 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTTS-EAD: Improving Spatio-Temporal Learning Based Time Series Prediction via
Jan 14, 2025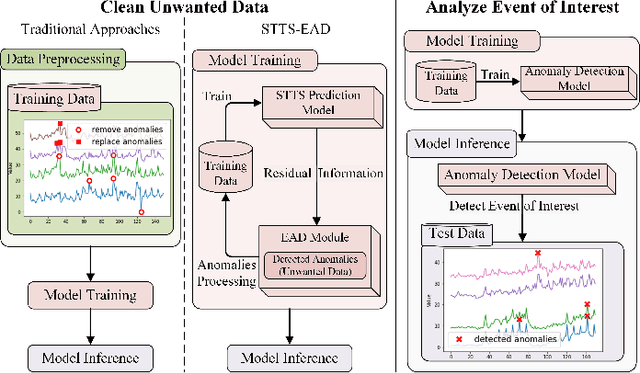
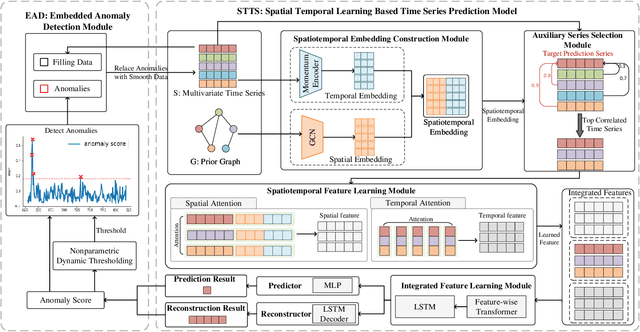
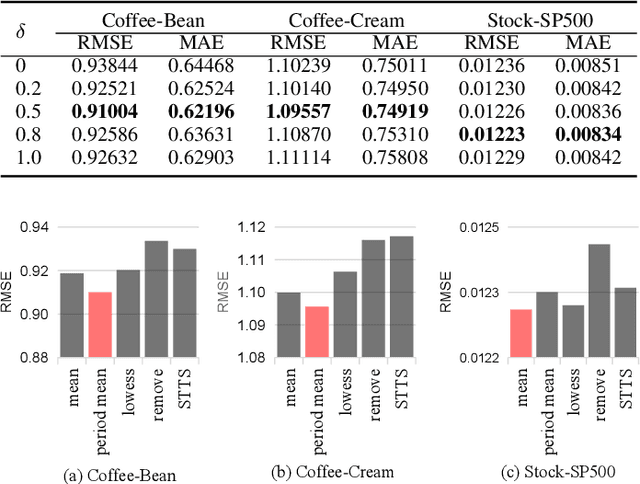
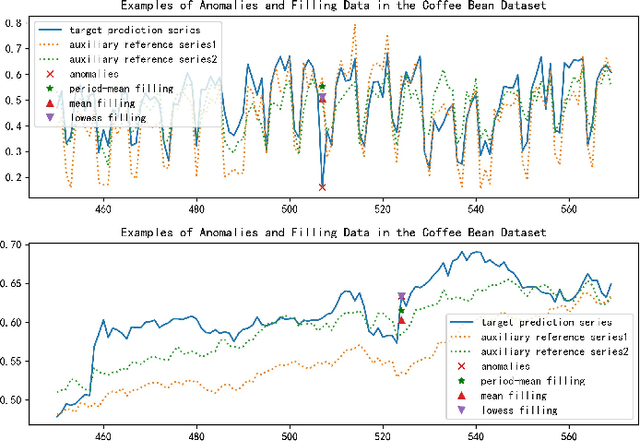
Handling anomalies is a critical preprocessing step in multivariate time series prediction. However, existing approaches that separate anomaly preprocessing from model training for multivariate time series prediction encounter significant limitations. Specifically, these methods fail to utilize auxiliary information crucial for identifying latent anomalies associated with spatiotemporal factors during the preprocessing stage. Instead, they rely solely on data distribution for anomaly detection, which can result in the incorrect processing of numerous samples that could otherwise contribute positively to model training. To address this, we propose STTS-EAD, an end-to-end method that seamlessly integrates anomaly detection into the training process of multivariate time series forecasting and aims to improve Spatio-Temporal learning based Time Series prediction via Embedded Anomaly Detection. Our proposed STTS-EAD leverages spatio-temporal information for forecasting and anomaly detection, with the two parts alternately executed and optimized for each other. To the best of our knowledge, STTS-EAD is the first to integrate anomaly detection and forecasting tasks in the training phase for improving the accuracy of multivariate time series forecasting. Extensive experiments on a public stock dataset and two real-world sales datasets from a renowned coffee chain enterprise show that our proposed method can effectively process detected anomalies in the training stage to improve forecasting performance in the inference stage and significantly outperform baselines.
