 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning 3D Representations for Spatial Intelligence from Unposed Multi-View Images
Apr 12, 2026Robust 3D representation learning forms the perceptual foundation of spatial intelligence, enabling downstream tasks in scene understanding and embodied AI. However, learning such representations directly from unposed multi-view images remains challenging. Recent self-supervised methods attempt to unify geometry, appearance, and semantics in a feed-forward manner, but they often suffer from weak geometry induction, limited appearance detail, and inconsistencies between geometry and semantics. We introduce UniSplat, a feed-forward framework designed to address these limitations through three complementary components. First, we propose a dual-masking strategy that strengthens geometry induction in the encoder. By masking both encoder and decoder tokens, and targeting decoder masks toward geometry-rich regions, the model is forced to infer structural information from incomplete visual cues, yielding geometry-aware representations even under unposed inputs. Second, we develop a coarse-to-fine Gaussian splatting strategy that reduces appearance-semantics inconsistencies by progressively refining the radiance field. Finally, to enforce geometric-semantic consistency, we introduce a pose-conditioned recalibration mechanism that interrelates the outputs of multiple heads by re-projecting predicted 3D point and semantic maps into the image plane using estimated camera parameters, and aligning them with corresponding RGB and semantic predictions to ensure cross-task consistency, thereby resolving geometry-semantic mismatches. Together, these components yield unified 3D representations that are robust to unposed, sparse-view inputs and generalize across diverse tasks, laying a perceptual foundation for spatial intelligence.
A Conditional Probability Framework for Compositional Zero-shot Learning
Jul 23, 2025Compositional Zero-Shot Learning (CZSL) aims to recognize unseen combinations of known objects and attributes by leveraging knowledge from previously seen compositions. Traditional approaches primarily focus on disentangling attributes and objects, treating them as independent entities during learning. However, this assumption overlooks the semantic constraints and contextual dependencies inside a composition. For example, certain attributes naturally pair with specific objects (e.g., "striped" applies to "zebra" or "shirts" but not "sky" or "water"), while the same attribute can manifest differently depending on context (e.g., "young" in "young tree" vs. "young dog"). Thus, capturing attribute-object interdependence remains a fundamental yet long-ignored challenge in CZSL. In this paper, we adopt a Conditional Probability Framework (CPF) to explicitly model attribute-object dependencies. We decompose the probability of a composition into two components: the likelihood of an object and the conditional likelihood of its attribute. To enhance object feature learning, we incorporate textual descriptors to highlight semantically relevant image regions. These enhanced object features then guide attribute learning through a cross-attention mechanism, ensuring better contextual alignment. By jointly optimizing object likelihood and conditional attribute likelihood, our method effectively captures compositional dependencies and generalizes well to unseen compositions. Extensive experiments on multiple CZSL benchmarks demonstrate the superiority of our approach. Code is available at here.
PAMD: Plausibility-Aware Motion Diffusion Model for Long Dance Generation
May 26, 2025Computational dance generation is crucial in many areas, such as art, human-computer interaction, virtual reality, and digital entertainment, particularly for generating coherent and expressive long dance sequences. Diffusion-based music-to-dance generation has made significant progress, yet existing methods still struggle to produce physically plausible motions. To address this, we propose Plausibility-Aware Motion Diffusion (PAMD), a framework for generating dances that are both musically aligned and physically realistic. The core of PAMD lies in the Plausible Motion Constraint (PMC), which leverages Neural Distance Fields (NDFs) to model the actual pose manifold and guide generated motions toward a physically valid pose manifold. To provide more effective guidance during generation, we incorporate Prior Motion Guidance (PMG), which uses standing poses as auxiliary conditions alongside music features. To further enhance realism for complex movements, we introduce the Motion Refinement with Foot-ground Contact (MRFC) module, which addresses foot-skating artifacts by bridging the gap between the optimization objective in linear joint position space and the data representation in nonlinear rotation space. Extensive experiments show that PAMD significantly improves musical alignment and enhances the physical plausibility of generated motions. This project page is available at: https://mucunzhuzhu.github.io/PAMD-page/.
