 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Intent Spoken Language Understanding: Methods, Trends, and Challenges
Dec 12, 2025Multi-intent spoken language understanding (SLU) involves two tasks: multiple intent detection and slot filling, which jointly handle utterances containing more than one intent. Owing to this characteristic, which closely reflects real-world applications, the task has attracted increasing research attention, and substantial progress has been achieved. However, there remains a lack of a comprehensive and systematic review of existing studies on multi-intent SLU. To this end, this paper presents a survey of recent advances in multi-intent SLU. We provide an in-depth overview of previous research from two perspectives: decoding paradigms and modeling approaches. On this basis, we further compare the performance of representative models and analyze their strengths and limitations. Finally, we discuss the current challenges and outline promising directions for future research. We hope this survey will offer valuable insights and serve as a useful reference for advancing research in multi-intent SLU.
MR-UIE: Multi-Perspective Reasoning with Reinforcement Learning for Universal Information Extraction
Sep 11, 2025Large language models (LLMs) demonstrate robust capabilities across diverse research domains. However, their performance in universal information extraction (UIE) remains insufficient, especially when tackling structured output scenarios that involve complex schema descriptions and require multi-step reasoning. While existing approaches enhance the performance of LLMs through in-context learning and instruction tuning, significant limitations nonetheless persist. To enhance the model's generalization ability, we propose integrating reinforcement learning (RL) with multi-perspective reasoning for information extraction (IE) tasks. Our work transitions LLMs from passive extractors to active reasoners, enabling them to understand not only what to extract but also how to reason. Experiments conducted on multiple IE benchmarks demonstrate that MR-UIE consistently elevates extraction accuracy across domains and surpasses state-of-the-art methods on several datasets. Furthermore, incorporating multi-perspective reasoning into RL notably enhances generalization in complex IE tasks, underscoring the critical role of reasoning in challenging scenarios.
Augmenting the Veracity and Explanations of Complex Fact Checking via Iterative Self-Revision with LLMs
Oct 19, 2024
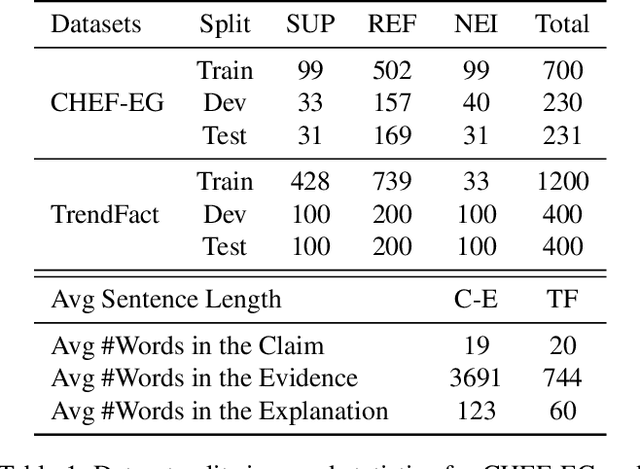
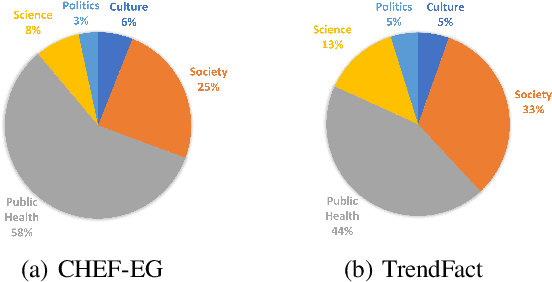
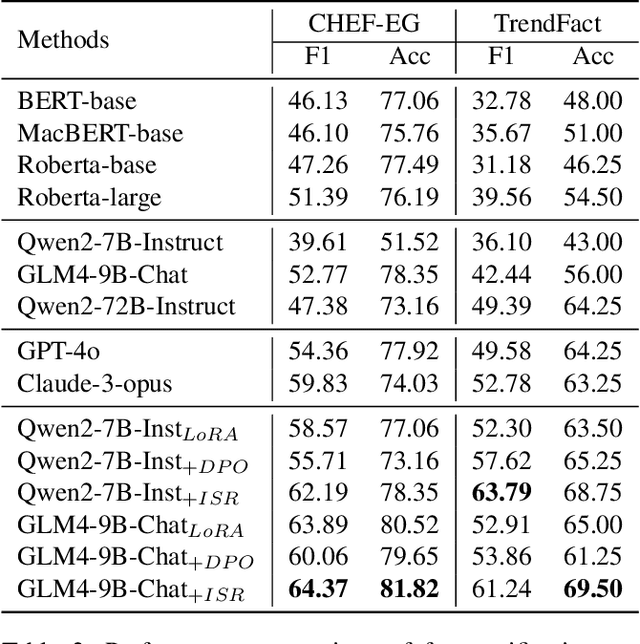
