 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Matching: Category-Guided Latent Intent Reasoning for Generative Retrieval in E-Commerce
Jun 05, 2026Generative retrieval offers a new paradigm for e-commerce search by mapping user queries directly to product Semantic Identifiers (SIDs). However, e-commerce queries are often short, noisy, attribute-heavy, and associated with multiple category-consistent products, creating a substantial representation gap between natural-language shopping intent and artificially constructed item SIDs. Explicit Chain-of-Thought (CoT) reasoning can help bridge this gap, but its extra generation cost is difficult to reconcile with the low-latency requirements of online e-commerce systems. To address this challenge, we propose CaLIR (Category-guided Latent Intent Reasoning), a category-guided latent intent reasoning framework for e-commerce generative retrieval. Rather than generating explicit textual rationales, CaLIR learns continuous latent intent states before SID decoding and uses product category hierarchies as a natural scaffold for coarse-to-fine intent reasoning. Specifically, we introduce hierarchical semantic reasoning to align latent states with category-level shopping intent, and query-wise reasoning enhancement to model diverse intent paths under multi-positive queries. CaLIR further combines a query-specific dynamic prefix trie, assembled from pre-indexed category-level tries, with reasoning-aware constrained decoding. Experiments on multilingual e-commerce search datasets show that CaLIR achieves a better balance between retrieval effectiveness and inference efficiency than existing methods, while also demonstrating transferability and robustness across induced hierarchies and different generative backbones.
Multi-Aspect Cross-modal Quantization for Generative Recommendation
Nov 19, 2025Generative Recommendation (GR) has emerged as a new paradigm in recommender systems. This approach relies on quantized representations to discretize item features, modeling users' historical interactions as sequences of discrete tokens. Based on these tokenized sequences, GR predicts the next item by employing next-token prediction methods. The challenges of GR lie in constructing high-quality semantic identifiers (IDs) that are hierarchically organized, minimally conflicting, and conducive to effective generative model training. However, current approaches remain limited in their ability to harness multimodal information and to capture the deep and intricate interactions among diverse modalities, both of which are essential for learning high-quality semantic IDs and for effectively training GR models. To address this, we propose Multi-Aspect Cross-modal quantization for generative Recommendation (MACRec), which introduces multimodal information and incorporates it into both semantic ID learning and generative model training from different aspects. Specifically, we first introduce cross-modal quantization during the ID learning process, which effectively reduces conflict rates and thus improves codebook usability through the complementary integration of multimodal information. In addition, to further enhance the generative ability of our GR model, we incorporate multi-aspect cross-modal alignments, including the implicit and explicit alignments. Finally, we conduct extensive experiments on three well-known recommendation datasets to demonstrate the effectiveness of our proposed method.
What Makes Reasoning Invalid: Echo Reflection Mitigation for Large Language Models
Nov 09, 2025
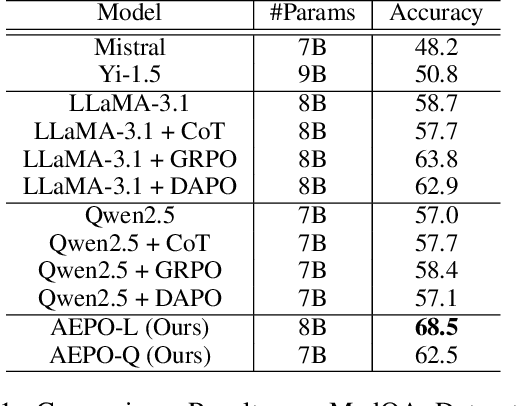
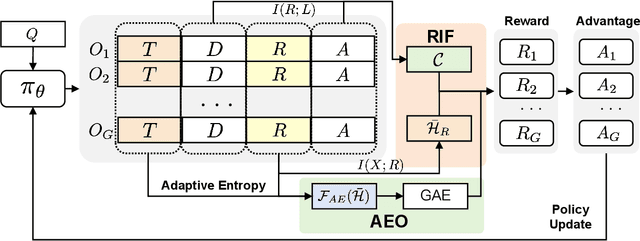
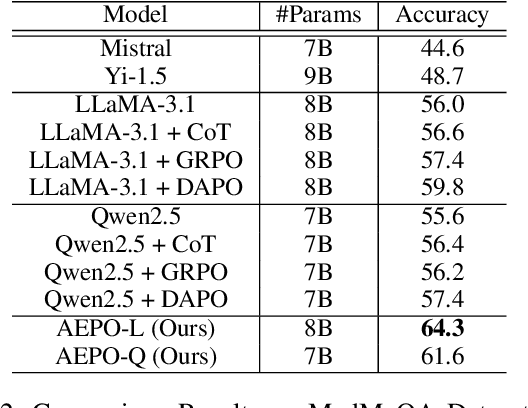
Large Language Models (LLMs) have demonstrated remarkable performance across a wide range of reasoning tasks. Recent methods have further improved LLM performance in complex mathematical reasoning. However, when extending these methods beyond the domain of mathematical reasoning to tasks involving complex domain-specific knowledge, we observe a consistent failure of LLMs to generate novel insights during the reflection stage. Instead of conducting genuine cognitive refinement, the model tends to mechanically reiterate earlier reasoning steps without introducing new information or perspectives, a phenomenon referred to as "Echo Reflection". We attribute this behavior to two key defects: (1) Uncontrollable information flow during response generation, which allows premature intermediate thoughts to propagate unchecked and distort final decisions; (2) Insufficient exploration of internal knowledge during reflection, leading to repeating earlier findings rather than generating new cognitive insights. Building on these findings, we proposed a novel reinforcement learning method termed Adaptive Entropy Policy Optimization (AEPO). Specifically, the AEPO framework consists of two major components: (1) Reflection-aware Information Filtration, which quantifies the cognitive information flow and prevents the final answer from being affected by earlier bad cognitive information; (2) Adaptive-Entropy Optimization, which dynamically balances exploration and exploitation across different reasoning stages, promoting both reflective diversity and answer correctness. Extensive experiments demonstrate that AEPO consistently achieves state-of-the-art performance over mainstream reinforcement learning baselines across diverse benchmarks.
