 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoCoGEC: Counterfactual Generation for Robust Grammatical Error Correction
Jun 13, 2026Grammatical error correction (GEC) systems are usually trained and evaluated on GEC benchmarks, but their performance often drops sharply once the surrounding context is slightly perturbed or extended. This indicates that the existing GEC models usually fail to understand the error patterns in the varying contexts. In this paper, we thoroughly investigate the counterfactuals for GEC tasks, where the subtle changes to the contexts could lead to the label flipping issue. We propose CoCoGEC, a counterfactual generation framework that creates copies of training instances with error-irrelevant contexts altered. Our framework systematically generates counterfactuals by (1) generating intra- and inter-sentence counterfactuals that maintain the error patterns as well as syntax of the original instances by altering the word-level and sentence-level contexts; (2) revising the generated counterfactuals by selecting the instances with flipped labels and high GEC Mutual Information (MI) coefficient. Extensive experiments show that our method substantially improves the stability of GEC models, outperforming a set of data augmentation baselines. Particularly, it could achieve absolute F0.5 gains of +9.9, +11.3, and +20.8 points on the perturbed BEA-19*,CoNLL-14*, and TEM-8* data set.Our code is released at https://github.com/Quinnok/CoCoGEC
ToxiTrace: Gradient-Aligned Training for Explainable Chinese Toxicity Detection
Apr 14, 2026Existing Chinese toxic content detection methods mainly target sentence-level classification but often fail to provide readable and contiguous toxic evidence spans. We propose \textbf{ToxiTrace}, an explainability-oriented method for BERT-style encoders with three components: (1) \textbf{CuSA}, which refines encoder-derived saliency cues into fine-grained toxic spans with lightweight LLM guidance; (2) \textbf{GCLoss}, a gradient-constrained objective that concentrates token-level saliency on toxic evidence while suppressing irrelevant activations; and (3) \textbf{ARCL}, which constructs sample-specific contrastive reasoning pairs to sharpen the semantic boundary between toxic and non-toxic content. Experiments show that ToxiTrace improves classification accuracy and toxic span extraction while preserving efficient encoder-based inference and producing more coherent, human-readable explanations. We have released the model at https://huggingface.co/ArdLi/ToxiTrace.
STTS-EAD: Improving Spatio-Temporal Learning Based Time Series Prediction via
Jan 14, 2025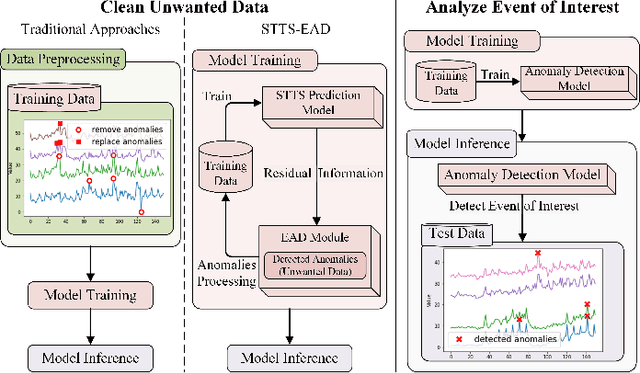
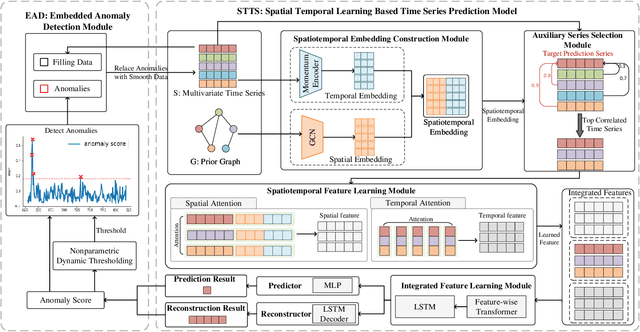
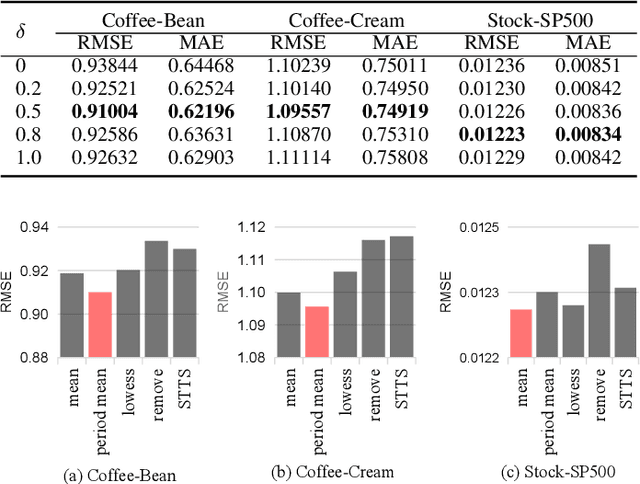
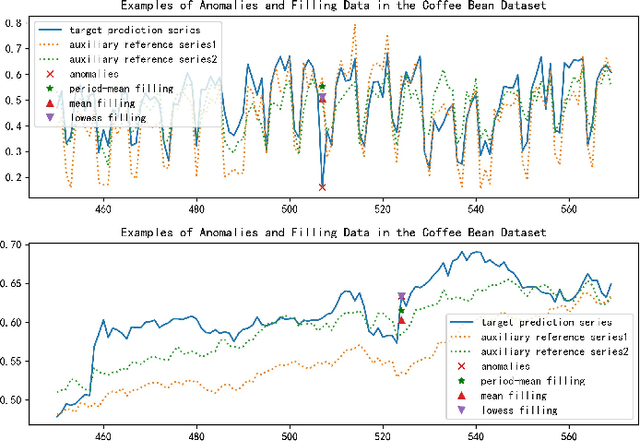
