 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChronoEdit: Towards Temporal Reasoning for Image Editing and World Simulation
Oct 05, 2025Recent advances in large generative models have significantly advanced image editing and in-context image generation, yet a critical gap remains in ensuring physical consistency, where edited objects must remain coherent. This capability is especially vital for world simulation related tasks. In this paper, we present ChronoEdit, a framework that reframes image editing as a video generation problem. First, ChronoEdit treats the input and edited images as the first and last frames of a video, allowing it to leverage large pretrained video generative models that capture not only object appearance but also the implicit physics of motion and interaction through learned temporal consistency. Second, ChronoEdit introduces a temporal reasoning stage that explicitly performs editing at inference time. Under this setting, the target frame is jointly denoised with reasoning tokens to imagine a plausible editing trajectory that constrains the solution space to physically viable transformations. The reasoning tokens are then dropped after a few steps to avoid the high computational cost of rendering a full video. To validate ChronoEdit, we introduce PBench-Edit, a new benchmark of image-prompt pairs for contexts that require physical consistency, and demonstrate that ChronoEdit surpasses state-of-the-art baselines in both visual fidelity and physical plausibility. Code and models for both the 14B and 2B variants of ChronoEdit will be released on the project page: https://research.nvidia.com/labs/toronto-ai/chronoedit
ECCV 2024 W-CODA: 1st Workshop on Multimodal Perception and Comprehension of Corner Cases in Autonomous Driving
Jul 02, 2025
In this paper, we present details of the 1st W-CODA workshop, held in conjunction with the ECCV 2024. W-CODA aims to explore next-generation solutions for autonomous driving corner cases, empowered by state-of-the-art multimodal perception and comprehension techniques. 5 Speakers from both academia and industry are invited to share their latest progress and opinions. We collect research papers and hold a dual-track challenge, including both corner case scene understanding and generation. As the pioneering effort, we will continuously bridge the gap between frontier autonomous driving techniques and fully intelligent, reliable self-driving agents robust towards corner cases.
Cosmos-Drive-Dreams: Scalable Synthetic Driving Data Generation with World Foundation Models
Jun 11, 2025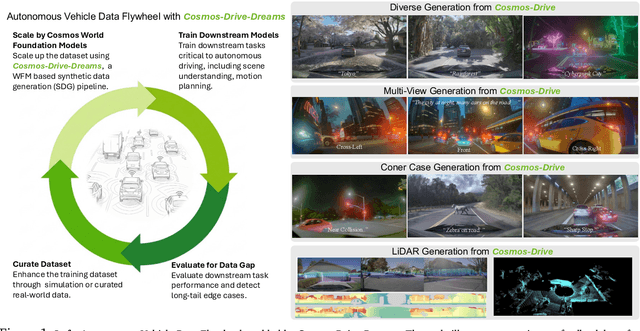
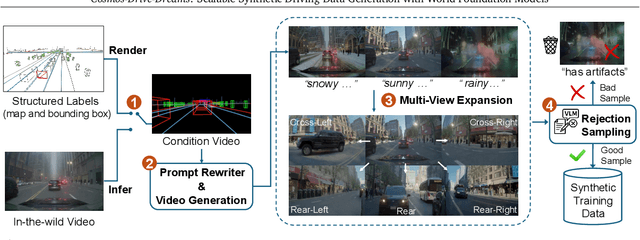
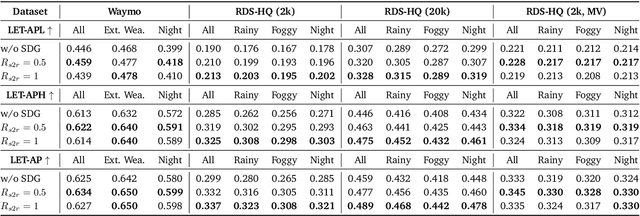
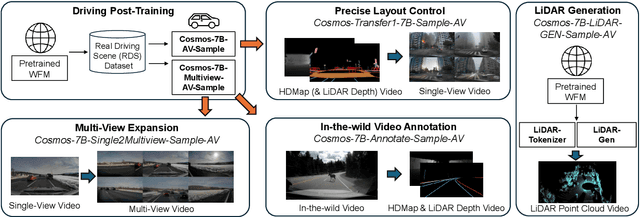
Collecting and annotating real-world data for safety-critical physical AI systems, such as Autonomous Vehicle (AV), is time-consuming and costly. It is especially challenging to capture rare edge cases, which play a critical role in training and testing of an AV system. To address this challenge, we introduce the Cosmos-Drive-Dreams - a synthetic data generation (SDG) pipeline that aims to generate challenging scenarios to facilitate downstream tasks such as perception and driving policy training. Powering this pipeline is Cosmos-Drive, a suite of models specialized from