 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat You See is Not What the Network Infers: Detecting Adversarial Examples Based on Semantic Contradiction
Paper and Code
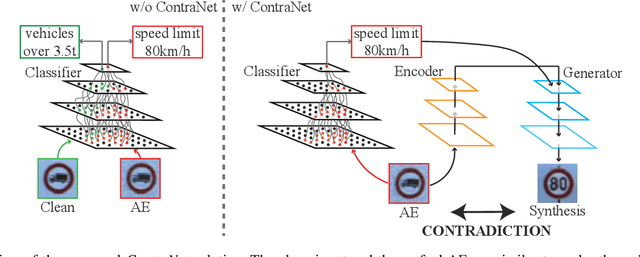



Adversarial examples (AEs) pose severe threats to the applications of deep neural networks (DNNs) to safety-critical domains, e.g., autonomous driving. While there has been a vast body of AE defense solutions, to the best of our knowledge, they all suffer from some weaknesses, e.g., defending against only a subset of AEs or causing a relatively high accuracy loss for legitimate inputs. Moreover, most existing solutions cannot defend against adaptive attacks, wherein attackers are knowledgeable about the defense mechanisms and craft AEs accordingly. In this paper, we propose a novel AE detection framework based on the very nature of AEs, i.e., their semantic information is inconsistent with the discriminative features extracted by the target DNN model. To be specific, the proposed solution, namely ContraNet, models such contradiction by first taking both the input and the inference result to a generator to obtain a synthetic output and then comparing it against the original input. For legitimate inputs that are correctly inferred, the synthetic output tries to reconstruct the input. On the contrary, for AEs, instead of reconstructing the input, the synthetic output would be created to conform to the wrong label whenever possible. Consequently, by measuring the distance between the input and the synthetic output with metric learning, we can differentiate AEs from legitimate inputs. We perform comprehensive evaluations under various AE attack scenarios, and experimental results show that ContraNet outperforms existing solutions by a large margin, especially under adaptive attacks. Moreover, our analysis shows that successful AEs that can bypass ContraNet tend to have much-weakened adversarial semantics. We have also shown that ContraNet can be easily combined with adversarial training techniques to achieve further improved AE defense capabilities.