Vector Quantization Prompting for Continual Learning
Oct 27, 2024



Continual learning requires to overcome catastrophic forgetting when training a single model on a sequence of tasks. Recent top-performing approaches are prompt-based methods that utilize a set of learnable parameters (i.e., prompts) to encode task knowledge, from which appropriate ones are selected to guide the fixed pre-trained model in generating features tailored to a certain task. However, existing methods rely on predicting prompt identities for prompt selection, where the identity prediction process cannot be optimized with task loss. This limitation leads to sub-optimal prompt selection and inadequate adaptation of pre-trained features for a specific task. Previous efforts have tried to address this by directly generating prompts from input queries instead of selecting from a set of candidates. However, these prompts are continuous, which lack sufficient abstraction for task knowledge representation, making them less effective for continual learning. To address these challenges, we propose VQ-Prompt, a prompt-based continual learning method that incorporates Vector Quantization (VQ) into end-to-end training of a set of discrete prompts. In this way, VQ-Prompt can optimize the prompt selection process with task loss and meanwhile achieve effective abstraction of task knowledge for continual learning. Extensive experiments show that VQ-Prompt outperforms state-of-the-art continual learning methods across a variety of benchmarks under the challenging class-incremental setting. The code is available at \href{https://github.com/jiaolifengmi/VQ-Prompt}{this https URL}.
Poly Kernel Inception Network for Remote Sensing Detection
Mar 20, 2024Object detection in remote sensing images (RSIs) often suffers from several increasing challenges, including the large variation in object scales and the diverse-ranging context. Prior methods tried to address these challenges by expanding the spatial receptive field of the backbone, either through large-kernel convolution or dilated convolution. However, the former typically introduces considerable background noise, while the latter risks generating overly sparse feature representations. In this paper, we introduce the Poly Kernel Inception Network (PKINet) to handle the above challenges. PKINet employs multi-scale convolution kernels without dilation to extract object features of varying scales and capture local context. In addition, a Context Anchor Attention (CAA) module is introduced in parallel to capture long-range contextual information. These two components work jointly to advance the performance of PKINet on four challenging remote sensing detection benchmarks, namely DOTA-v1.0, DOTA-v1.5, HRSC2016, and DIOR-R.
Evaluating Text-to-Image Generative Models: An Empirical Study on Human Image Synthesis
Mar 08, 2024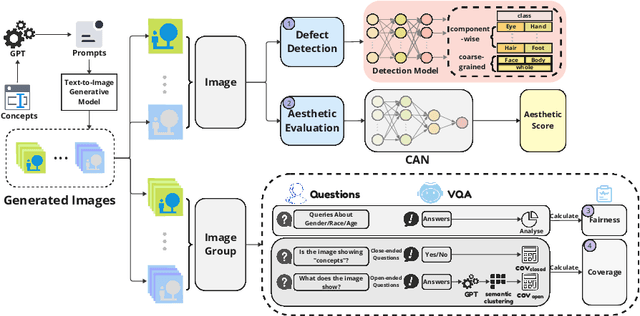
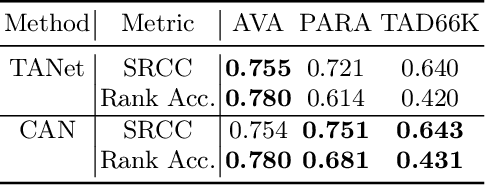
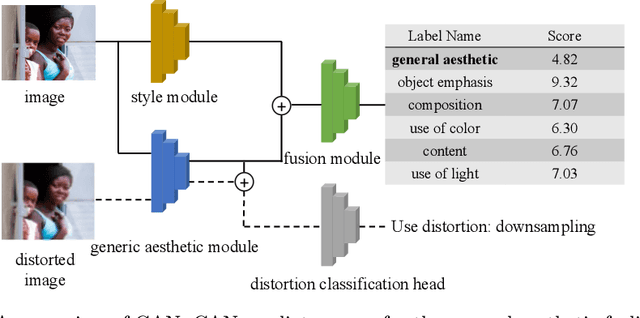
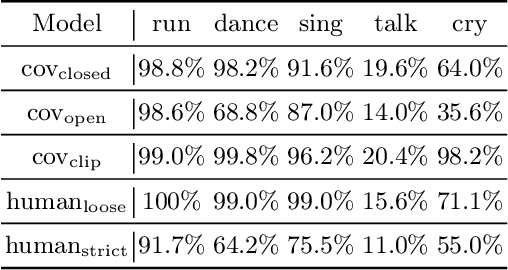
