 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
EvoCUA: Evolving Computer Use Agents via Learning from Scalable Synthetic Experience
Jan 23, 2026The development of native computer-use agents (CUA) represents a significant leap in multimodal AI. However, their potential is currently bottlenecked by the constraints of static data scaling. Existing paradigms relying primarily on passive imitation of static datasets struggle to capture the intricate causal dynamics inherent in long-horizon computer tasks. In this work, we introduce EvoCUA, a native computer use agentic model. Unlike static imitation, EvoCUA integrates data generation and policy optimization into a self-sustaining evolutionary cycle. To mitigate data scarcity, we develop a verifiable synthesis engine that autonomously generates diverse tasks coupled with executable validators. To enable large-scale experience acquisition, we design a scalable infrastructure orchestrating tens of thousands of asynchronous sandbox rollouts. Building on these massive trajectories, we propose an iterative evolving learning strategy to efficiently internalize this experience. This mechanism dynamically regulates policy updates by identifying capability boundaries -- reinforcing successful routines while transforming failure trajectories into rich supervision through error analysis and self-correction. Empirical evaluations on the OSWorld benchmark demonstrate that EvoCUA achieves a success rate of 56.7%, establishing a new open-source state-of-the-art. Notably, EvoCUA significantly outperforms the previous best open-source model, OpenCUA-72B (45.0%), and surpasses leading closed-weights models such as UI-TARS-2 (53.1%). Crucially, our results underscore the generalizability of this approach: the evolving paradigm driven by learning from experience yields consistent performance gains across foundation models of varying scales, establishing a robust and scalable path for advancing native agent capabilities.
Revisiting 2D Foundation Models for Scalable 3D Medical Image Classification
Dec 15, 2025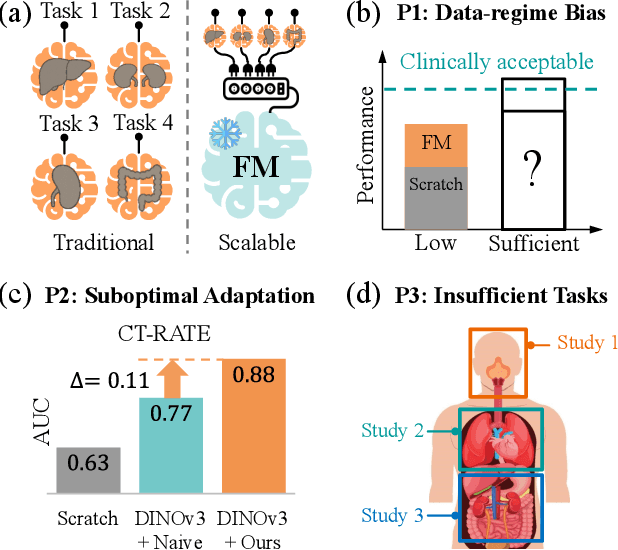
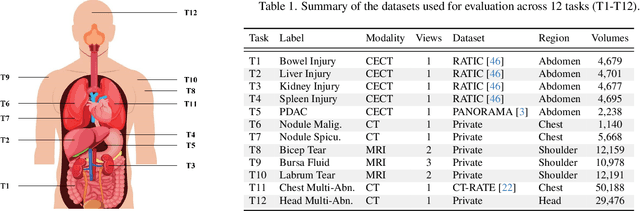
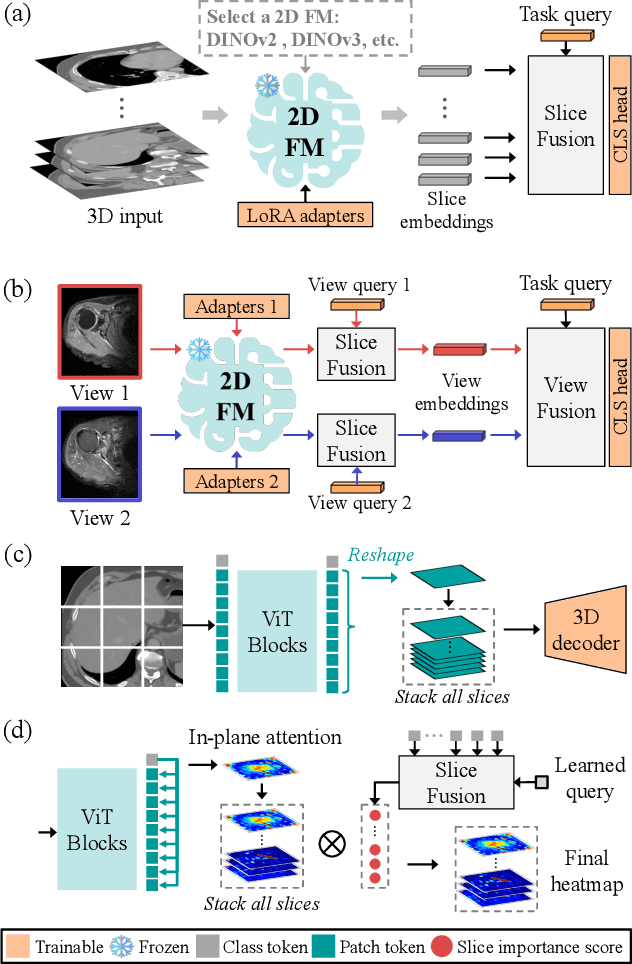
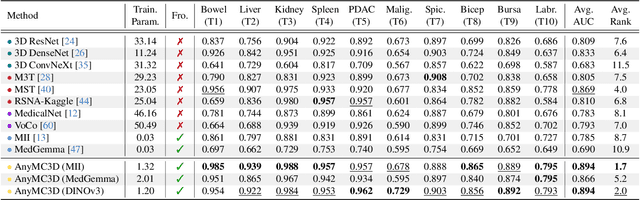
3D medical image classification is essential for modern clinical workflows. Medical foundation models (FMs) have emerged as a promising approach for scaling to new tasks, yet current research suffers from three critical pitfalls: data-regime bias, suboptimal adaptation, and insufficient task coverage. In this paper, we address these pitfalls and introduce AnyMC3D, a scalable 3D classifier adapted from 2D FMs. Our