Handling anomalies is a critical preprocessing step in multivariate time series prediction. However, existing approaches that separate anomaly preprocessing from model training for multivariate time series prediction encounter significant limitations. Specifically, these methods fail to utilize auxiliary information crucial for identifying latent anomalies associated with spatiotemporal factors during the preprocessing stage. Instead, they rely solely on data distribution for anomaly detection, which can result in the incorrect processing of numerous samples that could otherwise contribute positively to model training. To address this, we propose STTS-EAD, an end-to-end method that seamlessly integrates anomaly detection into the training process of multivariate time series forecasting and aims to improve Spatio-Temporal learning based Time Series prediction via Embedded Anomaly Detection. Our proposed STTS-EAD leverages spatio-temporal information for forecasting and anomaly detection, with the two parts alternately executed and optimized for each other. To the best of our knowledge, STTS-EAD is the first to integrate anomaly detection and forecasting tasks in the training phase for improving the accuracy of multivariate time series forecasting. Extensive experiments on a public stock dataset and two real-world sales datasets from a renowned coffee chain enterprise show that our proposed method can effectively process detected anomalies in the training stage to improve forecasting performance in the inference stage and significantly outperform baselines.
NAT-NL2GQL: A Novel Multi-Agent Framework for Translating Natural Language to Graph Query Language
Dec 11, 2024



The emergence of Large Language Models (LLMs) has revolutionized many fields, not only traditional natural language processing (NLP) tasks. Recently, research on applying LLMs to the database field has been booming, and as a typical non-relational database, the use of LLMs in graph database research has naturally gained significant attention. Recent efforts have increasingly focused on leveraging LLMs to translate natural language into graph query language (NL2GQL). Although some progress has been made, these methods have clear limitations, such as their reliance on streamlined processes that often overlook the potential of LLMs to autonomously plan and collaborate with other LLMs in tackling complex NL2GQL challenges. To address this gap, we propose NAT-NL2GQL, a novel multi-agent framework for translating natural language to graph query language. Specifically, our framework consists of three synergistic agents: the Preprocessor agent, the Generator agent, and the Refiner agent. The Preprocessor agent manages data processing as context, including tasks such as name entity recognition, query rewriting, path linking, and the extraction of query-related schemas. The Generator agent is a fine-tuned LLM trained on NL-GQL data, responsible for generating corresponding GQL statements based on queries and their related schemas. The Refiner agent is tasked with refining the GQL or context using error information obtained from the GQL execution results. Given the scarcity of high-quality open-source NL2GQL datasets based on nGQL syntax, we developed StockGQL, a dataset constructed from a financial market graph database. It is available at: https://github.com/leonyuancode/StockGQL. Experimental results on the StockGQL and SpCQL datasets reveal that our method significantly outperforms baseline approaches, highlighting its potential for advancing NL2GQL research.
