 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Structure Constraints for Weakly Supervised Semantic Segmentation
Jan 20, 2024


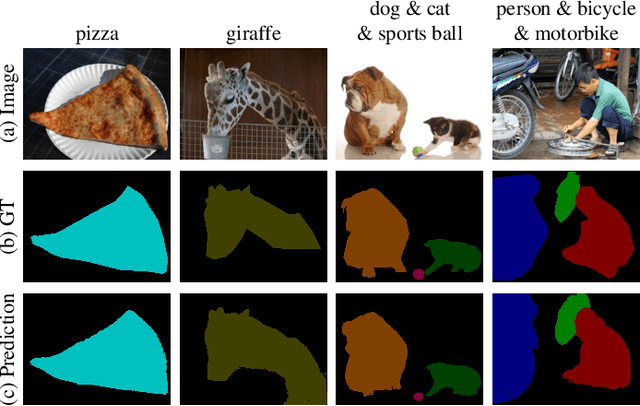
The image-level label has prevailed in weakly supervised semantic segmentation tasks due to its easy availability. Since image-level labels can only indicate the existence or absence of specific categories of objects, visualization-based techniques have been widely adopted to provide object location clues. Considering class activation maps (CAMs) can only locate the most discriminative part of objects, recent approaches usually adopt an expansion strategy to enlarge the activation area for more integral object localization. However, without proper constraints, the expanded activation will easily intrude into the background region. In this paper, we propose spatial structure constraints (SSC) for weakly supervised semantic segmentation to alleviate the unwanted object over-activation of attention expansion. Specifically, we propose a CAM-driven reconstruction module to directly reconstruct the input image from deep CAM features, which constrains the diffusion of last-layer object attention by preserving the coarse spatial structure of the image content. Moreover, we propose an activation self-modulation module to refine CAMs with finer spatial structure details by enhancing regional consistency. Without external saliency models to provide background clues, our approach achieves 72.7\% and 47.0\% mIoU on the PASCAL VOC 2012 and COCO datasets, respectively, demonstrating the superiority of our proposed approach.
Co-attention Propagation Network for Zero-Shot Video Object Segmentation
Apr 08, 2023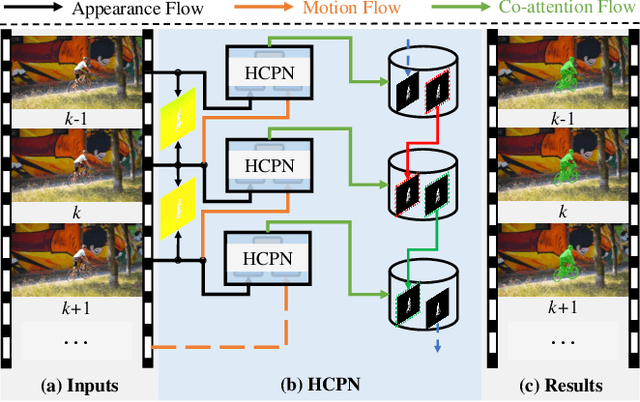
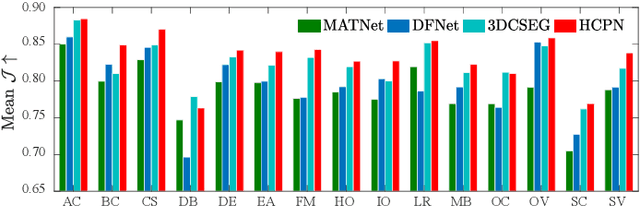

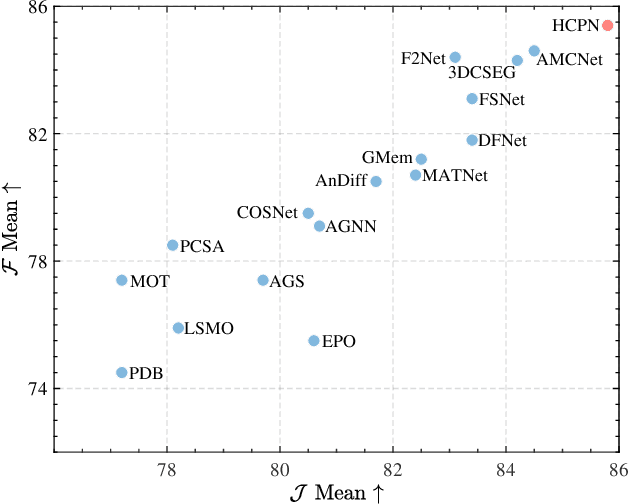
Zero-shot video object segmentation (ZS-VOS) aims to segment foreground objects in a video sequence without prior knowledge of these objects. However, existing ZS-VOS methods often struggle to distinguish between foreground and background or to keep track of the foreground in complex scenarios. The common practice of introducing motion information, such as optical flow, can lead to overreliance on optical flow estimation. To address these challenges, we propose an encoder-decoder-based hierarchical co-attention propagation network (HCPN) capable of tracking and segmenting objects. Specifically, our model is built upon multiple collaborative evolutions of the parallel co-attention module (PCM) and the cross co-attention module (CCM). PCM captures common foreground regions among adjacent appearance and motion features, while CCM further exploits and fuses cross-modal motion features returned by PCM. Our method is progressively trained to achieve hierarchical spatio-temporal feature propagation across the entire video. Experimental results demonstrate that our HCPN outperforms all previous methods on public benchmarks, showcasing its effectiveness for ZS-VOS.