NAT-NL2GQL: A Novel Multi-Agent Framework for Translating Natural Language to Graph Query Language
Dec 11, 2024



The emergence of Large Language Models (LLMs) has revolutionized many fields, not only traditional natural language processing (NLP) tasks. Recently, research on applying LLMs to the database field has been booming, and as a typical non-relational database, the use of LLMs in graph database research has naturally gained significant attention. Recent efforts have increasingly focused on leveraging LLMs to translate natural language into graph query language (NL2GQL). Although some progress has been made, these methods have clear limitations, such as their reliance on streamlined processes that often overlook the potential of LLMs to autonomously plan and collaborate with other LLMs in tackling complex NL2GQL challenges. To address this gap, we propose NAT-NL2GQL, a novel multi-agent framework for translating natural language to graph query language. Specifically, our framework consists of three synergistic agents: the Preprocessor agent, the Generator agent, and the Refiner agent. The Preprocessor agent manages data processing as context, including tasks such as name entity recognition, query rewriting, path linking, and the extraction of query-related schemas. The Generator agent is a fine-tuned LLM trained on NL-GQL data, responsible for generating corresponding GQL statements based on queries and their related schemas. The Refiner agent is tasked with refining the GQL or context using error information obtained from the GQL execution results. Given the scarcity of high-quality open-source NL2GQL datasets based on nGQL syntax, we developed StockGQL, a dataset constructed from a financial market graph database. It is available at: https://github.com/leonyuancode/StockGQL. Experimental results on the StockGQL and SpCQL datasets reveal that our method significantly outperforms baseline approaches, highlighting its potential for advancing NL2GQL research.
Retrieval Augmented Instruction Tuning for Open NER with Large Language Models
Jun 25, 2024
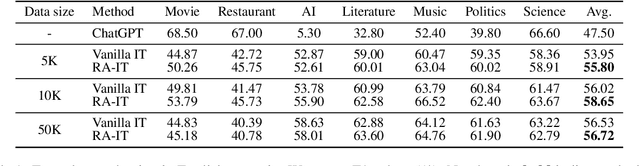
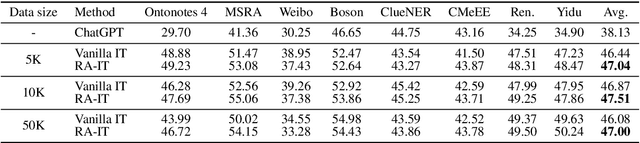
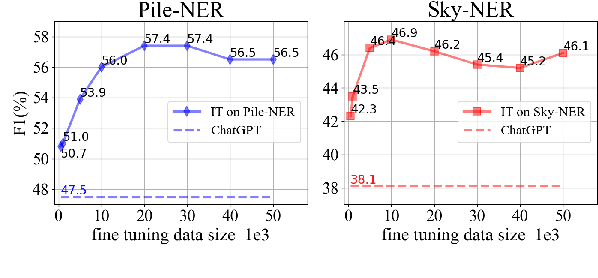
The strong capability of large language models (LLMs) has been applied to information extraction (IE) through either retrieval augmented prompting or instruction tuning (IT). However, the best way to incorporate information with LLMs for IE remains an open question. In this paper, we explore Retrieval Augmented Instruction Tuning (RA-IT) for IE, focusing on the task of open named entity recognition (NER). Specifically, for each training sample, we retrieve semantically similar examples from the training dataset as the context and prepend them to the input of the original instruction. To evaluate our RA-IT approach more thoroughly, we construct a Chinese IT dataset for open NER and evaluate RA-IT in both English and Chinese scenarios. Experimental results verify the effectiveness of RA-IT across various data sizes and in both English and Chinese scenarios. We also conduct thorough studies to explore the impacts of various retrieval strategies in the proposed RA-IT framework. Code and data are available at: https://github.com/Emma1066/Retrieval-Augmented-IT-OpenNER
Aligning Large Language Models to a Domain-specific Graph Database
Feb 28, 2024

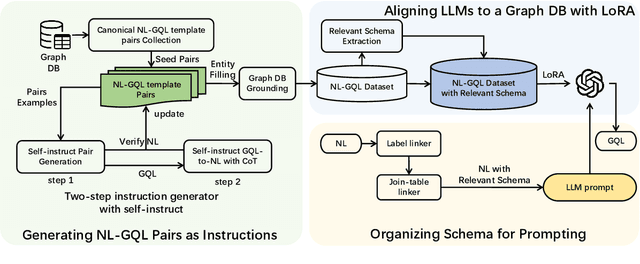

Graph Databases (Graph DB) are widely applied in various fields, including finance, social networks, and medicine. However, translating Natural Language (NL) into the Graph Query Language (GQL), commonly known as NL2GQL, proves to be challenging due to its inherent complexity and specialized nature. Some approaches have sought to utilize Large Language Models (LLMs) to address analogous tasks like text2SQL. Nevertheless, when it comes to NL2GQL taskson a particular domain, the absence of domain-specific NL-GQL data pairs makes it difficult to establish alignment between LLMs and the graph DB. To address this challenge, we propose a well-defined pipeline. Specifically, we utilize ChatGPT to create NL-GQL data pairs based on the given graph DB with self-instruct. Then, we use the created data to fine-tune LLMs, thereby achieving alignment between LLMs and the graph DB. Additionally, during inference, we propose a method that extracts relevant schema to the queried NL as the input context to guide LLMs for generating accurate GQLs.We evaluate our method on two constructed datasets deriving from graph DBs in finance domain and medicine domain, namely FinGQL and MediGQL. Experimental results demonstrate that our method significantly outperforms a set of baseline methods, with improvements of 5.90 and 6.36 absolute points on EM, and 6.00 and 7.09 absolute points on EX, respectively.
Self-Improving for Zero-Shot Named Entity Recognition with Large Language Models
Nov 15, 2023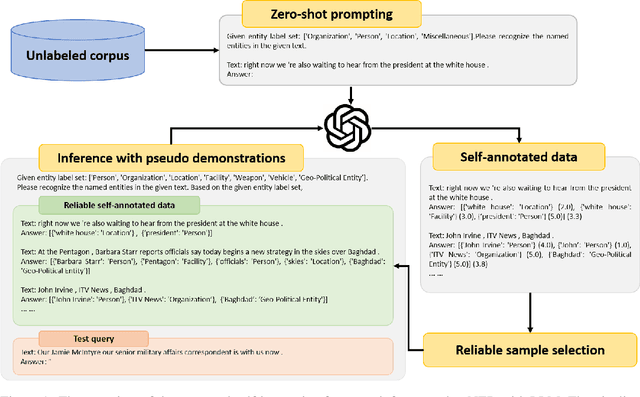
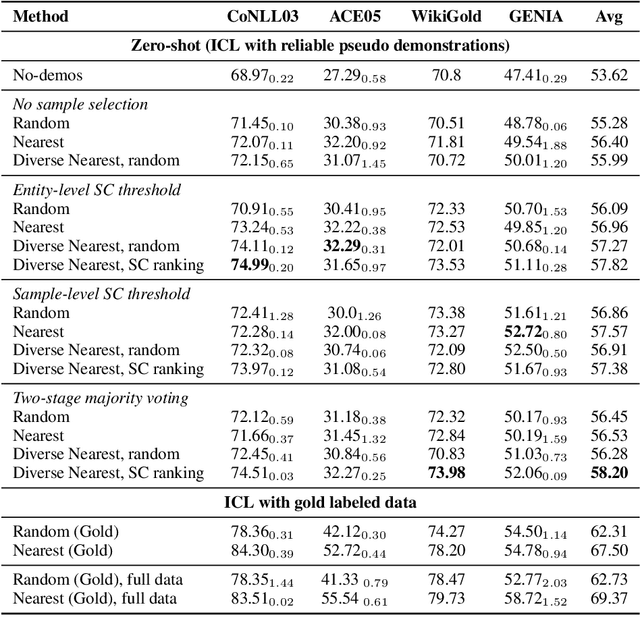
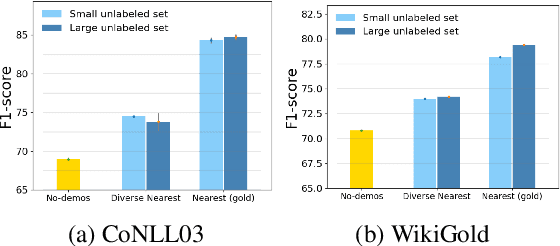
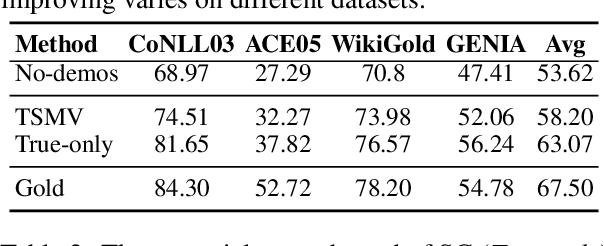