Explanation generation plays a more pivotal role than fact verification in producing interpretable results and facilitating comprehensive fact-checking, which has recently garnered considerable attention. However, previous studies on explanation generation has shown several limitations, such as being confined to English scenarios, involving overly complex inference processes, and not fully unleashing the potential of the mutual feedback between veracity labels and explanation texts. To address these issues, we construct two complex fact-checking datasets in the Chinese scenarios: CHEF-EG and TrendFact. These datasets involve complex facts in areas such as health, politics, and society, presenting significant challenges for fact verification methods. In response to these challenges, we propose a unified framework called FactISR (Augmenting Fact-Checking via Iterative Self-Revision) to perform mutual feedback between veracity and explanations by leveraging the capabilities of large language models(LLMs). FactISR uses a single model to address tasks such as fact verification and explanation generation. Its self-revision mechanism can further revision the consistency between veracity labels, explanation texts, and evidence, as well as eliminate irrelevant noise. We conducted extensive experiments with baselines and FactISR on the proposed datasets. The experimental results demonstrate the effectiveness of our method.
Self-Evolutionary Large Language Models through Uncertainty-Enhanced Preference Optimization
Sep 17, 2024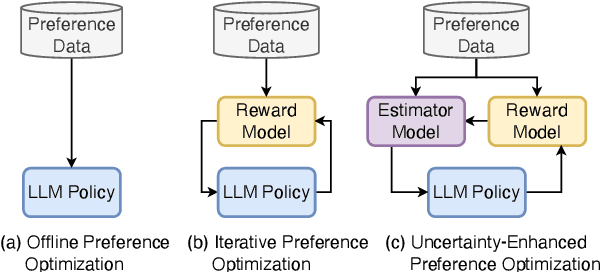
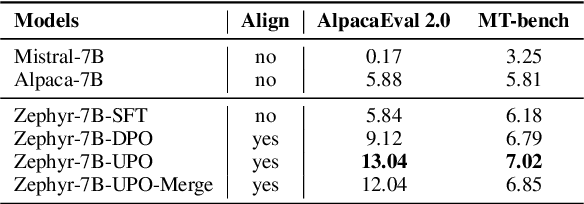
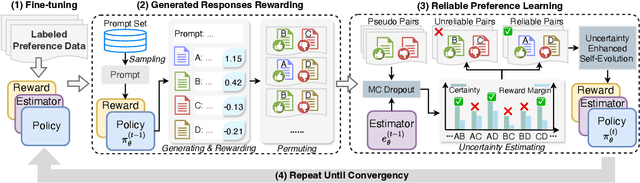
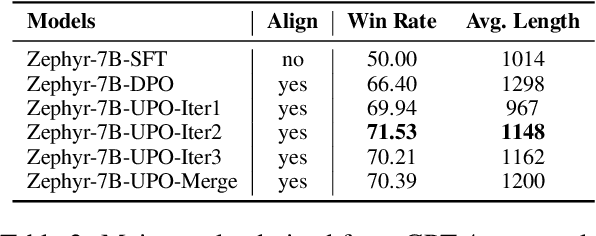
Iterative preference optimization has recently become one of the de-facto training paradigms for large language models (LLMs), but the performance is still underwhelming due to too much noisy preference data yielded in the loop. To combat this issue, we present an \textbf{U}ncertainty-enhanced \textbf{P}reference \textbf{O}ptimization (UPO) framework to make the LLM self-evolve with reliable feedback. The key idea is mitigating the noisy preference data derived from the current policy and reward models by performing pair-wise uncertainty estimation and judiciously reliable feedback sampling. To reach this goal, we thus introduce an estimator model, which incorporates Monte Carlo (MC) dropout in Bayesian neural network (BNN) to perform uncertainty estimation for the preference data derived from the LLM policy. Compared to the existing methods that directly filter generated responses based on the reward score, the estimator focuses on the model uncertainty in a pair-wise manner and effectively bypasses the confirmation bias problem of the reward model. Additionally, we also propose an uncertainty-enhanced self-evolution algorithm to improve the robustness of preference optimization and encourage the LLM to generate responses with both high reward and certainty. Extensive experiments over multiple benchmarks demonstrate that our framework substantially alleviates the noisy problem and improves the performance of iterative preference optimization.