Attention Map Guided Transformer Pruning for Edge Device
Apr 04, 2023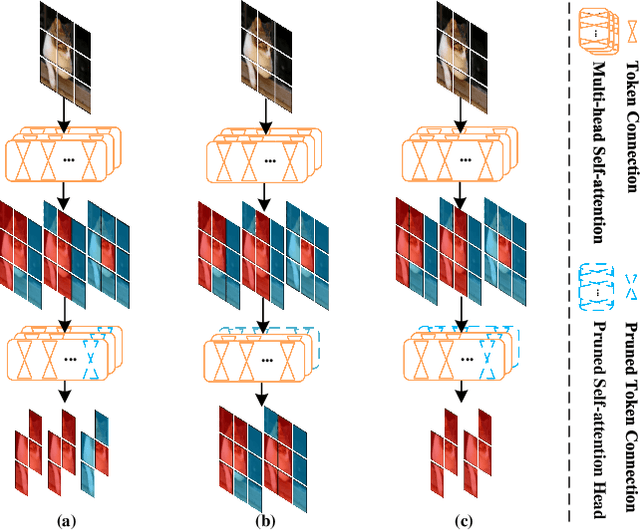
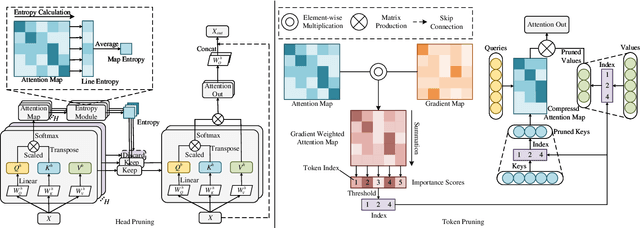
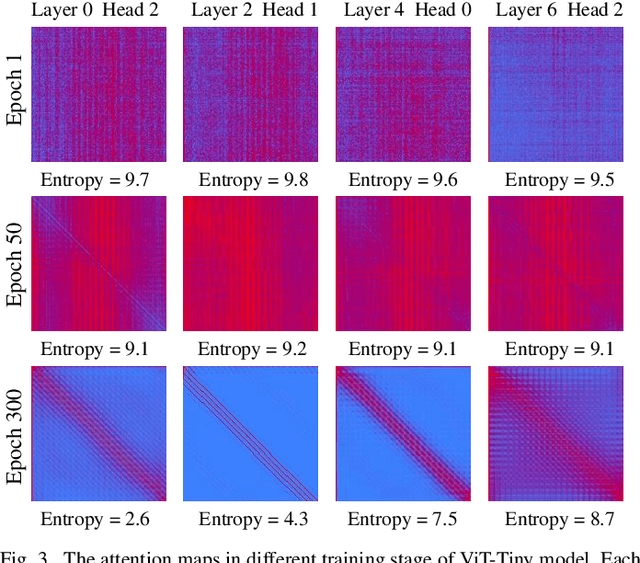
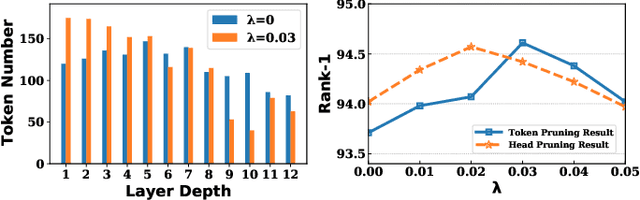
Due to its significant capability of modeling long-range dependencies, vision transformer (ViT) has achieved promising success in both holistic and occluded person re-identification (Re-ID) tasks. However, the inherent problems of transformers such as the huge computational cost and memory footprint are still two unsolved issues that will block the deployment of ViT based person Re-ID models on resource-limited edge devices. Our goal is to reduce both the inference complexity and model size without sacrificing the comparable accuracy on person Re-ID, especially for tasks with occlusion. To this end, we propose a novel attention map guided (AMG) transformer pruning method, which removes both redundant tokens and heads with the guidance of the attention map in a hardware-friendly way. We first calculate the entropy in the key dimension and sum it up for the whole map, and the corresponding head parameters of maps with high entropy will be removed for model size reduction. Then we combine the similarity and first-order gradients of key tokens along the query dimension for token importance estimation and remove redundant key and value tokens to further reduce the inference complexity. Comprehensive experiments on Occluded DukeMTMC and Market-1501 demonstrate the effectiveness of our proposals. For example, our proposed pruning strategy on ViT-Base enjoys \textup{\textbf{29.4\%}} \textup{\textbf{FLOPs}} savings with \textup{\textbf{0.2\%}} drop on Rank-1 and \textup{\textbf{0.4\%}} improvement on mAP, respectively.