Exploring the application of powerful large language models (LLMs) on the fundamental named entity recognition (NER) task has drawn much attention recently. This work aims to investigate the possibilities of pushing the boundary of zero-shot NER with LLM via a training-free self-improving strategy. We propose a self-improving framework, which utilize an unlabeled corpus to stimulate the self-learning ability of LLMs on NER. First, we use LLM to make predictions on the unlabeled corpus and obtain the self-annotated data. Second, we explore various strategies to select reliable samples from the self-annotated dataset as demonstrations, considering the similarity, diversity and reliability of demonstrations. Finally, we conduct inference for the test query via in-context learning with the selected self-annotated demonstrations. Through comprehensive experimental analysis, our study yielded the following findings: (1) The self-improving framework further pushes the boundary of zero-shot NER with LLMs, and achieves an obvious performance improvement; (2) Iterative self-improving or naively increasing the size of unlabeled corpus does not guarantee improvements; (3) There might still be space for improvement via more advanced strategy for reliable entity selection.
Empirical Study of Zero-Shot NER with ChatGPT
Oct 16, 2023Large language models (LLMs) exhibited powerful capability in various natural language processing tasks. This work focuses on exploring LLM performance on zero-shot information extraction, with a focus on the ChatGPT and named entity recognition (NER) task. Inspired by the remarkable reasoning capability of LLM on symbolic and arithmetic reasoning, we adapt the prevalent reasoning methods to NER and propose reasoning strategies tailored for NER. First, we explore a decomposed question-answering paradigm by breaking down the NER task into simpler subproblems by labels. Second, we propose syntactic augmentation to stimulate the model's intermediate thinking in two ways: syntactic prompting, which encourages the model to analyze the syntactic structure itself, and tool augmentation, which provides the model with the syntactic information generated by a parsing tool. Besides, we adapt self-consistency to NER by proposing a two-stage majority voting strategy, which first votes for the most consistent mentions, then the most consistent types. The proposed methods achieve remarkable improvements for zero-shot NER across seven benchmarks, including Chinese and English datasets, and on both domain-specific and general-domain scenarios. In addition, we present a comprehensive analysis of the error types with suggestions for optimization directions. We also verify the effectiveness of the proposed methods on the few-shot setting and other LLMs.