 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagnosing Harmful Continuation in Answer-Correct Long-CoT Training Traces
May 28, 2026Long chain-of-thought (CoT) traces are widely used as supervision for reasoning-oriented LLM SFT, yet answer-correct traces can still lead to markedly different fine-tuning outcomes. We study post-conclusion continuation in answer-correct long-CoT data: a continuation where the answer appears sufficiently supported, but the trace continues with additional reasoning that remains in the supervised target. To test its training effect, we use a delete-only editor to construct answer-preserving suffix removal and compare CoT-based SFT on the original and processed traces. We observe improved SFT outcomes after removing the editor-identified post-conclusion continuation, suggesting that this continuation is harmful to training in our setting. We therefore refer to this empirically supported phenomenon as harmful continuation. Beyond this intervention, we further characterize the removed post-conclusion continuation through uncertainty and hidden-state progress. We observe persistent local uncertainty together with weakened terminal-directional progress, forming an uncertainty--geometry mismatch. Finally, we instantiate Harmful Continuation Cut (HCC), a lightweight boundary proxy that approximates the editor-identified post-conclusion continuation boundary.
Multimodal Learning on Low-Quality Data with Conformal Predictive Self-Calibration
May 05, 2026Multimodal learning often grapples with the challenge of low-quality data, which predominantly manifests as two facets: modality imbalance and noisy corruption. While these issues are often studied in isolation, we argue that they share a common root in the predictive uncertainty towards the reliability of individual modalities and instances during learning. In this paper, we propose a unified framework, termed Conformal Predictive Self-Calibration (CPSC), which leverages conformal prediction to equip the model with the ability to perform self-guided calibration on-the-fly. The core of our proposed CPSC lies in a novel self-calibrating training loop that seamlessly integrates two key modules: (1) Representation Self-Calibration, which decomposes unimodal features into components, and selectively fuses the most robust ones identified by a conformal predictor to enhance feature resilience. (2) Gradient Self-Calibration, which recalibrates the gradient flow during backpropagation based on instance-wise reliability scores, steering the optimization towards more trustworthy directions. Furthermore, we also devise a self-update strategy for the conformal predictor to ensure the entire system co-evolves consistently throughout the training process. Extensive experiments on six benchmark datasets under both imbalanced and noisy settings demonstrate that our CPSC framework consistently outperforms existing state-of-the-art methods. Our code is available at https://github.com/XunCHN/CPSC.
Efficiency Follows Global-Local Decoupling
Mar 20, 2026Modern vision models must capture image-level context without sacrificing local detail while remaining computationally affordable. We revisit this tradeoff and advance a simple principle: decouple the roles of global reasoning and local representation. To operationalize this principle, we introduce ConvNeur, a two-branch architecture in which a lightweight neural memory branch aggregates global context on a compact set of tokens, and a locality-preserving branch extracts fine structure. A learned gate lets global cues modulate local features without entangling their objectives. This separation yields subquadratic scaling with image size, retains inductive priors associated with local processing, and reduces overhead relative to fully global attention. On standard classification, detection, and segmentation benchmarks, ConvNeur matches or surpasses comparable alternatives at similar or lower compute and offers favorable accuracy versus latency trade-offs at similar budgets. These results support the view that efficiency follows global-local decoupling.
PCA-Seg: Revisiting Cost Aggregation for Open-Vocabulary Semantic and Part Segmentation
Mar 18, 2026Recent advances in vision-language models (VLMs) have garnered substantial attention in open-vocabulary semantic and part segmentation (OSPS). However, existing methods extract image-text alignment cues from cost volumes through a serial structure of spatial and class aggregations, leading to knowledge interference between class-level semantics and spatial context. Therefore, this paper proposes a simple yet effective parallel cost aggregation (PCA-Seg) paradigm to alleviate the above challenge, enabling the model to capture richer vision-language alignment information from cost volumes. Specifically, we design an expert-driven perceptual learning (EPL) module that efficiently integrates semantic and contextual streams. It incorporates a multi-expert parser to extract complementary features from multiple perspectives. In addition, a coefficient mapper is designed to adaptively learn pixel-specific weights for each feature, enabling the integration of complementary knowledge into a unified and robust feature embedding. Furthermore, we propose a feature orthogonalization decoupling (FOD) strategy to mitigate redundancy between the semantic and contextual streams, which allows the EPL module to learn diverse knowledge from orthogonalized features. Extensive experiments on eight benchmarks show that each parallel block in PCA-Seg adds merely 0.35M parameters while achieving state-of-the-art OSPS performance.