NVIDIA Cosmos world foundation model for the driving domain and are capable of controllable, high-fidelity, multi-view, and spatiotemporally consistent driving video generation. We showcase the utility of these models by applying Cosmos-Drive-Dreams to scale the quantity and diversity of driving datasets with high-fidelity and challenging scenarios. Experimentally, we demonstrate that our generated data helps in mitigating long-tail distribution problems and enhances generalization in downstream tasks such as 3D lane detection, 3D object detection and driving policy learning. We open source our pipeline toolkit, dataset and model weights through the NVIDIA's Cosmos platform. Project page: https://research.nvidia.com/labs/toronto-ai/cosmos_drive_dreams
MagicDriveDiT: High-Resolution Long Video Generation for Autonomous Driving with Adaptive Control
Nov 21, 2024The rapid advancement of diffusion models has greatly improved video synthesis, especially in controllable video generation, which is essential for applications like autonomous driving. However, existing methods are limited by scalability and how control conditions are integrated, failing to meet the needs for high-resolution and long videos for autonomous driving applications. In this paper, we introduce MagicDriveDiT, a novel approach based on the DiT architecture, and tackle these challenges. Our method enhances scalability through flow matching and employs a progressive training strategy to manage complex scenarios. By incorporating spatial-temporal conditional encoding, MagicDriveDiT achieves precise control over spatial-temporal latents. Comprehensive experiments show its superior performance in generating realistic street scene videos with higher resolution and more frames. MagicDriveDiT significantly improves video generation quality and spatial-temporal controls, expanding its potential applications across various tasks in autonomous driving.
MagicDrive3D: Controllable 3D Generation for Any-View Rendering in Street Scenes
May 23, 2024



While controllable generative models for images and videos have achieved remarkable success, high-quality models for 3D scenes, particularly in unbounded scenarios like autonomous driving, remain underdeveloped due to high data acquisition costs. In this paper, we introduce MagicDrive3D, a novel pipeline for controllable 3D street scene generation that supports multi-condition control, including BEV maps, 3D objects, and text descriptions. Unlike previous methods that reconstruct before training the generative models, MagicDrive3D first trains a video generation model and then reconstructs from the generated data. This innovative approach enables easily controllable generation and static scene acquisition, resulting in high-quality scene reconstruction. To address the minor errors in generated content, we propose deformable Gaussian splatting with monocular depth initialization and appearance modeling to manage exposure discrepancies across viewpoints. Validated on the nuScenes dataset, MagicDrive3D generates diverse, high-quality 3D driving scenes that support any-view rendering and enhance downstream tasks like BEV segmentation. Our results demonstrate the framework's superior performance, showcasing its transformative potential for autonomous driving simulation and beyond.