method scales efficiently to new tasks by adding only lightweight plugins (about 1M parameters per task) on top of a single frozen backbone. This versatile framework also supports multi-view inputs, auxiliary pixel-level supervision, and interpretable heatmap generation. We establish a comprehensive benchmark of 12 tasks covering diverse pathologies, anatomies, and modalities, and systematically analyze state-of-the-art 3D classification techniques. Our analysis reveals key insights: (1) effective adaptation is essential to unlock FM potential, (2) general-purpose FMs can match medical-specific FMs if properly adapted, and (3) 2D-based methods surpass 3D architectures for 3D classification. For the first time, we demonstrate the feasibility of achieving state-of-the-art performance across diverse applications using a single scalable framework (including 1st place in the VLM3D challenge), eliminating the need for separate task-specific models.
Autoformalizer with Tool Feedback
Oct 08, 2025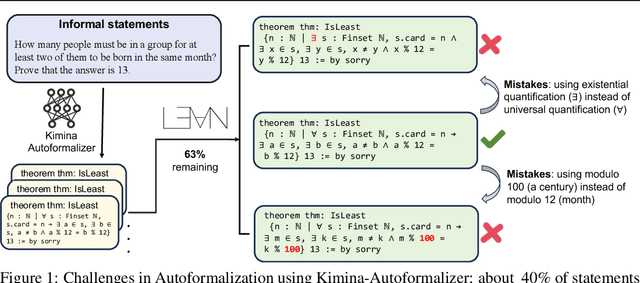

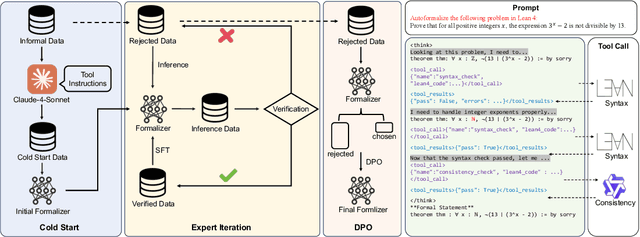
Autoformalization addresses the scarcity of data for Automated Theorem Proving (ATP) by translating mathematical problems from natural language into formal statements. Efforts in recent work shift from directly prompting large language models to training an end-to-end formalizer model from scratch, achieving remarkable advancements. However, existing formalizer still struggles to consistently generate valid statements that meet syntactic validity and semantic consistency. To address this issue, we propose the Autoformalizer with Tool Feedback (ATF), a novel approach that incorporates syntactic and consistency information as tools into the formalization process. By integrating Lean 4 compilers for syntax corrections and employing a multi-LLMs-as-judge approach for consistency validation, the model is able to adaptively refine generated statements according to the tool feedback, enhancing both syntactic validity and semantic consistency. The training of ATF involves a cold-start phase on synthetic tool-calling data, an expert iteration phase to improve formalization capabilities, and Direct Preference Optimization to alleviate ineffective revisions. Experimental results show that ATF markedly outperforms a range of baseline formalizer models, with its superior performance further validated by human evaluations. Subsequent analysis reveals that ATF demonstrates excellent inference scaling properties. Moreover, we open-source Numina-ATF, a dataset containing 750K synthetic formal statements to facilitate advancements in autoformalization and ATP research.