Iris: Bringing Real-World Priors into Diffusion Model for Monocular Depth Estimation
Mar 17, 2026In this paper, we propose \textbf{Iris}, a deterministic framework for Monocular Depth Estimation (MDE) that integrates real-world priors into the diffusion model. Conventional feed-forward methods rely on massive training data, yet still miss details. Previous diffusion-based methods leverage rich generative priors yet struggle with synthetic-to-real domain transfer. Iris, in contrast, preserves fine details, generalizes strongly from synthetic to real scenes, and remains efficient with limited training data. To this end, we introduce a two-stage Priors-to-Geometry Deterministic (PGD) schedule: the prior stage uses Spectral-Gated Distillation (SGD) to transfer low-frequency real priors while leaving high-frequency details unconstrained, and the geometry stage applies Spectral-Gated Consistency (SGC) to enforce high-frequency fidelity while refining with synthetic ground truth. The two stages share weights and are executed with a high-to-low timestep schedule. Extensive experimental results confirm that Iris achieves significant improvements in MDE performance with strong in-the-wild generalization.
Towards Remote Sensing Change Detection with Neural Memory
Feb 11, 2026Remote sensing change detection is essential for environmental monitoring, urban planning, and related applications. However, current methods often struggle to capture long-range dependencies while maintaining computational efficiency. Although Transformers can effectively model global context, their quadratic complexity poses scalability challenges, and existing linear attention approaches frequently fail to capture intricate spatiotemporal relationships. Drawing inspiration from the recent success of Titans in language tasks, we present ChangeTitans, the Titans-based framework for remote sensing change detection. Specifically, we propose VTitans, the first Titans-based vision backbone that integrates neural memory with segmented local attention, thereby capturing long-range dependencies while mitigating computational overhead. Next, we present a hierarchical VTitans-Adapter to refine multi-scale features across different network layers. Finally, we introduce TS-CBAM, a two-stream fusion module leveraging cross-temporal attention to suppress pseudo-changes and enhance detection accuracy. Experimental evaluations on four benchmark datasets (LEVIR-CD, WHU-CD, LEVIR-CD+, and SYSU-CD) demonstrate that ChangeTitans achieves state-of-the-art results, attaining \textbf{84.36\%} IoU and \textbf{91.52\%} F1-score on LEVIR-CD, while remaining computationally competitive.
Taming SAM3 in the Wild: A Concept Bank for Open-Vocabulary Segmentation
Feb 06, 2026The recent introduction of \texttt{SAM3} has revolutionized Open-Vocabulary Segmentation (OVS) through \textit{promptable concept segmentation}, which grounds pixel predictions in flexible concept prompts. However, this reliance on pre-defined concepts makes the model vulnerable: when visual distributions shift (\textit{data drift}) or conditional label distributions evolve (\textit{concept drift}) in the target domain, the alignment between visual evidence and prompts breaks down. In this work, we present \textsc{ConceptBank}, a parameter-free calibration framework to restore this alignment on the fly. Instead of adhering to static prompts, we construct a dataset-specific concept bank from the target statistics. Our approach (\textit{i}) anchors target-domain evidence via class-wise visual prototypes, (\textit{ii}) mines representative supports to suppress outliers under data drift, and (\textit{iii}) fuses candidate concepts to rectify concept drift. We demonstrate that \textsc{ConceptBank} effectively adapts \texttt{SAM3} to distribution drifts, including challenging natural-scene and remote-sensing scenarios, establishing a new baseline for robustness and efficiency in OVS. Code and model are available at https://github.com/pgsmall/ConceptBank.
Combating Noisy Labels through Fostering Self- and Neighbor-Consistency
Jan 19, 2026Label noise is pervasive in various real-world scenarios, posing challenges in supervised deep learning. Deep networks are vulnerable to such label-corrupted samples due to the memorization effect. One major stream of previous methods concentrates on identifying clean data for training. However, these methods often neglect imbalances in label noise across different mini-batches and devote insufficient attention to out-of-distribution noisy data. To this end, we propose a noise-robust method named Jo-SNC (\textbf{Jo}int sample selection and model regularization based on \textbf{S}elf- and \textbf{N}eighbor-\textbf{C}onsistency). Specifically, we propose to employ the Jensen-Shannon divergence to measure the ``likelihood'' of a sample being clean or out-of-distribution. This process factors in the nearest neighbors of each sample to reinforce the reliability of clean sample identification. We design a self-adaptive, data-driven thresholding scheme to adjust per-class selection thresholds. While clean samples undergo conventional training, detected in-distribution and out-of-distribution noisy samples are trained following partial label learning and negative learning, respectively. Finally, we advance the model performance further by proposing a triplet consistency regularization that promotes self-prediction consistency, neighbor-prediction consistency, and feature consistency. Extensive experiments on various benchmark datasets and comprehensive ablation studies demonstrate the effectiveness and superiority of our approach over existing state-of-the-art methods.
