 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Large Language Models to a Domain-specific Graph Database
Paper and Code
Feb 28, 2024

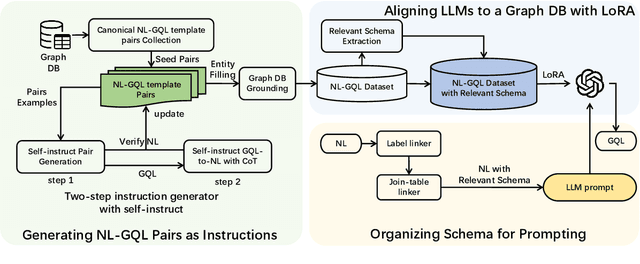

Graph Databases (Graph DB) are widely applied in various fields, including finance, social networks, and medicine. However, translating Natural Language (NL) into the Graph Query Language (GQL), commonly known as NL2GQL, proves to be challenging due to its inherent complexity and specialized nature. Some approaches have sought to utilize Large Language Models (LLMs) to address analogous tasks like text2SQL. Nevertheless, when it comes to NL2GQL taskson a particular domain, the absence of domain-specific NL-GQL data pairs makes it difficult to establish alignment between LLMs and the graph DB. To address this challenge, we propose a well-defined pipeline. Specifically, we utilize ChatGPT to create NL-GQL data pairs based on the given graph DB with self-instruct. Then, we use the created data to fine-tune LLMs, thereby achieving alignment between LLMs and the graph DB. Additionally, during inference, we propose a method that extracts relevant schema to the queried NL as the input context to guide LLMs for generating accurate GQLs.We evaluate our method on two constructed datasets deriving from graph DBs in finance domain and medicine domain, namely FinGQL and MediGQL. Experimental results demonstrate that our method significantly outperforms a set of baseline methods, with improvements of 5.90 and 6.36 absolute points on EM, and 6.00 and 7.09 absolute points on EX, respectively.