Truth in the Few: High-Value Data Selection for Efficient Multi-Modal Reasoning
Jun 05, 2025While multi-modal large language models (MLLMs) have made significant progress in complex reasoning tasks via reinforcement learning, it is commonly believed that extensive training data is necessary for improving multi-modal reasoning ability, inevitably leading to data redundancy and substantial computational costs. However, can smaller high-value datasets match or outperform full corpora for multi-modal reasoning in MLLMs? In this work, we challenge this assumption through a key observation: meaningful multi-modal reasoning is triggered by only a sparse subset of training samples, termed cognitive samples, whereas the majority contribute marginally. Building on this insight, we propose a novel data selection paradigm termed Reasoning Activation Potential (RAP), which identifies cognitive samples by estimating each sample's potential to stimulate genuine multi-modal reasoning by two complementary estimators: 1) Causal Discrepancy Estimator (CDE) based on the potential outcome model principle, eliminates samples that overly rely on language priors by comparing outputs between multi-modal and text-only inputs; 2) Attention Confidence Estimator (ACE), which exploits token-level self-attention to discard samples dominated by irrelevant but over-emphasized tokens in intermediate reasoning stages. Moreover, we introduce a Difficulty-aware Replacement Module (DRM) to substitute trivial instances with cognitively challenging ones, thereby ensuring complexity for robust multi-modal reasoning. Experiments on six datasets show that our RAP method consistently achieves superior performance using only 9.3% of the training data, while reducing computational costs by over 43%. Our code is available at https://github.com/Leo-ssl/RAP.
Learning Actionable World Models for Industrial Process Control
Mar 03, 2025



To go from (passive) process monitoring to active process control, an effective AI system must learn about the behavior of the complex system from very limited training data, forming an ad-hoc digital twin with respect to process in- and outputs that captures the consequences of actions on the process's world. We propose a novel methodology based on learning world models that disentangles process parameters in the learned latent representation, allowing for fine-grained control. Representation learning is driven by the latent factors that influence the processes through contrastive learning within a joint embedding predictive architecture. This makes changes in representations predictable from changes in inputs and vice versa, facilitating interpretability of key factors responsible for process variations, paving the way for effective control actions to keep the process within operational bounds. The effectiveness of our method is validated on the example of plastic injection molding, demonstrating practical relevance in proposing specific control actions for a notoriously unstable process.
AI Agents for Computer Use: A Review of Instruction-based Computer Control, GUI Automation, and Operator Assistants
Jan 27, 2025



Instruction-based computer control agents (CCAs) execute complex action sequences on personal computers or mobile devices to fulfill tasks using the same graphical user interfaces as a human user would, provided instructions in natural language. This review offers a comprehensive overview of the emerging field of instruction-based computer control, examining available agents -- their taxonomy, development, and respective resources -- and emphasizing the shift from manually designed, specialized agents to leveraging foundation models such as large language models (LLMs) and vision-language models (VLMs). We formalize the problem and establish a taxonomy of the field to analyze agents from three perspectives: (a) the environment perspective, analyzing computer environments; (b) the interaction perspective, describing observations spaces (e.g., screenshots, HTML) and action spaces (e.g., mouse and keyboard actions, executable code); and (c) the agent perspective, focusing on the core principle of how an agent acts and learns to act. Our framework encompasses both specialized and foundation agents, facilitating their comparative analysis and revealing how prior solutions in specialized agents, such as an environment learning step, can guide the development of more capable foundation agents. Additionally, we review current CCA datasets and CCA evaluation methods and outline the challenges to deploying such agents in a productive setting. In total, we review and classify 86 CCAs and 33 related datasets. By highlighting trends, limitations, and future research directions, this work presents a comprehensive foundation to obtain a broad understanding of the field and push its future development.