What Makes Reasoning Invalid: Echo Reflection Mitigation for Large Language Models
Nov 09, 2025
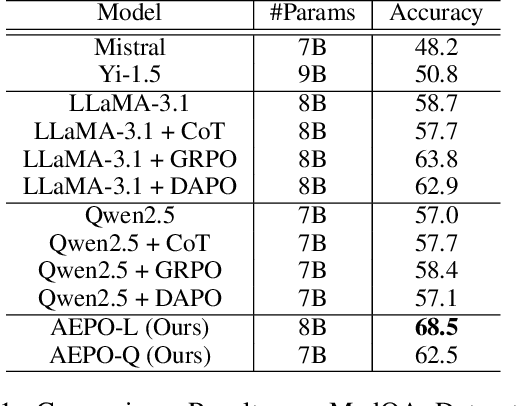
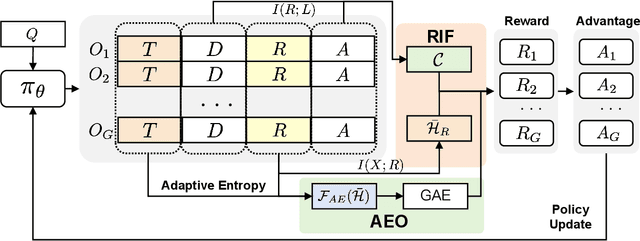
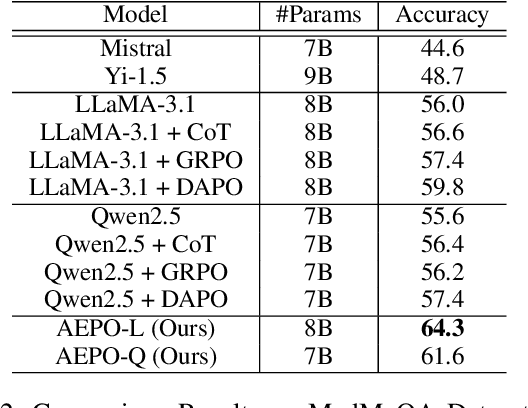
Large Language Models (LLMs) have demonstrated remarkable performance across a wide range of reasoning tasks. Recent methods have further improved LLM performance in complex mathematical reasoning. However, when extending these methods beyond the domain of mathematical reasoning to tasks involving complex domain-specific knowledge, we observe a consistent failure of LLMs to generate novel insights during the reflection stage. Instead of conducting genuine cognitive refinement, the model tends to mechanically reiterate earlier reasoning steps without introducing new information or perspectives, a phenomenon referred to as "Echo Reflection". We attribute this behavior to two key defects: (1) Uncontrollable information flow during response generation, which allows premature intermediate thoughts to propagate unchecked and distort final decisions; (2) Insufficient exploration of internal knowledge during reflection, leading to repeating earlier findings rather than generating new cognitive insights. Building on these findings, we proposed a novel reinforcement learning method termed Adaptive Entropy Policy Optimization (AEPO). Specifically, the AEPO framework consists of two major components: (1) Reflection-aware Information Filtration, which quantifies the cognitive information flow and prevents the final answer from being affected by earlier bad cognitive information; (2) Adaptive-Entropy Optimization, which dynamically balances exploration and exploitation across different reasoning stages, promoting both reflective diversity and answer correctness. Extensive experiments demonstrate that AEPO consistently achieves state-of-the-art performance over mainstream reinforcement learning baselines across diverse benchmarks.
Truth in the Few: High-Value Data Selection for Efficient Multi-Modal Reasoning
Jun 05, 2025While multi-modal large language models (MLLMs) have made significant progress in complex reasoning tasks via reinforcement learning, it is commonly believed that extensive training data is necessary for improving multi-modal reasoning ability, inevitably leading to data redundancy and substantial computational costs. However, can smaller high-value datasets match or outperform full corpora for multi-modal reasoning in MLLMs? In this work, we challenge this assumption through a key observation: meaningful multi-modal reasoning is triggered by only a sparse subset of training samples, termed cognitive samples, whereas the majority contribute marginally. Building on this insight, we propose a novel data selection paradigm termed Reasoning Activation Potential (RAP), which identifies cognitive samples by estimating each sample's potential to stimulate genuine multi-modal reasoning by two complementary estimators: 1) Causal Discrepancy Estimator (CDE) based on the potential outcome model principle, eliminates samples that overly rely on language priors by comparing outputs between multi-modal and text-only inputs; 2) Attention Confidence Estimator (ACE), which exploits token-level self-attention to discard samples dominated by irrelevant but over-emphasized tokens in intermediate reasoning stages. Moreover, we introduce a Difficulty-aware Replacement Module (DRM) to substitute trivial instances with cognitively challenging ones, thereby ensuring complexity for robust multi-modal reasoning. Experiments on six datasets show that our RAP method consistently achieves superior performance using only 9.3% of the training data, while reducing computational costs by over 43%. Our code is available at https://github.com/Leo-ssl/RAP.