MARS2 2025 Challenge on Multimodal Reasoning: Datasets, Methods, Results, Discussion, and Outlook
Sep 17, 2025



This paper reviews the MARS2 2025 Challenge on Multimodal Reasoning. We aim to bring together different approaches in multimodal machine learning and LLMs via a large benchmark. We hope it better allows researchers to follow the state-of-the-art in this very dynamic area. Meanwhile, a growing number of testbeds have boosted the evolution of general-purpose large language models. Thus, this year's MARS2 focuses on real-world and specialized scenarios to broaden the multimodal reasoning applications of MLLMs. Our organizing team released two tailored datasets Lens and AdsQA as test sets, which support general reasoning in 12 daily scenarios and domain-specific reasoning in advertisement videos, respectively. We evaluated 40+ baselines that include both generalist MLLMs and task-specific models, and opened up three competition tracks, i.e., Visual Grounding in Real-world Scenarios (VG-RS), Visual Question Answering with Spatial Awareness (VQA-SA), and Visual Reasoning in Creative Advertisement Videos (VR-Ads). Finally, 76 teams from the renowned academic and industrial institutions have registered and 40+ valid submissions (out of 1200+) have been included in our ranking lists. Our datasets, code sets (40+ baselines and 15+ participants' methods), and rankings are publicly available on the MARS2 workshop website and our GitHub organization page https://github.com/mars2workshop/, where our updates and announcements of upcoming events will be continuously provided.
ScienceBoard: Evaluating Multimodal Autonomous Agents in Realistic Scientific Workflows
May 26, 2025



Large Language Models (LLMs) have extended their impact beyond Natural Language Processing, substantially fostering the development of interdisciplinary research. Recently, various LLM-based agents have been developed to assist scientific discovery progress across multiple aspects and domains. Among these, computer-using agents, capable of interacting with operating systems as humans do, are paving the way to automated scientific problem-solving and addressing routines in researchers' workflows. Recognizing the transformative potential of these agents, we introduce ScienceBoard, which encompasses two complementary contributions: (i) a realistic, multi-domain environment featuring dynamic and visually rich scientific workflows with integrated professional software, where agents can autonomously interact via different interfaces to accelerate complex research tasks and experiments; and (ii) a challenging benchmark of 169 high-quality, rigorously validated real-world tasks curated by humans, spanning scientific-discovery workflows in domains such as biochemistry, astronomy, and geoinformatics. Extensive evaluations of agents with state-of-the-art backbones (e.g., GPT-4o, Claude 3.7, UI-TARS) show that, despite some promising results, they still fall short of reliably assisting scientists in complex workflows, achieving only a 15% overall success rate. In-depth analysis further provides valuable insights for addressing current agent limitations and more effective design principles, paving the way to build more capable agents for scientific discovery. Our code, environment, and benchmark are at https://qiushisun.github.io/ScienceBoard-Home/.
Do Large Language Models Excel in Complex Logical Reasoning with Formal Language?
May 22, 2025Large Language Models (LLMs) have been shown to achieve breakthrough performance on complex logical reasoning tasks. Nevertheless, most existing research focuses on employing formal language to guide LLMs to derive reliable reasoning paths, while systematic evaluations of these capabilities are still limited. In this paper, we aim to conduct a comprehensive evaluation of LLMs across various logical reasoning problems utilizing formal languages. From the perspective of three dimensions, i.e., spectrum of LLMs, taxonomy of tasks, and format of trajectories, our key findings are: 1) Thinking models significantly outperform Instruct models, especially when formal language is employed; 2) All LLMs exhibit limitations in inductive reasoning capability, irrespective of whether they use a formal language; 3) Data with PoT format achieves the best generalization performance across other languages. Additionally, we also curate the formal-relative training data to further enhance the small language models, and the experimental results indicate that a simple rejected fine-tuning method can better enable LLMs to generalize across formal languages and achieve the best overall performance. Our codes and reports are available at https://github.com/jiangjin1999/FormalEval.