Augmenting the Veracity and Explanations of Complex Fact Checking via Iterative Self-Revision with LLMs
Oct 19, 2024
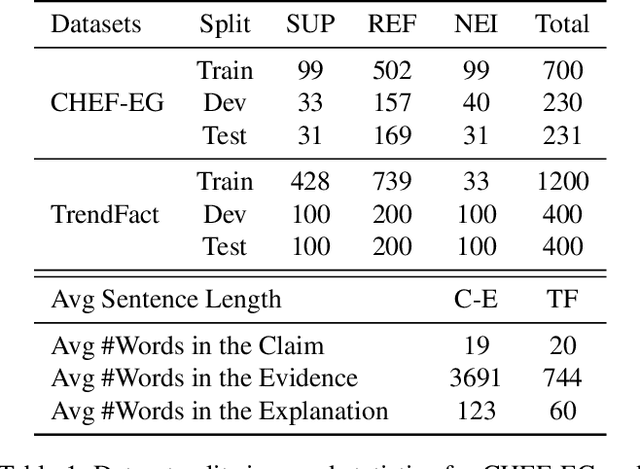
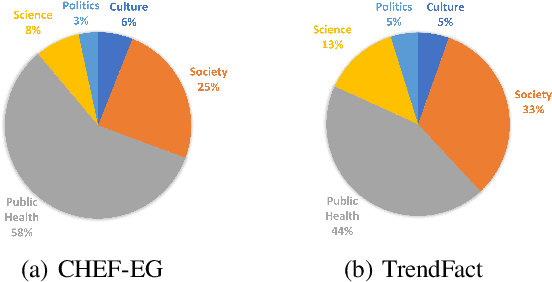
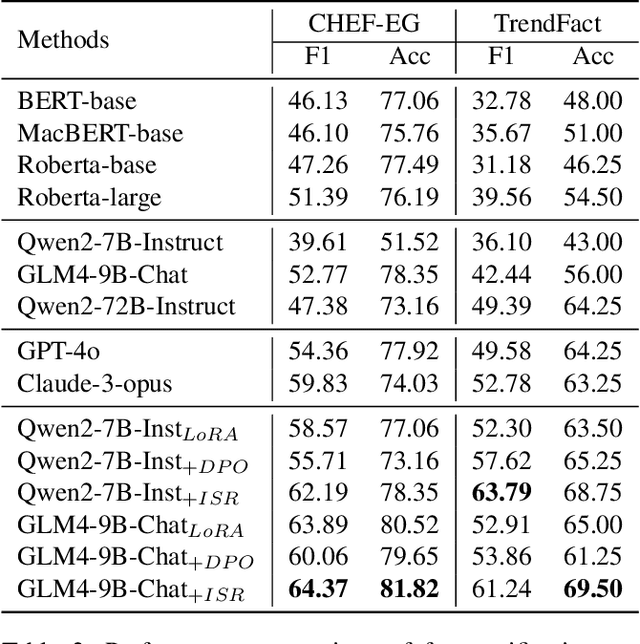
Explanation generation plays a more pivotal role than fact verification in producing interpretable results and facilitating comprehensive fact-checking, which has recently garnered considerable attention. However, previous studies on explanation generation has shown several limitations, such as being confined to English scenarios, involving overly complex inference processes, and not fully unleashing the potential of the mutual feedback between veracity labels and explanation texts. To address these issues, we construct two complex fact-checking datasets in the Chinese scenarios: CHEF-EG and TrendFact. These datasets involve complex facts in areas such as health, politics, and society, presenting significant challenges for fact verification methods. In response to these challenges, we propose a unified framework called FactISR (Augmenting Fact-Checking via Iterative Self-Revision) to perform mutual feedback between veracity and explanations by leveraging the capabilities of large language models(LLMs). FactISR uses a single model to address tasks such as fact verification and explanation generation. Its self-revision mechanism can further revision the consistency between veracity labels, explanation texts, and evidence, as well as eliminate irrelevant noise. We conducted extensive experiments with baselines and FactISR on the proposed datasets. The experimental results demonstrate the effectiveness of our method.