In this paper, we present an empirical study introducing a nuanced evaluation framework for text-to-image (T2I) generative models, applied to human image synthesis. Our framework categorizes evaluations into two distinct groups: first, focusing on image qualities such as aesthetics and realism, and second, examining text conditions through concept coverage and fairness. We introduce an innovative aesthetic score prediction model that assesses the visual appeal of generated images and unveils the first dataset marked with low-quality regions in generated human images to facilitate automatic defect detection. Our exploration into concept coverage probes the model's effectiveness in interpreting and rendering text-based concepts accurately, while our analysis of fairness reveals biases in model outputs, with an emphasis on gender, race, and age. While our study is grounded in human imagery, this dual-faceted approach is designed with the flexibility to be applicable to other forms of image generation, enhancing our understanding of generative models and paving the way to the next generation of more sophisticated, contextually aware, and ethically attuned generative models. We will release our code, the data used for evaluating generative models and the dataset annotated with defective areas soon.
BIFRNet: A Brain-Inspired Feature Restoration DNN for Partially Occluded Image Recognition
Mar 16, 2023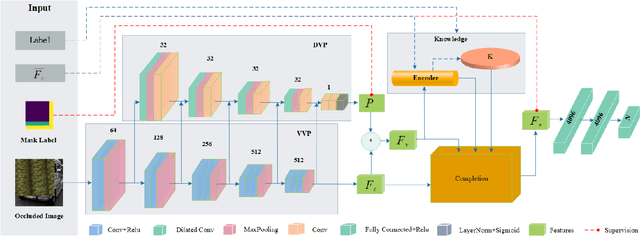


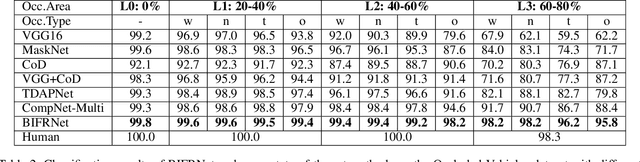
The partially occluded image recognition (POIR) problem has been a challenge for artificial intelligence for a long time. A common strategy to handle the POIR problem is using the non-occluded features for classification. Unfortunately, this strategy will lose effectiveness when the image is severely occluded, since the visible parts can only provide limited information. Several studies in neuroscience reveal that feature restoration which fills in the occluded information and is called amodal completion is essential for human brains to recognize partially occluded images. However, feature restoration is commonly ignored by CNNs, which may be the reason why CNNs are ineffective for the POIR problem. Inspired by this, we propose a novel brain-inspired feature restoration network (BIFRNet) to solve the POIR problem. It mimics a ventral visual pathway to extract image features and a dorsal visual pathway to distinguish occluded and visible image regions. In addition, it also uses a knowledge module to store object prior knowledge and uses a completion module to restore occluded features based on visible features and prior knowledge. Thorough experiments on synthetic and real-world occluded image datasets show that BIFRNet outperforms the existing methods in solving the POIR problem. Especially for severely occluded images, BIRFRNet surpasses other methods by a large margin and is close to the human brain performance. Furthermore, the brain-inspired design makes BIFRNet more interpretable.
