 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePKINet-v2: Towards Powerful and Efficient Poly-Kernel Remote Sensing Object Detection
Mar 17, 2026Object detection in remote sensing images (RSIs) is challenged by the coexistence of geometric and spatial complexity: targets may appear with diverse aspect ratios, while spanning a wide range of object sizes under varied contexts. Existing RSI backbones address the two challenges separately, either by adopting anisotropic strip kernels to model slender targets or by using isotropic large kernels to capture broader context. However, such isolated treatments lead to complementary drawbacks: the strip-only design can disrupt spatial coherence for regular-shaped objects and weaken tiny details, whereas isotropic large kernels often introduce severe background noise and geometric mismatch for slender structures. In this paper, we extend PKINet, and present a powerful and efficient backbone that jointly handles both challenges within a unified paradigm named Poly Kernel Inception Network v2 (PKINet-v2). PKINet-v2 synergizes anisotropic axial-strip convolutions with isotropic square kernels and builds a multi-scope receptive field, preserving fine-grained local textures while progressively aggregating long-range context across scales. To enable efficient deployment, we further introduce a Heterogeneous Kernel Re-parameterization (HKR) Strategy that fuses all heterogeneous branches into a single depth-wise convolution for inference, eliminating fragmented kernel launches without accuracy loss. Extensive experiments on four widely-used benchmarks, including DOTA-v1.0, DOTA-v1.5, HRSC2016, and DIOR-R, demonstrate that PKINet-v2 achieves state-of-the-art accuracy while delivering a $\textbf{3.9}\times$ FPS acceleration compared to PKINet-v1, surpassing previous remote sensing backbones in both effectiveness and efficiency.
Iris: Bringing Real-World Priors into Diffusion Model for Monocular Depth Estimation
Mar 17, 2026In this paper, we propose \textbf{Iris}, a deterministic framework for Monocular Depth Estimation (MDE) that integrates real-world priors into the diffusion model. Conventional feed-forward methods rely on massive training data, yet still miss details. Previous diffusion-based methods leverage rich generative priors yet struggle with synthetic-to-real domain transfer. Iris, in contrast, preserves fine details, generalizes strongly from synthetic to real scenes, and remains efficient with limited training data. To this end, we introduce a two-stage Priors-to-Geometry Deterministic (PGD) schedule: the prior stage uses Spectral-Gated Distillation (SGD) to transfer low-frequency real priors while leaving high-frequency details unconstrained, and the geometry stage applies Spectral-Gated Consistency (SGC) to enforce high-frequency fidelity while refining with synthetic ground truth. The two stages share weights and are executed with a high-to-low timestep schedule. Extensive experimental results confirm that Iris achieves significant improvements in MDE performance with strong in-the-wild generalization.
Combating Noisy Labels through Fostering Self- and Neighbor-Consistency
Jan 19, 2026Label noise is pervasive in various real-world scenarios, posing challenges in supervised deep learning. Deep networks are vulnerable to such label-corrupted samples due to the memorization effect. One major stream of previous methods concentrates on identifying clean data for training. However, these methods often neglect imbalances in label noise across different mini-batches and devote insufficient attention to out-of-distribution noisy data. To this end, we propose a noise-robust method named Jo-SNC (\textbf{Jo}int sample selection and model regularization based on \textbf{S}elf- and \textbf{N}eighbor-\textbf{C}onsistency). Specifically, we propose to employ the Jensen-Shannon divergence to measure the ``likelihood'' of a sample being clean or out-of-distribution. This process factors in the nearest neighbors of each sample to reinforce the reliability of clean sample identification. We design a self-adaptive, data-driven thresholding scheme to adjust per-class selection thresholds. While clean samples undergo conventional training, detected in-distribution and out-of-distribution noisy samples are trained following partial label learning and negative learning, respectively. Finally, we advance the model performance further by proposing a triplet consistency regularization that promotes self-prediction consistency, neighbor-prediction consistency, and feature consistency. Extensive experiments on various benchmark datasets and comprehensive ablation studies demonstrate the effectiveness and superiority of our approach over existing state-of-the-art methods.