Personalized Image Generation with Large Multimodal Models
Oct 18, 2024



Personalized content filtering, such as recommender systems, has become a critical infrastructure to alleviate information overload. However, these systems merely filter existing content and are constrained by its limited diversity, making it difficult to meet users' varied content needs. To address this limitation, personalized content generation has emerged as a promising direction with broad applications. Nevertheless, most existing research focuses on personalized text generation, with relatively little attention given to personalized image generation. The limited work in personalized image generation faces challenges in accurately capturing users' visual preferences and needs from noisy user-interacted images and complex multimodal instructions. Worse still, there is a lack of supervised data for training personalized image generation models. To overcome the challenges, we propose a Personalized Image Generation Framework named Pigeon, which adopts exceptional large multimodal models with three dedicated modules to capture users' visual preferences and needs from noisy user history and multimodal instructions. To alleviate the data scarcity, we introduce a two-stage preference alignment scheme, comprising masked preference reconstruction and pairwise preference alignment, to align Pigeon with the personalized image generation task. We apply Pigeon to personalized sticker and movie poster generation, where extensive quantitative results and human evaluation highlight its superiority over various generative baselines.
Self-Evolutionary Large Language Models through Uncertainty-Enhanced Preference Optimization
Sep 17, 2024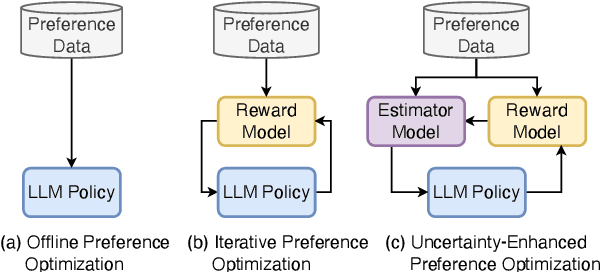
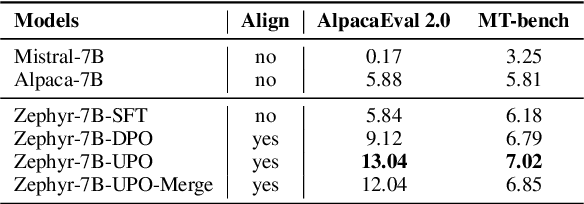
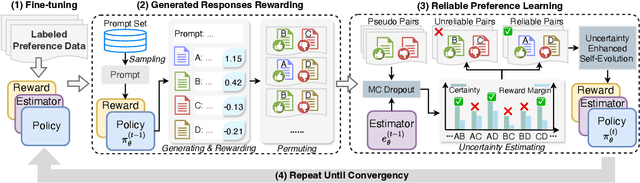
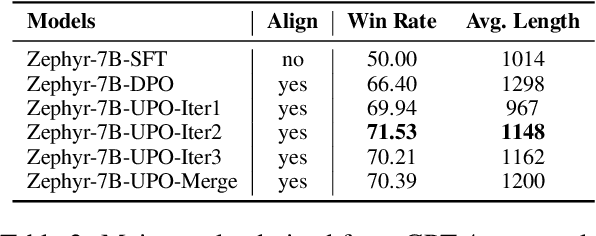
Iterative preference optimization has recently become one of the de-facto training paradigms for large language models (LLMs), but the performance is still underwhelming due to too much noisy preference data yielded in the loop. To combat this issue, we present an \textbf{U}ncertainty-enhanced \textbf{P}reference \textbf{O}ptimization (UPO) framework to make the LLM self-evolve with reliable feedback. The key idea is mitigating the noisy preference data derived from the current policy and reward models by performing pair-wise uncertainty estimation and judiciously reliable feedback sampling. To reach this goal, we thus introduce an estimator model, which incorporates Monte Carlo (MC) dropout in Bayesian neural network (BNN) to perform uncertainty estimation for the preference data derived from the LLM policy. Compared to the existing methods that directly filter generated responses based on the reward score, the estimator focuses on the model uncertainty in a pair-wise manner and effectively bypasses the confirmation bias problem of the reward model. Additionally, we also propose an uncertainty-enhanced self-evolution algorithm to improve the robustness of preference optimization and encourage the LLM to generate responses with both high reward and certainty. Extensive experiments over multiple benchmarks demonstrate that our framework substantially alleviates the noisy problem and improves the performance of iterative preference optimization.
Personalized Interpretation on Federated Learning: A Virtual Concepts approach
Jun 28, 2024



Tackling non-IID data is an open challenge in federated learning research. Existing FL methods, including robust FL and personalized FL, are designed to improve model performance without consideration of interpreting non-IID across clients. This paper aims to design a novel FL method to robust and interpret the non-IID data across clients. Specifically, we interpret each client's dataset as a mixture of conceptual vectors that each one represents an interpretable concept to end-users. These conceptual vectors could be pre-defined or refined in a human-in-the-loop process or be learnt via the optimization procedure of the federated learning system. In addition to the interpretability, the clarity of client-specific personalization could also be applied to enhance the robustness of the training process on FL system. The effectiveness of the proposed method have been validated on benchmark datasets.