 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOcc-LLM: Enhancing Autonomous Driving with Occupancy-Based Large Language Models
Feb 10, 2025Large Language Models (LLMs) have made substantial advancements in the field of robotic and autonomous driving. This study presents the first Occupancy-based Large Language Model (Occ-LLM), which represents a pioneering effort to integrate LLMs with an important representation. To effectively encode occupancy as input for the LLM and address the category imbalances associated with occupancy, we propose Motion Separation Variational Autoencoder (MS-VAE). This innovative approach utilizes prior knowledge to distinguish dynamic objects from static scenes before inputting them into a tailored Variational Autoencoder (VAE). This separation enhances the model's capacity to concentrate on dynamic trajectories while effectively reconstructing static scenes. The efficacy of Occ-LLM has been validated across key tasks, including 4D occupancy forecasting, self-ego planning, and occupancy-based scene question answering. Comprehensive evaluations demonstrate that Occ-LLM significantly surpasses existing state-of-the-art methodologies, achieving gains of about 6\% in Intersection over Union (IoU) and 4\% in mean Intersection over Union (mIoU) for the task of 4D occupancy forecasting. These findings highlight the transformative potential of Occ-LLM in reshaping current paradigms within robotic and autonomous driving.
VisionPAD: A Vision-Centric Pre-training Paradigm for Autonomous Driving
Nov 22, 2024



This paper introduces VisionPAD, a novel self-supervised pre-training paradigm designed for vision-centric algorithms in autonomous driving. In contrast to previous approaches that employ neural rendering with explicit depth supervision, VisionPAD utilizes more efficient 3D Gaussian Splatting to reconstruct multi-view representations using only images as supervision. Specifically, we introduce a self-supervised method for voxel velocity estimation. By warping voxels to adjacent frames and supervising the rendered outputs, the model effectively learns motion cues in the sequential data. Furthermore, we adopt a multi-frame photometric consistency approach to enhance geometric perception. It projects adjacent frames to the current frame based on rendered depths and relative poses, boosting the 3D geometric representation through pure image supervision. Extensive experiments on autonomous driving datasets demonstrate that VisionPAD significantly improves performance in 3D object detection, occupancy prediction and map segmentation, surpassing state-of-the-art pre-training strategies by a considerable margin.
OmniBooth: Learning Latent Control for Image Synthesis with Multi-modal Instruction
Oct 07, 2024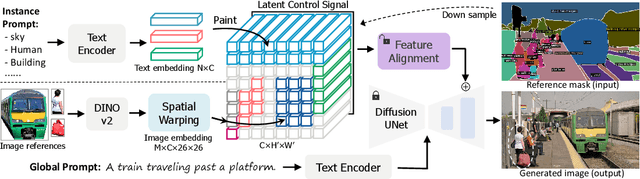
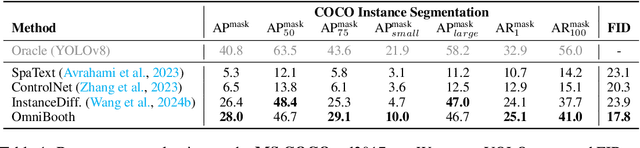
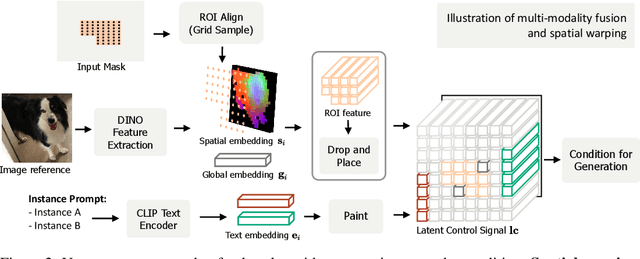
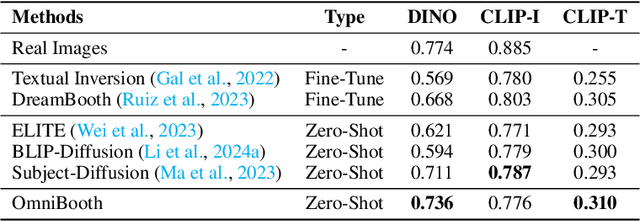
We present OmniBooth, an image generation framework that enables spatial control with instance-level multi-modal customization. For all instances, the multimodal instruction can be described through text prompts or image references. Given a set of user-defined masks and associated text or image guidance, our objective is to generate an image, where multiple objects are positioned at specified coordinates and their attributes are precisely aligned with the corresponding guidance. This approach significantly expands the scope of text-to-image generation, and elevates it to a more versatile and practical dimension in controllability. In this paper, our core contribution lies in the proposed latent control signals, a high-dimensional spatial feature that provides a unified representation to integrate the spatial, textual, and image conditions seamlessly. The text condition extends ControlNet to provide instance-level open-vocabulary generation. The image condition further enables fine-grained control with personalized identity. In practice, our method empowers users with more flexibility in controllable generation, as users can choose multi-modal conditions from text or images as needed. Furthermore, thorough experiments demonstrate our enhanced performance in image synthesis fidelity and alignment across different tasks and datasets. Project page: https://len-li.github.io/omnibooth-web/
DisEnvisioner: Disentangled and Enriched Visual Prompt for Customized Image Generation
Oct 02, 2024In the realm of image generation, creating customized images from visual prompt with additional textual instruction emerges as a promising endeavor. However, existing methods, both tuning-based and tuning-free, struggle with interpreting the subject-essential attributes from the visual prompt. This leads to subject-irrelevant attributes infiltrating the generation process, ultimately compromising the personalization quality in both editability and ID preservation. In this paper, we present DisEnvisioner, a novel approach for effectively extracting and enriching the subject-essential features while filtering out -irrelevant information, enabling exceptional customization performance, in a tuning-free manner and using only a single image. Specifically, the feature of the subject and other irrelevant components are effectively separated into distinctive visual tokens, enabling a much more accurate customization. Aiming to further improving the ID consistency, we enrich the disentangled features, sculpting them into more granular representations. Experiments demonstrate the superiority of our approach over existing methods in instruction response (editability), ID consistency, inference speed, and the overall image quality, highlighting the effectiveness and efficiency of DisEnvisioner. Project page: https://disenvisioner.github.io/.