Foster Adaptivity and Balance in Learning with Noisy Labels
Jul 03, 2024Label noise is ubiquitous in real-world scenarios, posing a practical challenge to supervised models due to its effect in hurting the generalization performance of deep neural networks. Existing methods primarily employ the sample selection paradigm and usually rely on dataset-dependent prior knowledge (\eg, a pre-defined threshold) to cope with label noise, inevitably degrading the adaptivity. Moreover, existing methods tend to neglect the class balance in selecting samples, leading to biased model performance. To this end, we propose a simple yet effective approach named \textbf{SED} to deal with label noise in a \textbf{S}elf-adaptiv\textbf{E} and class-balance\textbf{D} manner. Specifically, we first design a novel sample selection strategy to empower self-adaptivity and class balance when identifying clean and noisy data. A mean-teacher model is then employed to correct labels of noisy samples. Subsequently, we propose a self-adaptive and class-balanced sample re-weighting mechanism to assign different weights to detected noisy samples. Finally, we additionally employ consistency regularization on selected clean samples to improve model generalization performance. Extensive experimental results on synthetic and real-world datasets demonstrate the effectiveness and superiority of our proposed method. The source code has been made available at https://github.com/NUST-Machine-Intelligence-Laboratory/SED.
Relating CNN-Transformer Fusion Network for Change Detection
Jul 03, 2024



While deep learning, particularly convolutional neural networks (CNNs), has revolutionized remote sensing (RS) change detection (CD), existing approaches often miss crucial features due to neglecting global context and incomplete change learning. Additionally, transformer networks struggle with low-level details. RCTNet addresses these limitations by introducing \textbf{(1)} an early fusion backbone to exploit both spatial and temporal features early on, \textbf{(2)} a Cross-Stage Aggregation (CSA) module for enhanced temporal representation, \textbf{(3)} a Multi-Scale Feature Fusion (MSF) module for enriched feature extraction in the decoder, and \textbf{(4)} an Efficient Self-deciphering Attention (ESA) module utilizing transformers to capture global information and fine-grained details for accurate change detection. Extensive experiments demonstrate RCTNet's clear superiority over traditional RS image CD methods, showing significant improvement and an optimal balance between accuracy and computational cost.
Knowledge Transfer with Simulated Inter-Image Erasing for Weakly Supervised Semantic Segmentation
Jul 03, 2024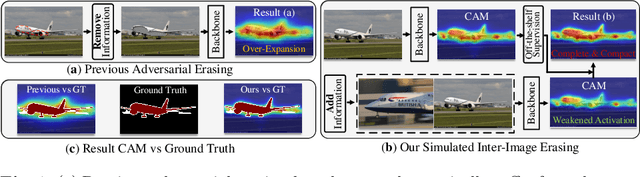
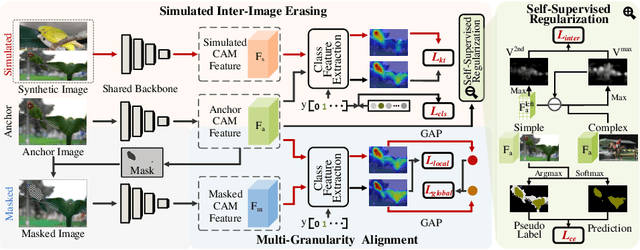
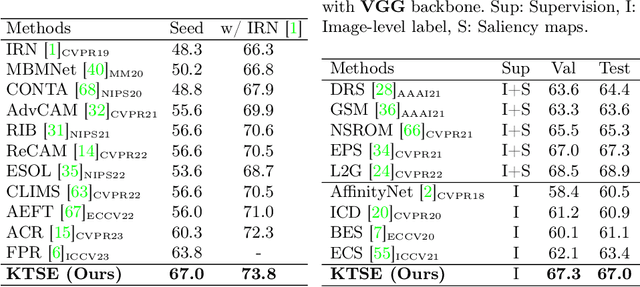
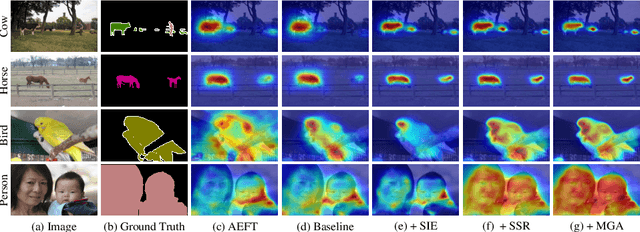
Though adversarial erasing has prevailed in weakly supervised semantic segmentation to help activate integral object regions, existing approaches still suffer from the dilemma of under-activation and over-expansion due to the difficulty in determining when to stop erasing. In this paper, we propose a \textbf{K}nowledge \textbf{T}ransfer with \textbf{S}imulated Inter-Image \textbf{E}rasing (KTSE) approach for weakly supervised semantic segmentation to alleviate the above problem. In contrast to existing erasing-based methods that remove the discriminative part for more object discovery, we propose a simulated inter-image erasing scenario to weaken the original activation by introducing extra object information. Then, object knowledge is transferred from the anchor image to the consequent less activated localization map to strengthen network localization ability. Considering the adopted bidirectional alignment will also weaken the anchor image activation if appropriate constraints are missing, we propose a self-supervised regularization module to maintain the reliable activation in discriminative regions and improve the inter-class object boundary recognition for complex images with multiple categories of objects. In addition, we resort to intra-image erasing and propose a multi-granularity alignment module to gently enlarge the object activation to boost the object knowledge transfer. Extensive experiments and ablation studies on PASCAL VOC 2012 and COCO datasets demonstrate the superiority of our proposed approach. Source codes and models are available at https://github.com/NUST-Machine-Intelligence-Laboratory/KTSE.