DeepSAT: An EDA-Driven Learning Framework for SAT
May 27, 2022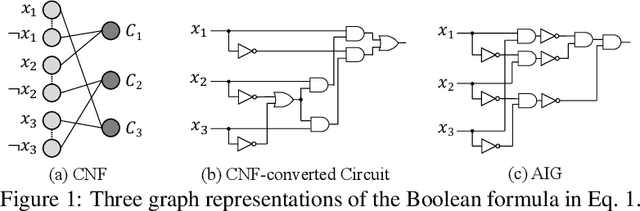
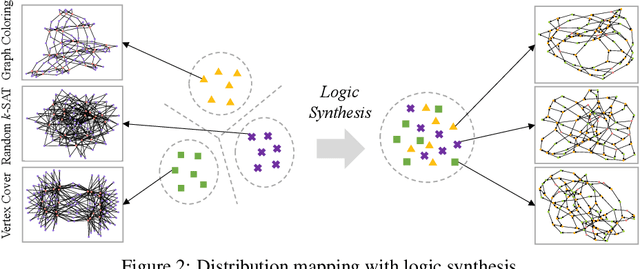
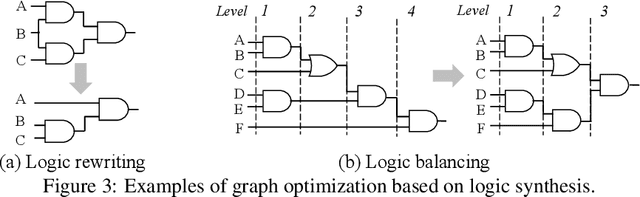
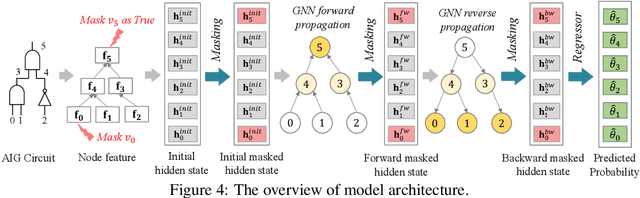
We present DeepSAT, a novel end-to-end learning framework for the Boolean satisfiability (SAT) problem. Unlike existing solutions trained on random SAT instances with relatively weak supervisions, we propose applying the knowledge of the well-developed electronic design automation (EDA) field for SAT solving. Specifically, we first resort to advanced logic synthesis algorithms to pre-process SAT instances into optimized and-inverter graphs (AIGs). By doing so, our training and test sets have a unified distribution, thus the learned model can generalize well to test sets of various sources of SAT instances. Next, we regard the distribution of SAT solutions being a product of conditional Bernoulli distributions. Based on this observation, we approximate the SAT solving procedure with a conditional generative model, leveraging a directed acyclic graph neural network with two polarity prototypes for conditional SAT modeling. To effectively train the generative model, with the help of logic simulation tools, we obtain the probabilities of nodes in the AIG being logic '1' as rich supervision. We conduct extensive experiments on various SAT instances. DeepSAT achieves significant accuracy improvements over state-of-the-art learning-based SAT solutions, especially when generalized to SAT instances that are large or with diverse distributions.
What You See is Not What the Network Infers: Detecting Adversarial Examples Based on Semantic Contradiction
Jan 24, 2022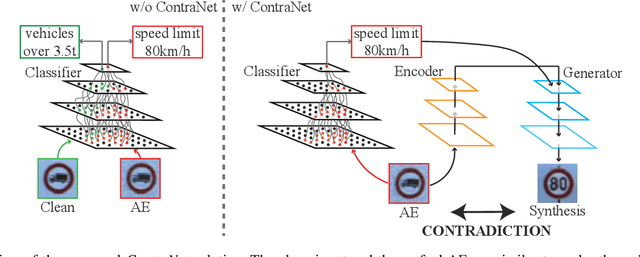



Adversarial examples (AEs) pose severe threats to the applications of deep neural networks (DNNs) to safety-critical domains, e.g., autonomous driving. While there has been a vast body of AE defense solutions, to the best of our knowledge, they all suffer from some weaknesses, e.g., defending against only a subset of AEs or causing a relatively high accuracy loss for legitimate inputs. Moreover, most existing solutions cannot defend against adaptive attacks, wherein attackers are knowledgeable about the defense mechanisms and craft AEs accordingly. In this paper, we propose a novel AE detection framework based on the very nature of AEs, i.e., their semantic information is inconsistent with the discriminative features extracted by the target DNN model. To be specific, the proposed solution, namely ContraNet, models such contradiction by first taking both the input and the inference result to a generator to obtain a synthetic output and then comparing it against the original input. For legitimate inputs that are correctly inferred, the synthetic output tries to reconstruct the input. On the contrary, for AEs, instead of reconstructing the input, the synthetic output would be created to conform to the wrong label whenever possible. Consequently, by measuring the distance between the input and the synthetic output with metric learning, we can differentiate AEs from legitimate inputs. We perform comprehensive evaluations under various AE attack scenarios, and experimental results show that ContraNet outperforms existing solutions by a large margin, especially under adaptive attacks. Moreover, our analysis shows that successful AEs that can bypass ContraNet tend to have much-weakened adversarial semantics. We have also shown that ContraNet can be easily combined with adversarial training techniques to achieve further improved AE defense capabilities.
