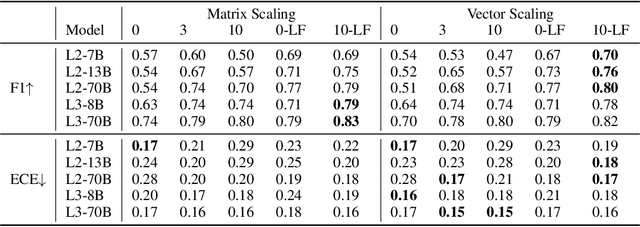
While in-context learning with large language models (LLMs) has shown impressive performance, we have discovered a unique miscalibration behavior where both correct and incorrect predictions are assigned the same level of confidence. We refer to this phenomenon as indiscriminate miscalibration. We found that traditional calibration metrics, such as Expected Calibrated Errors (ECEs), are unable to capture this behavior effectively. To address this issue, we propose new metrics to measure the severity of indiscriminate miscalibration. Additionally, we develop a novel in-context comparative inference method to alleviate miscalibrations and improve classification performance. Through extensive experiments on five datasets, we demonstrate that our proposed method can achieve more accurate and calibrated predictions compared to regular zero-shot and few-shot prompting.