CL-BioGAN: Biologically-Inspired Cross-Domain Continual Learning for Hyperspectral Anomaly Detection
May 17, 2025Memory stability and learning flexibility in continual learning (CL) is a core challenge for cross-scene Hyperspectral Anomaly Detection (HAD) task. Biological neural networks can actively forget history knowledge that conflicts with the learning of new experiences by regulating learning-triggered synaptic expansion and synaptic convergence. Inspired by this phenomenon, we propose a novel Biologically-Inspired Continual Learning Generative Adversarial Network (CL-BioGAN) for augmenting continuous distribution fitting ability for cross-domain HAD task, where Continual Learning Bio-inspired Loss (CL-Bio Loss) and self-attention Generative Adversarial Network (BioGAN) are incorporated to realize forgetting history knowledge as well as involving replay strategy in the proposed BioGAN. Specifically, a novel Bio-Inspired Loss composed with an Active Forgetting Loss (AF Loss) and a CL loss is designed to realize parameters releasing and enhancing between new task and history tasks from a Bayesian perspective. Meanwhile, BioGAN loss with L2-Norm enhances self-attention (SA) to further balance the stability and flexibility for better fitting background distribution for open scenario HAD (OHAD) tasks. Experiment results underscore that the proposed CL-BioGAN can achieve more robust and satisfying accuracy for cross-domain HAD with fewer parameters and computation cost. This dual contribution not only elevates CL performance but also offers new insights into neural adaptation mechanisms in OHAD task.
CL-CaGAN: Capsule differential adversarial continuous learning for cross-domain hyperspectral anomaly detection
May 17, 2025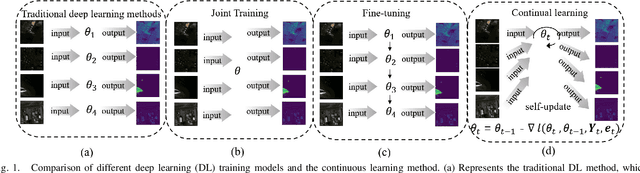
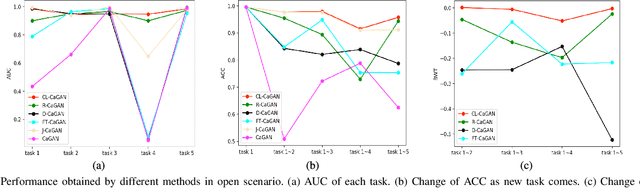
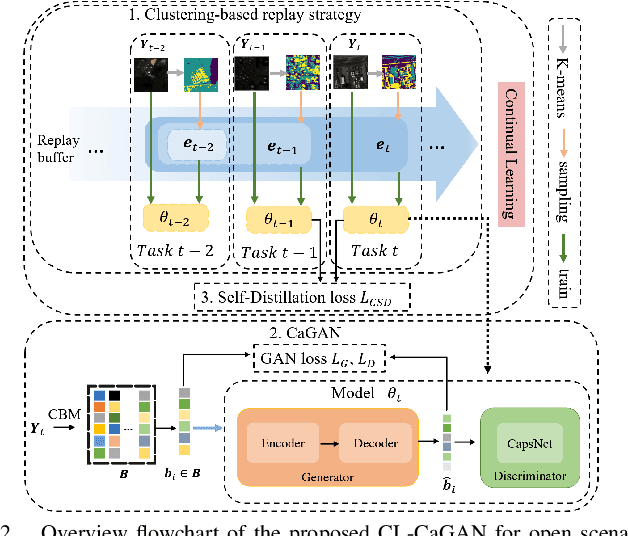
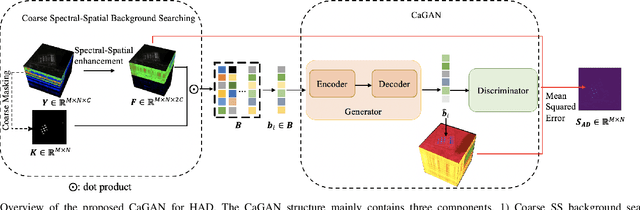
Anomaly detection (AD) has attracted remarkable attention in hyperspectral image (HSI) processing fields, and most existing deep learning (DL)-based algorithms indicate dramatic potential for detecting anomaly samples through specific training process under current scenario. However, the limited prior information and the catastrophic forgetting problem indicate crucial challenges for existing DL structure in open scenarios cross-domain detection. In order to improve the detection performance, a novel continual learning-based capsule differential generative adversarial network (CL-CaGAN) is proposed to elevate the cross-scenario learning performance for facilitating the real application of DL-based structure in hyperspectral AD (HAD) task. First, a modified capsule structure with adversarial learning network is constructed to estimate the background distribution for surmounting the deficiency of prior information. To mitigate the catastrophic forgetting phenomenon, clustering-based sample replay strategy and a designed extra self-distillation regularization are integrated for merging the history and future knowledge in continual AD task, while the discriminative learning ability from previous detection scenario to current scenario is retained by the elaborately designed structure with continual learning (CL) strategy. In addition, the differentiable enhancement is enforced to augment the generation performance of the training data. This further stabilizes the training process with better convergence and efficiently consolidates the reconstruction ability of background samples. To verify the effectiveness of our proposed CL-CaGAN, we conduct experiments on several real HSIs, and the results indicate that the proposed CL-CaGAN demonstrates higher detection performance and continuous learning capacity for mitigating the catastrophic forgetting under cross-domain scenarios.
Prejudge-Before-Think: Enhancing Large Language Models at Test-Time by Process Prejudge Reasoning
Apr 18, 2025
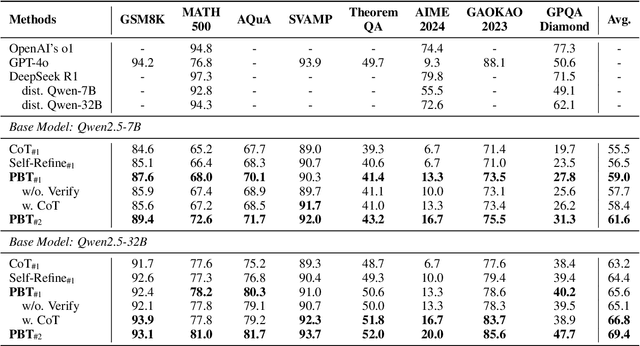

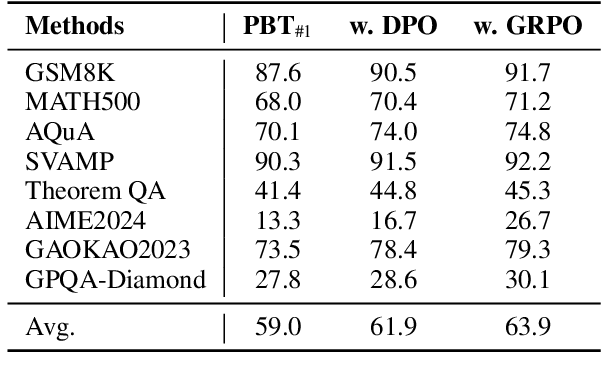
In this paper, we introduce a new \emph{process prejudge} strategy in LLM reasoning to demonstrate that bootstrapping with process prejudge allows the LLM to adaptively anticipate the errors encountered when advancing the subsequent reasoning steps, similar to people sometimes pausing to think about what mistakes may occur and how to avoid them, rather than relying solely on trial and error. Specifically, we define a prejudge node in the rationale, which represents a reasoning step, with at least one step that follows the prejudge node that has no paths toward the correct answer. To synthesize the prejudge reasoning process, we present an automated reasoning framework with a dynamic tree-searching strategy. This framework requires only one LLM to perform answer judging, response critiquing, prejudge generation, and thought completion. Furthermore, we develop a two-phase training mechanism with supervised fine-tuning (SFT) and reinforcement learning (RL) to further enhance the reasoning capabilities of LLMs. Experimental results from competition-level complex reasoning demonstrate that our method can teach the model to prejudge before thinking and significantly enhance the reasoning ability of LLMs. Code and data is released at https://github.com/wjn1996/Prejudge-Before-Think.