Automated Evaluation of Large Vision-Language Models on Self-driving Corner Cases
Apr 16, 2024



Large Vision-Language Models (LVLMs), due to the remarkable visual reasoning ability to understand images and videos, have received widespread attention in the autonomous driving domain, which significantly advances the development of interpretable end-to-end autonomous driving. However, current evaluations of LVLMs primarily focus on the multi-faceted capabilities in common scenarios, lacking quantifiable and automated assessment in autonomous driving contexts, let alone severe road corner cases that even the state-of-the-art autonomous driving perception systems struggle to handle. In this paper, we propose CODA-LM, a novel vision-language benchmark for self-driving, which provides the first automatic and quantitative evaluation of LVLMs for interpretable autonomous driving including general perception, regional perception, and driving suggestions. CODA-LM utilizes the texts to describe the road images, exploiting powerful text-only large language models (LLMs) without image inputs to assess the capabilities of LVLMs in autonomous driving scenarios, which reveals stronger alignment with human preferences than LVLM judges. Experiments demonstrate that even the closed-sourced commercial LVLMs like GPT-4V cannot deal with road corner cases well, suggesting that we are still far from a strong LVLM-powered intelligent driving agent, and we hope our CODA-LM can become the catalyst to promote future development.
DetDiffusion: Synergizing Generative and Perceptive Models for Enhanced Data Generation and Perception
Mar 20, 2024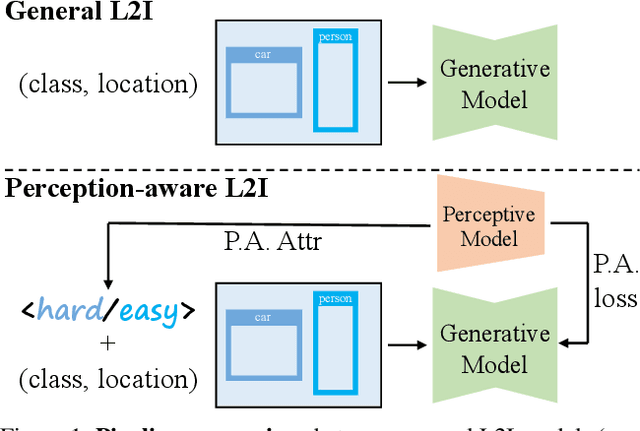
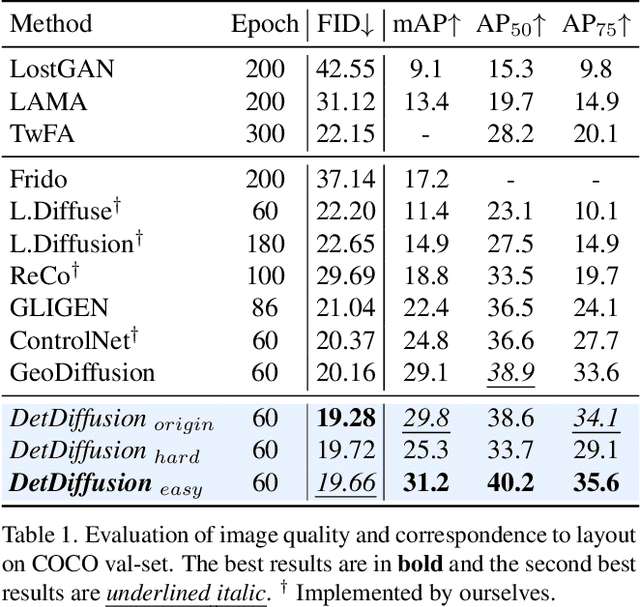
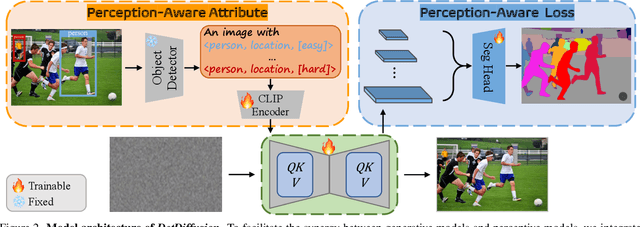
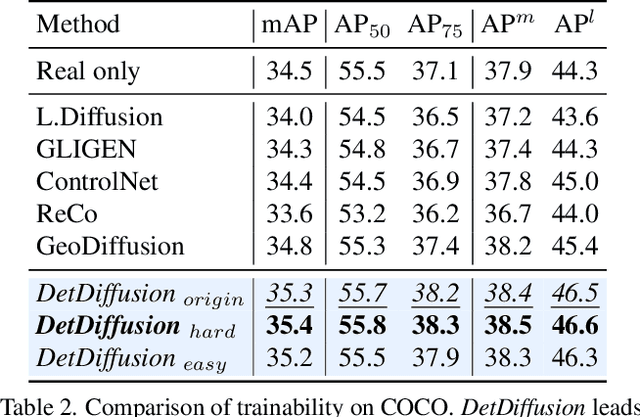
Current perceptive models heavily depend on resource-intensive datasets, prompting the need for innovative solutions. Leveraging recent advances in diffusion models, synthetic data, by constructing image inputs from various annotations, proves beneficial for downstream tasks. While prior methods have separately addressed generative and perceptive models, DetDiffusion, for the first time, harmonizes both, tackling the challenges in generating effective data for perceptive models. To enhance image generation with perceptive models, we introduce perception-aware loss (P.A. loss) through segmentation, improving both quality and controllability. To boost the performance of specific perceptive models, our method customizes data augmentation by extracting and utilizing perception-aware attribute (P.A. Attr) during generation. Experimental results from the object detection task highlight DetDiffusion's superior performance, establishing a new state-of-the-art in layout-guided generation. Furthermore, image syntheses from DetDiffusion can effectively augment training data, significantly enhancing downstream detection performance.