Toward An Optimal Selection of Dialogue Strategies: A Target-Driven Approach for Intelligent Outbound Robots
Jun 22, 2022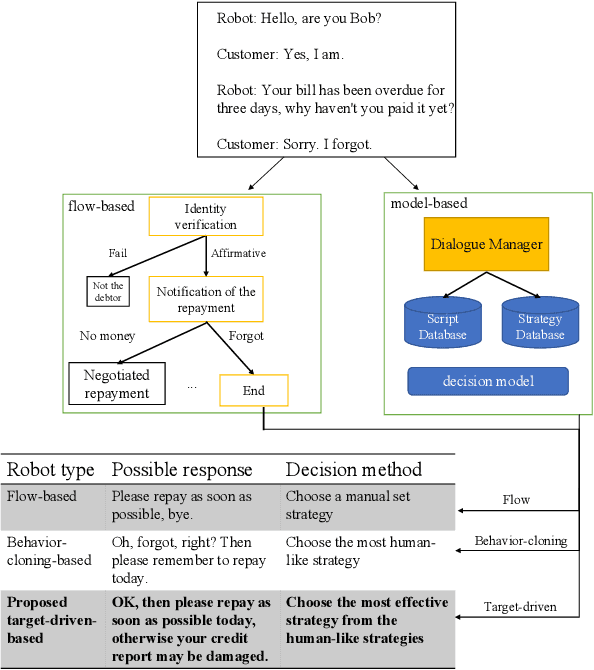
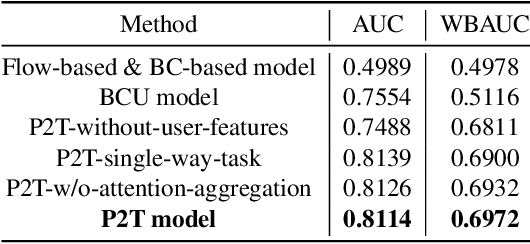
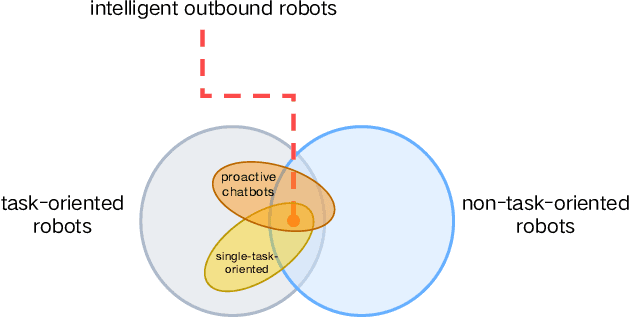
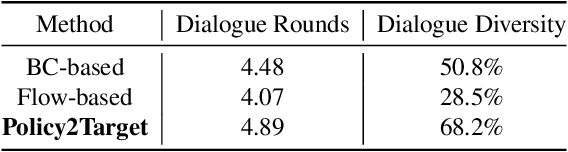
With the growth of the economy and society, enterprises, especially in the FinTech industry, have increasing demands of outbound calls for customers such as debt collection, marketing, anti-fraud calls, and so on. But a large amount of repetitive and mechanical work occupies most of the time of human agents, so the cost of equipment and labor for enterprises is increasing accordingly. At the same time, with the development of artificial intelligence technology in the past few decades, it has become quite common for companies to use new technologies such as Big Data and artificial intelligence to empower outbound call businesses. The intelligent outbound robot is a typical application of the artificial intelligence technology in the field of outbound call businesses. It is mainly used to communicate with customers in order to accomplish a certain target. It has the characteristics of low cost, high reuse, and easy compliance, which has attracted more attention from the industry. At present, there are two kinds of intelligent outbound robots in the industry but both of them still leave large room for improvement. One kind of them is based on a finite state machine relying on the configuration of jump conditions and corresponding nodes based on manual experience. This kind of intelligent outbound robot is also called a flow-based robot. For example, the schematic diagram of the working model of a flow-based robot for debt collection is shown in Fig.\ref{fig:label}. In each round, the robot will reply to the user with the words corresponding to each node.