 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoCUA: Evolving Computer Use Agents via Learning from Scalable Synthetic Experience
Jan 23, 2026The development of native computer-use agents (CUA) represents a significant leap in multimodal AI. However, their potential is currently bottlenecked by the constraints of static data scaling. Existing paradigms relying primarily on passive imitation of static datasets struggle to capture the intricate causal dynamics inherent in long-horizon computer tasks. In this work, we introduce EvoCUA, a native computer use agentic model. Unlike static imitation, EvoCUA integrates data generation and policy optimization into a self-sustaining evolutionary cycle. To mitigate data scarcity, we develop a verifiable synthesis engine that autonomously generates diverse tasks coupled with executable validators. To enable large-scale experience acquisition, we design a scalable infrastructure orchestrating tens of thousands of asynchronous sandbox rollouts. Building on these massive trajectories, we propose an iterative evolving learning strategy to efficiently internalize this experience. This mechanism dynamically regulates policy updates by identifying capability boundaries -- reinforcing successful routines while transforming failure trajectories into rich supervision through error analysis and self-correction. Empirical evaluations on the OSWorld benchmark demonstrate that EvoCUA achieves a success rate of 56.7%, establishing a new open-source state-of-the-art. Notably, EvoCUA significantly outperforms the previous best open-source model, OpenCUA-72B (45.0%), and surpasses leading closed-weights models such as UI-TARS-2 (53.1%). Crucially, our results underscore the generalizability of this approach: the evolving paradigm driven by learning from experience yields consistent performance gains across foundation models of varying scales, establishing a robust and scalable path for advancing native agent capabilities.
Augmenting the Veracity and Explanations of Complex Fact Checking via Iterative Self-Revision with LLMs
Oct 19, 2024
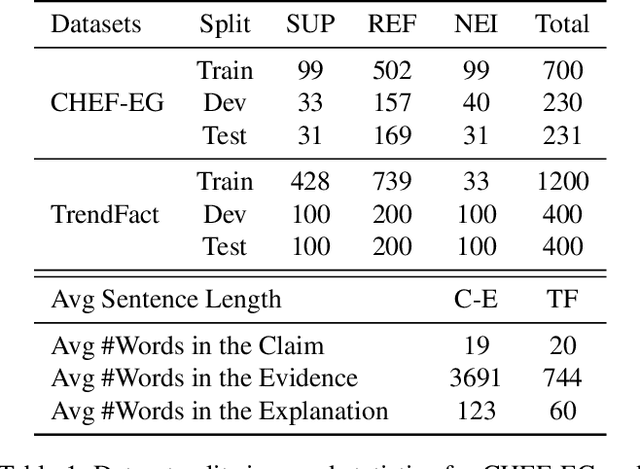
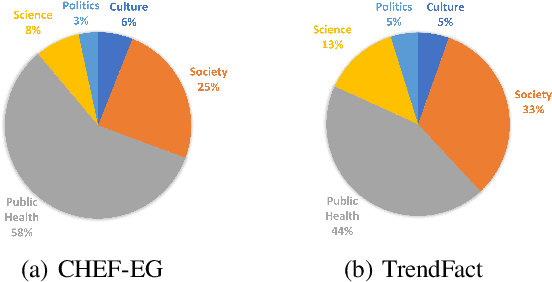
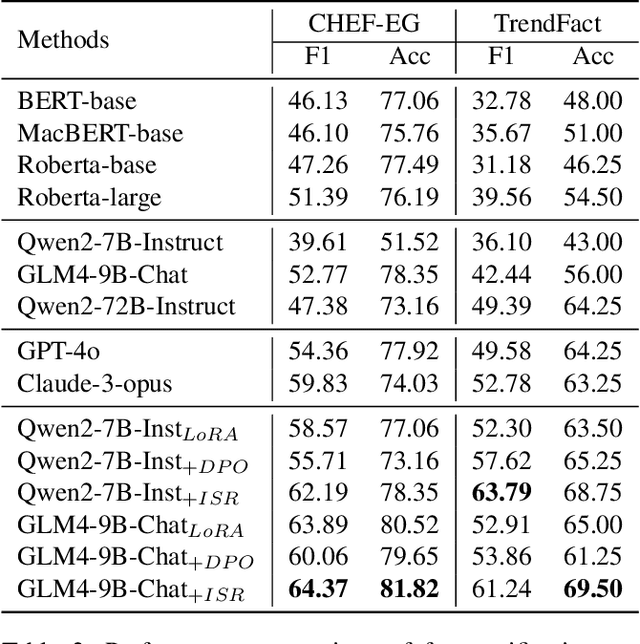
Explanation generation plays a more pivotal role than fact verification in producing interpretable results and facilitating comprehensive fact-checking, which has recently garnered considerable attention. However, previous studies on explanation generation has shown several limitations, such as being confined to English scenarios, involving overly complex inference processes, and not fully unleashing the potential of the mutual feedback between veracity labels and explanation texts. To address these issues, we construct two complex fact-checking datasets in the Chinese scenarios: CHEF-EG and TrendFact. These datasets involve complex facts in areas such as health, politics, and society, presenting significant challenges for fact verification methods. In response to these challenges, we propose a unified framework called FactISR (Augmenting Fact-Checking via Iterative Self-Revision) to perform mutual feedback between veracity and explanations by leveraging the capabilities of large language models(LLMs). FactISR uses a single model to address tasks such as fact verification and explanation generation. Its self-revision mechanism can further revision the consistency between veracity labels, explanation texts, and evidence, as well as eliminate irrelevant noise. We conducted extensive experiments with baselines and FactISR on the proposed datasets. The experimental results demonstrate the effectiveness of our method.
