 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-attention Propagation Network for Zero-Shot Video Object Segmentation
Paper and Code
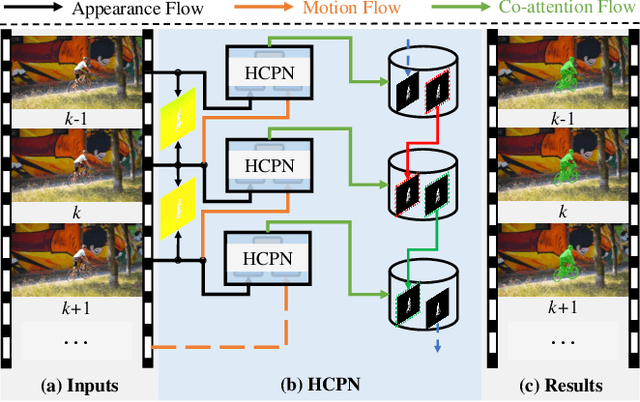
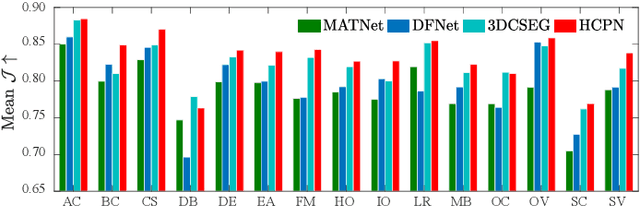

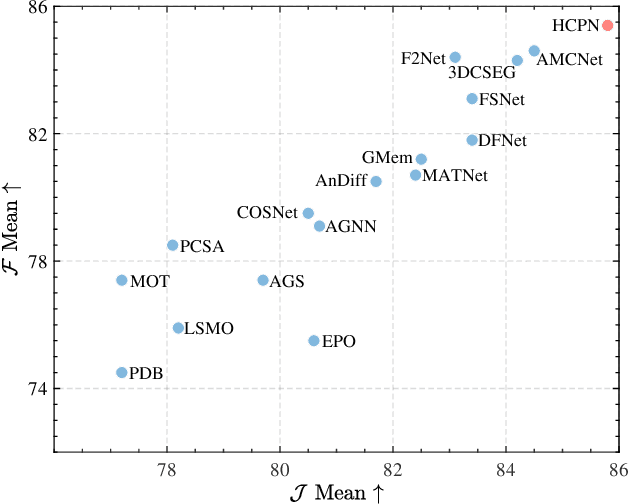
Zero-shot video object segmentation (ZS-VOS) aims to segment foreground objects in a video sequence without prior knowledge of these objects. However, existing ZS-VOS methods often struggle to distinguish between foreground and background or to keep track of the foreground in complex scenarios. The common practice of introducing motion information, such as optical flow, can lead to overreliance on optical flow estimation. To address these challenges, we propose an encoder-decoder-based hierarchical co-attention propagation network (HCPN) capable of tracking and segmenting objects. Specifically, our model is built upon multiple collaborative evolutions of the parallel co-attention module (PCM) and the cross co-attention module (CCM). PCM captures common foreground regions among adjacent appearance and motion features, while CCM further exploits and fuses cross-modal motion features returned by PCM. Our method is progressively trained to achieve hierarchical spatio-temporal feature propagation across the entire video. Experimental results demonstrate that our HCPN outperforms all previous methods on public benchmarks, showcasing its effectiveness for ZS-VOS.