Poly Kernel Inception Network for Remote Sensing Detection
Mar 20, 2024Object detection in remote sensing images (RSIs) often suffers from several increasing challenges, including the large variation in object scales and the diverse-ranging context. Prior methods tried to address these challenges by expanding the spatial receptive field of the backbone, either through large-kernel convolution or dilated convolution. However, the former typically introduces considerable background noise, while the latter risks generating overly sparse feature representations. In this paper, we introduce the Poly Kernel Inception Network (PKINet) to handle the above challenges. PKINet employs multi-scale convolution kernels without dilation to extract object features of varying scales and capture local context. In addition, a Context Anchor Attention (CAA) module is introduced in parallel to capture long-range contextual information. These two components work jointly to advance the performance of PKINet on four challenging remote sensing detection benchmarks, namely DOTA-v1.0, DOTA-v1.5, HRSC2016, and DIOR-R.
VideoMAC: Video Masked Autoencoders Meet ConvNets
Feb 29, 2024Recently, the advancement of self-supervised learning techniques, like masked autoencoders (MAE), has greatly influenced visual representation learning for images and videos. Nevertheless, it is worth noting that the predominant approaches in existing masked image / video modeling rely excessively on resource-intensive vision transformers (ViTs) as the feature encoder. In this paper, we propose a new approach termed as \textbf{VideoMAC}, which combines video masked autoencoders with resource-friendly ConvNets. Specifically, VideoMAC employs symmetric masking on randomly sampled pairs of video frames. To prevent the issue of mask pattern dissipation, we utilize ConvNets which are implemented with sparse convolutional operators as encoders. Simultaneously, we present a simple yet effective masked video modeling (MVM) approach, a dual encoder architecture comprising an online encoder and an exponential moving average target encoder, aimed to facilitate inter-frame reconstruction consistency in videos. Additionally, we demonstrate that VideoMAC, empowering classical (ResNet) / modern (ConvNeXt) convolutional encoders to harness the benefits of MVM, outperforms ViT-based approaches on downstream tasks, including video object segmentation (+\textbf{5.2\%} / \textbf{6.4\%} $\mathcal{J}\&\mathcal{F}$), body part propagation (+\textbf{6.3\%} / \textbf{3.1\%} mIoU), and human pose tracking (+\textbf{10.2\%} / \textbf{11.1\%} PCK@0.1).