Information Bottleneck Approach to Spatial Attention Learning
Aug 07, 2021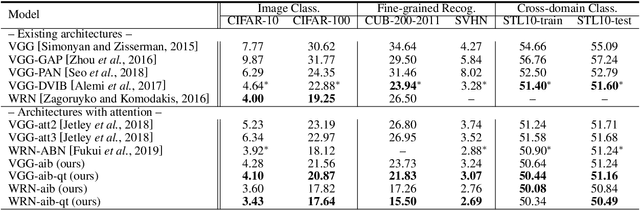

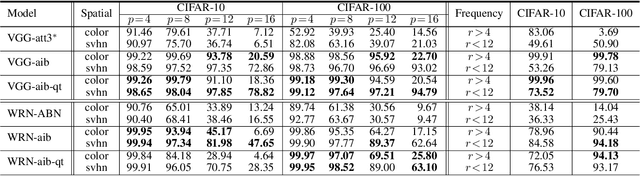
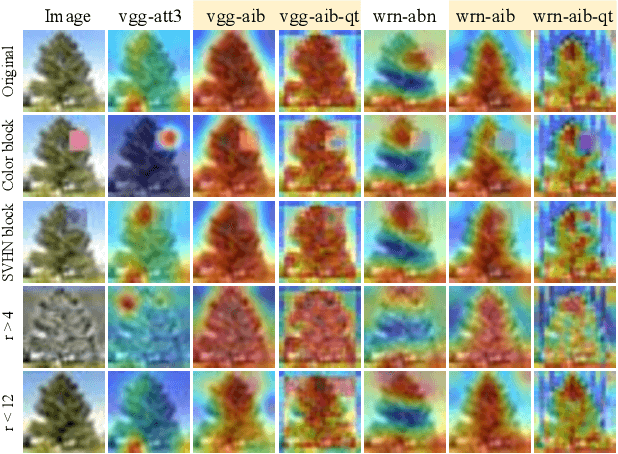
The selective visual attention mechanism in the human visual system (HVS) restricts the amount of information to reach visual awareness for perceiving natural scenes, allowing near real-time information processing with limited computational capacity [Koch and Ullman, 1987]. This kind of selectivity acts as an 'Information Bottleneck (IB)', which seeks a trade-off between information compression and predictive accuracy. However, such information constraints are rarely explored in the attention mechanism for deep neural networks (DNNs). In this paper, we propose an IB-inspired spatial attention module for DNN structures built for visual recognition. The module takes as input an intermediate representation of the input image, and outputs a variational 2D attention map that minimizes the mutual information (MI) between the attention-modulated representation and the input, while maximizing the MI between the attention-modulated representation and the task label. To further restrict the information bypassed by the attention map, we quantize the continuous attention scores to a set of learnable anchor values during training. Extensive experiments show that the proposed IB-inspired spatial attention mechanism can yield attention maps that neatly highlight the regions of interest while suppressing backgrounds, and bootstrap standard DNN structures for visual recognition tasks (e.g., image classification, fine-grained recognition, cross-domain classification). The attention maps are interpretable for the decision making of the DNNs as verified in the experiments. Our code is available at https://github.com/ashleylqx/AIB.git.