Retrieval Augmented Instruction Tuning for Open NER with Large Language Models
Jun 25, 2024
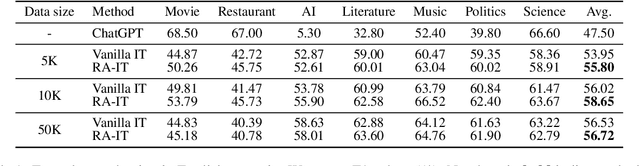
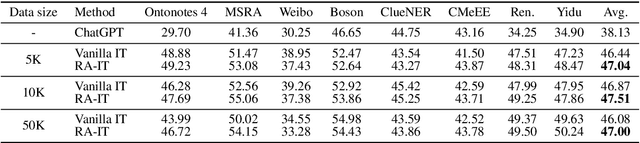
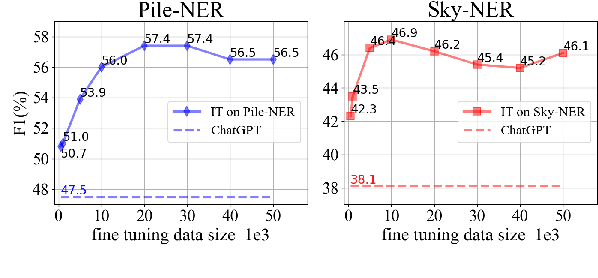
The strong capability of large language models (LLMs) has been applied to information extraction (IE) through either retrieval augmented prompting or instruction tuning (IT). However, the best way to incorporate information with LLMs for IE remains an open question. In this paper, we explore Retrieval Augmented Instruction Tuning (RA-IT) for IE, focusing on the task of open named entity recognition (NER). Specifically, for each training sample, we retrieve semantically similar examples from the training dataset as the context and prepend them to the input of the original instruction. To evaluate our RA-IT approach more thoroughly, we construct a Chinese IT dataset for open NER and evaluate RA-IT in both English and Chinese scenarios. Experimental results verify the effectiveness of RA-IT across various data sizes and in both English and Chinese scenarios. We also conduct thorough studies to explore the impacts of various retrieval strategies in the proposed RA-IT framework. Code and data are available at: https://github.com/Emma1066/Retrieval-Augmented-IT-OpenNER
Aligning Large Language Models to a Domain-specific Graph Database
Feb 28, 2024

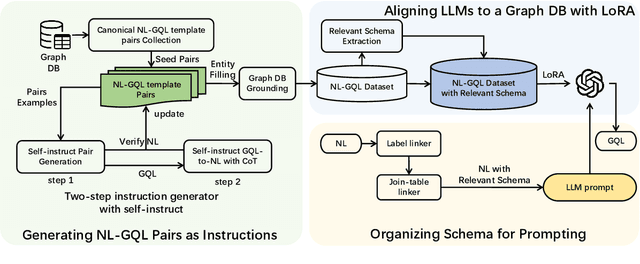

Graph Databases (Graph DB) are widely applied in various fields, including finance, social networks, and medicine. However, translating Natural Language (NL) into the Graph Query Language (GQL), commonly known as NL2GQL, proves to be challenging due to its inherent complexity and specialized nature. Some approaches have sought to utilize Large Language Models (LLMs) to address analogous tasks like text2SQL. Nevertheless, when it comes to NL2GQL taskson a particular domain, the absence of domain-specific NL-GQL data pairs makes it difficult to establish alignment between LLMs and the graph DB. To address this challenge, we propose a well-defined pipeline. Specifically, we utilize ChatGPT to create NL-GQL data pairs based on the given graph DB with self-instruct. Then, we use the created data to fine-tune LLMs, thereby achieving alignment between LLMs and the graph DB. Additionally, during inference, we propose a method that extracts relevant schema to the queried NL as the input context to guide LLMs for generating accurate GQLs.We evaluate our method on two constructed datasets deriving from graph DBs in finance domain and medicine domain, namely FinGQL and MediGQL. Experimental results demonstrate that our method significantly outperforms a set of baseline methods, with improvements of 5.90 and 6.36 absolute points on EM, and 6.00 and 7.09 absolute points on EX, respectively.