Self-Evolutionary Large Language Models through Uncertainty-Enhanced Preference Optimization
Sep 17, 2024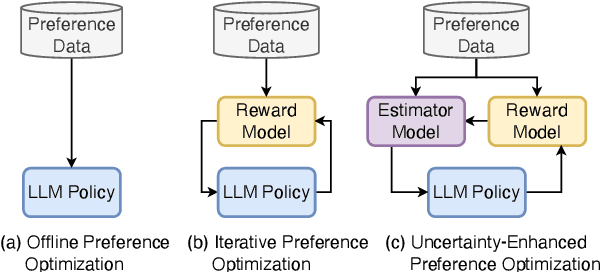
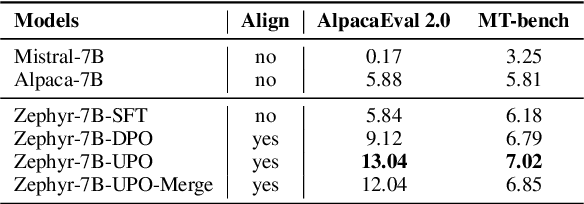
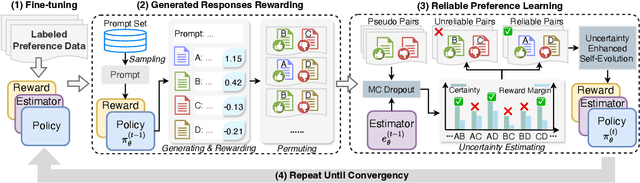
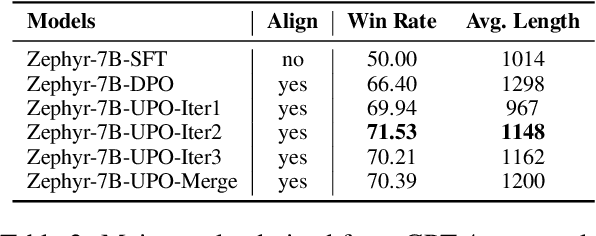
Iterative preference optimization has recently become one of the de-facto training paradigms for large language models (LLMs), but the performance is still underwhelming due to too much noisy preference data yielded in the loop. To combat this issue, we present an \textbf{U}ncertainty-enhanced \textbf{P}reference \textbf{O}ptimization (UPO) framework to make the LLM self-evolve with reliable feedback. The key idea is mitigating the noisy preference data derived from the current policy and reward models by performing pair-wise uncertainty estimation and judiciously reliable feedback sampling. To reach this goal, we thus introduce an estimator model, which incorporates Monte Carlo (MC) dropout in Bayesian neural network (BNN) to perform uncertainty estimation for the preference data derived from the LLM policy. Compared to the existing methods that directly filter generated responses based on the reward score, the estimator focuses on the model uncertainty in a pair-wise manner and effectively bypasses the confirmation bias problem of the reward model. Additionally, we also propose an uncertainty-enhanced self-evolution algorithm to improve the robustness of preference optimization and encourage the LLM to generate responses with both high reward and certainty. Extensive experiments over multiple benchmarks demonstrate that our framework substantially alleviates the noisy problem and improves the performance of iterative preference optimization.
EHR Interaction Between Patients and AI: NoteAid EHR Interaction
Dec 29, 2023With the rapid advancement of Large Language Models (LLMs) and their outstanding performance in semantic and contextual comprehension, the potential of LLMs in specialized domains warrants exploration. This paper introduces the NoteAid EHR Interaction Pipeline, an innovative approach developed using generative LLMs to assist in patient education, a task stemming from the need to aid patients in understanding Electronic Health Records (EHRs). Building upon the NoteAid work, we designed two novel tasks from the patient's perspective: providing explanations for EHR content that patients may not understand and answering questions posed by patients after reading their EHRs. We extracted datasets containing 10,000 instances from MIMIC Discharge Summaries and 876 instances from the MADE medical notes collection, respectively, executing the two tasks through the NoteAid EHR Interaction Pipeline with these data. Performance data of LLMs on these tasks were collected and constructed as the corresponding NoteAid EHR Interaction Dataset. Through a comprehensive evaluation of the entire dataset using LLM assessment and a rigorous manual evaluation of 64 instances, we showcase the potential of LLMs in patient education. Besides, the results provide valuable data support for future exploration and applications in this domain while also supplying high-quality synthetic datasets for in-house system training.