GuardT2I: Defending Text-to-Image Models from Adversarial Prompts
Mar 03, 2024Recent advancements in Text-to-Image (T2I) models have raised significant safety concerns about their potential misuse for generating inappropriate or Not-Safe-For-Work (NSFW) contents, despite existing countermeasures such as NSFW classifiers or model fine-tuning for inappropriate concept removal. Addressing this challenge, our study unveils GuardT2I, a novel moderation framework that adopts a generative approach to enhance T2I models' robustness against adversarial prompts. Instead of making a binary classification, GuardT2I utilizes a Large Language Model (LLM) to conditionally transform text guidance embeddings within the T2I models into natural language for effective adversarial prompt detection, without compromising the models' inherent performance. Our extensive experiments reveal that GuardT2I outperforms leading commercial solutions like OpenAI-Moderation and Microsoft Azure Moderator by a significant margin across diverse adversarial scenarios.
Non-Cross Diffusion for Semantic Consistency
Nov 30, 2023In diffusion models, deviations from a straight generative flow are a common issue, resulting in semantic inconsistencies and suboptimal generations. To address this challenge, we introduce `Non-Cross Diffusion', an innovative approach in generative modeling for learning ordinary differential equation (ODE) models. Our methodology strategically incorporates an ascending dimension of input to effectively connect points sampled from two distributions with uncrossed paths. This design is pivotal in ensuring enhanced semantic consistency throughout the inference process, which is especially critical for applications reliant on consistent generative flows, including various distillation methods and deterministic sampling, which are fundamental in image editing and interpolation tasks. Our empirical results demonstrate the effectiveness of Non-Cross Diffusion, showing a substantial reduction in semantic inconsistencies at different inference steps and a notable enhancement in the overall performance of diffusion models.
MMA-Diffusion: MultiModal Attack on Diffusion Models
Nov 29, 2023



In recent years, Text-to-Image (T2I) models have seen remarkable advancements, gaining widespread adoption. However, this progress has inadvertently opened avenues for potential misuse, particularly in generating inappropriate or Not-Safe-For-Work (NSFW) content. Our work introduces MMA-Diffusion, a framework that presents a significant and realistic threat to the security of T2I models by effectively circumventing current defensive measures in both open-source models and commercial online services. Unlike previous approaches, MMA-Diffusion leverages both textual and visual modalities to bypass safeguards like prompt filters and post-hoc safety checkers, thus exposing and highlighting the vulnerabilities in existing defense mechanisms.