Prompting Large Language Models with Chain-of-Thought for Few-Shot Knowledge Base Question Generation
Oct 23, 2023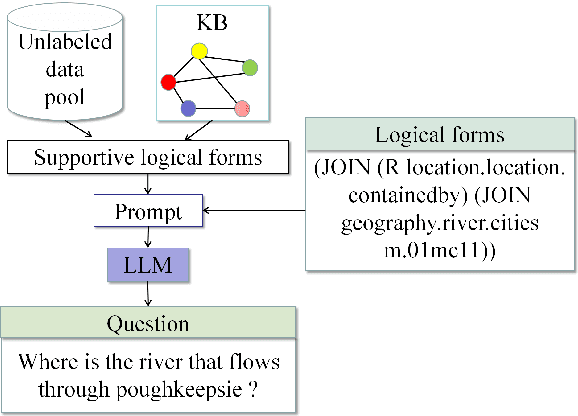
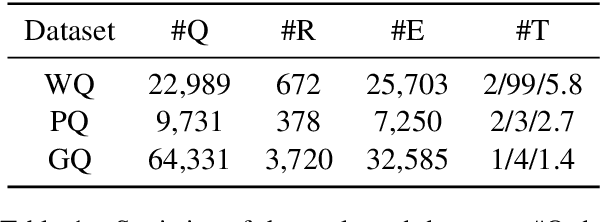
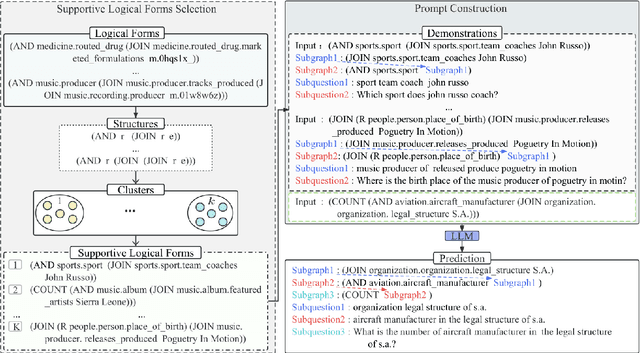
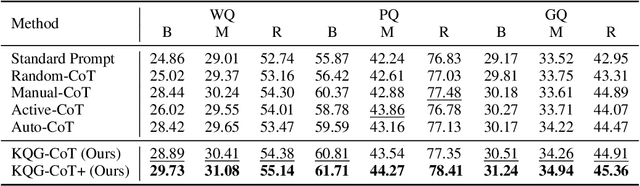
The task of Question Generation over Knowledge Bases (KBQG) aims to convert a logical form into a natural language question. For the sake of expensive cost of large-scale question annotation, the methods of KBQG under low-resource scenarios urgently need to be developed. However, current methods heavily rely on annotated data for fine-tuning, which is not well-suited for few-shot question generation. The emergence of Large Language Models (LLMs) has shown their impressive generalization ability in few-shot tasks. Inspired by Chain-of-Thought (CoT) prompting, which is an in-context learning strategy for reasoning, we formulate KBQG task as a reasoning problem, where the generation of a complete question is splitted into a series of sub-question generation. Our proposed prompting method KQG-CoT first retrieves supportive logical forms from the unlabeled data pool taking account of the characteristics of the logical form. Then, we write a prompt to explicit the reasoning chain of generating complicated questions based on the selected demonstrations. To further ensure prompt quality, we extend KQG-CoT into KQG-CoT+ via sorting the logical forms by their complexity. We conduct extensive experiments over three public KBQG datasets. The results demonstrate that our prompting method consistently outperforms other prompting baselines on the evaluated datasets. Remarkably, our KQG-CoT+ method could surpass existing few-shot SoTA results of the PathQuestions dataset by 18.25, 10.72, and 10.18 absolute points on BLEU-4, METEOR, and ROUGE-L, respectively.
Low-Light Image Restoration Based on Retina Model using Neural Networks
Oct 04, 2022



We report the possibility of using a simple neural network for effortless restoration of low-light images inspired by the retina model, which mimics the neurophysiological principles and dynamics of various types of optical neurons. The proposed neural network model saves the cost of computational overhead in contrast with traditional signal-processing models, and generates results comparable with complicated deep learning models from the subjective perceptual perspective. This work shows that to directly simulate the functionalities of retinal neurons using neural networks not only avoids the manually seeking for the optimal parameters, but also paves the way to build corresponding artificial versions for certain neurobiological organizations.