Learning with Imbalanced Noisy Data by Preventing Bias in Sample Selection
Feb 17, 2024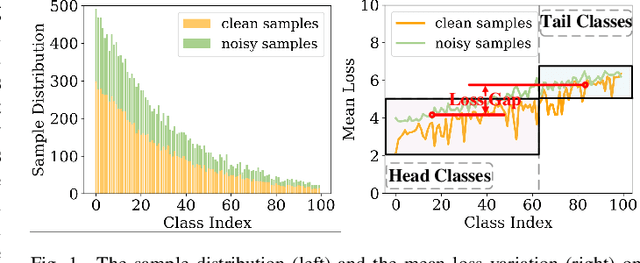
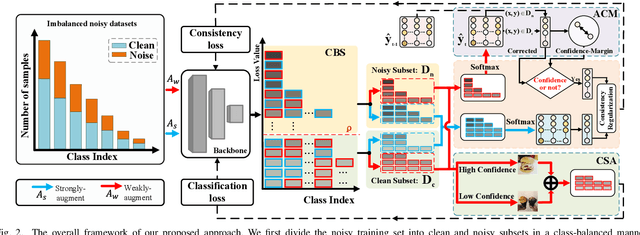
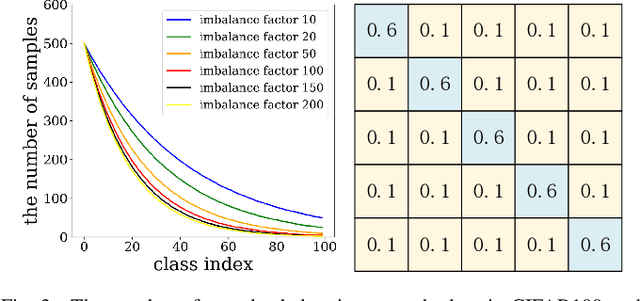
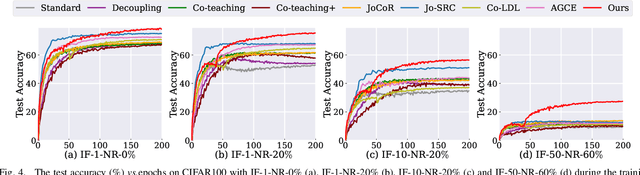
Learning with noisy labels has gained increasing attention because the inevitable imperfect labels in real-world scenarios can substantially hurt the deep model performance. Recent studies tend to regard low-loss samples as clean ones and discard high-loss ones to alleviate the negative impact of noisy labels. However, real-world datasets contain not only noisy labels but also class imbalance. The imbalance issue is prone to causing failure in the loss-based sample selection since the under-learning of tail classes also leans to produce high losses. To this end, we propose a simple yet effective method to address noisy labels in imbalanced datasets. Specifically, we propose Class-Balance-based sample Selection (CBS) to prevent the tail class samples from being neglected during training. We propose Confidence-based Sample Augmentation (CSA) for the chosen clean samples to enhance their reliability in the training process. To exploit selected noisy samples, we resort to prediction history to rectify labels of noisy samples. Moreover, we introduce the Average Confidence Margin (ACM) metric to measure the quality of corrected labels by leveraging the model's evolving training dynamics, thereby ensuring that low-quality corrected noisy samples are appropriately masked out. Lastly, consistency regularization is imposed on filtered label-corrected noisy samples to boost model performance. Comprehensive experimental results on synthetic and real-world datasets demonstrate the effectiveness and superiority of our proposed method, especially in imbalanced scenarios. Comprehensive experimental results on synthetic and real-world datasets demonstrate the effectiveness and superiority of our proposed method, especially in imbalanced scenarios.
Adaptive Integration of Partial Label Learning and Negative Learning for Enhanced Noisy Label Learning
Dec 15, 2023



There has been significant attention devoted to the effectiveness of various domains, such as semi-supervised learning, contrastive learning, and meta-learning, in enhancing the performance of methods for noisy label learning (NLL) tasks. However, most existing methods still depend on prior assumptions regarding clean samples amidst different sources of noise (\eg, a pre-defined drop rate or a small subset of clean samples). In this paper, we propose a simple yet powerful idea called \textbf{NPN}, which revolutionizes \textbf{N}oisy label learning by integrating \textbf{P}artial label learning (PLL) and \textbf{N}egative learning (NL). Toward this goal, we initially decompose the given label space adaptively into the candidate and complementary labels, thereby establishing the conditions for PLL and NL. We propose two adaptive data-driven paradigms of label disambiguation for PLL: hard disambiguation and soft disambiguation. Furthermore, we generate reliable complementary labels using all non-candidate labels for NL to enhance model robustness through indirect supervision. To maintain label reliability during the later stage of model training, we introduce a consistency regularization term that encourages agreement between the outputs of multiple augmentations. Experiments conducted on both synthetically corrupted and real-world noisy datasets demonstrate the superiority of NPN compared to other state-of-the-art (SOTA) methods. The source code has been made available at {\color{purple}{\url{https://github.com/NUST-Machine-Intelligence-Laboratory/NPN}}}.