 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrate to Discriminate: Improve In-Context Learning with Label-Free Comparative Inference
Oct 03, 2024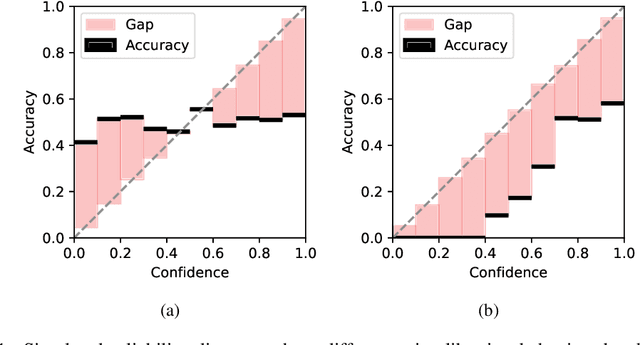
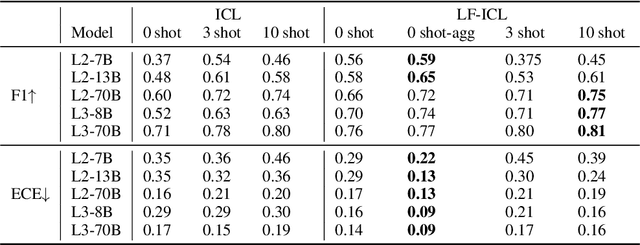
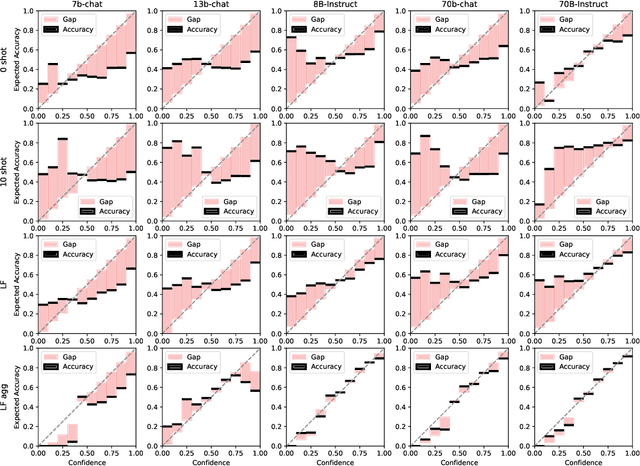
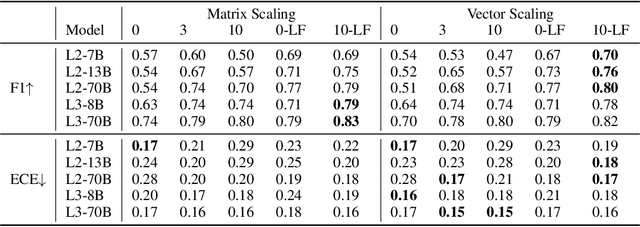
While in-context learning with large language models (LLMs) has shown impressive performance, we have discovered a unique miscalibration behavior where both correct and incorrect predictions are assigned the same level of confidence. We refer to this phenomenon as indiscriminate miscalibration. We found that traditional calibration metrics, such as Expected Calibrated Errors (ECEs), are unable to capture this behavior effectively. To address this issue, we propose new metrics to measure the severity of indiscriminate miscalibration. Additionally, we develop a novel in-context comparative inference method to alleviate miscalibrations and improve classification performance. Through extensive experiments on five datasets, we demonstrate that our proposed method can achieve more accurate and calibrated predictions compared to regular zero-shot and few-shot prompting.
Aligning Large Language Models to a Domain-specific Graph Database
Feb 28, 2024

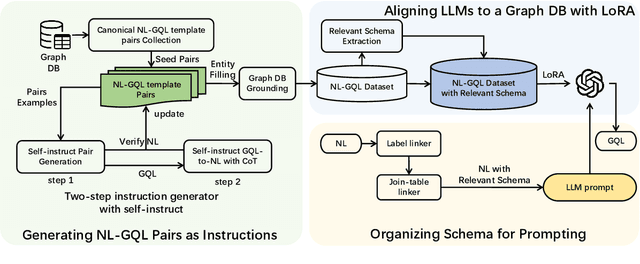

Graph Databases (Graph DB) are widely applied in various fields, including finance, social networks, and medicine. However, translating Natural Language (NL) into the Graph Query Language (GQL), commonly known as NL2GQL, proves to be challenging due to its inherent complexity and specialized nature. Some approaches have sought to utilize Large Language Models (LLMs) to address analogous tasks like text2SQL. Nevertheless, when it comes to NL2GQL taskson a particular domain, the absence of domain-specific NL-GQL data pairs makes it difficult to establish alignment between LLMs and the graph DB. To address this challenge, we propose a well-defined pipeline. Specifically, we utilize ChatGPT to create NL-GQL data pairs based on the given graph DB with self-instruct. Then, we use the created data to fine-tune LLMs, thereby achieving alignment between LLMs and the graph DB. Additionally, during inference, we propose a method that extracts relevant schema to the queried NL as the input context to guide LLMs for generating accurate GQLs.We evaluate our method on two constructed datasets deriving from graph DBs in finance domain and medicine domain, namely FinGQL and MediGQL. Experimental results demonstrate that our method significantly outperforms a set of baseline methods, with improvements of 5.90 and 6.36 absolute points on EM, and 6.00 and 7.09 absolute points on EX, respectively.
An LLM-Enhanced Adversarial Editing System for Lexical Simplification
Feb 23, 2024Lexical Simplification (LS) aims to simplify text at the lexical level. Existing methods rely heavily on annotated data, making it challenging to apply in low-resource scenarios. In this paper, we propose a novel LS method without parallel corpora. This method employs an Adversarial Editing System with guidance from a confusion loss and an invariance loss to predict lexical edits in the original sentences. Meanwhile, we introduce an innovative LLM-enhanced loss to enable the distillation of knowledge from Large Language Models (LLMs) into a small-size LS system. From that, complex words within sentences are masked and a Difficulty-aware Filling module is crafted to replace masked positions with simpler words. At last, extensive experimental results and analyses on three benchmark LS datasets demonstrate the effectiveness of our proposed method.