DetDiffusion: Synergizing Generative and Perceptive Models for Enhanced Data Generation and Perception
Mar 20, 2024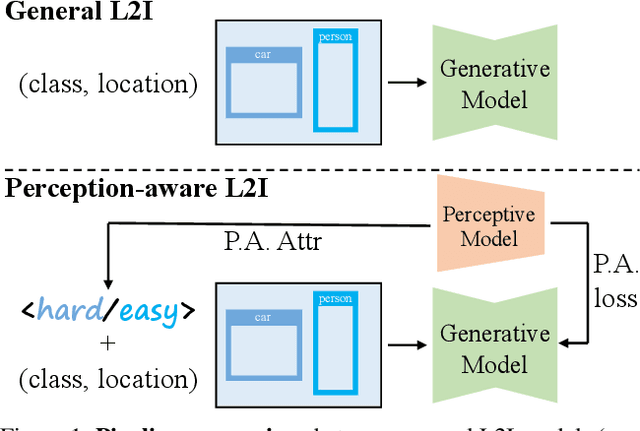
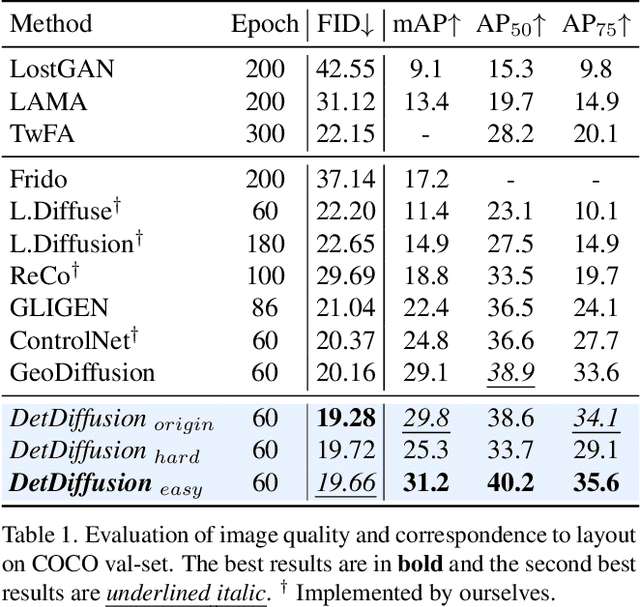
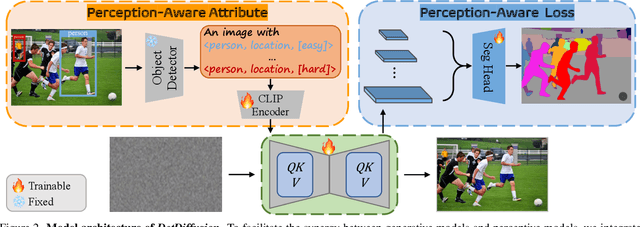
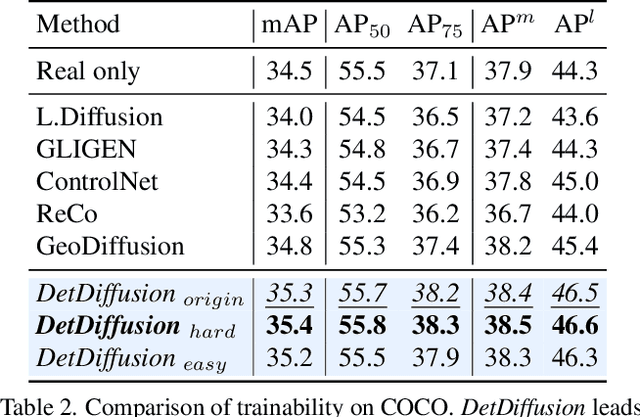
Current perceptive models heavily depend on resource-intensive datasets, prompting the need for innovative solutions. Leveraging recent advances in diffusion models, synthetic data, by constructing image inputs from various annotations, proves beneficial for downstream tasks. While prior methods have separately addressed generative and perceptive models, DetDiffusion, for the first time, harmonizes both, tackling the challenges in generating effective data for perceptive models. To enhance image generation with perceptive models, we introduce perception-aware loss (P.A. loss) through segmentation, improving both quality and controllability. To boost the performance of specific perceptive models, our method customizes data augmentation by extracting and utilizing perception-aware attribute (P.A. Attr) during generation. Experimental results from the object detection task highlight DetDiffusion's superior performance, establishing a new state-of-the-art in layout-guided generation. Furthermore, image syntheses from DetDiffusion can effectively augment training data, significantly enhancing downstream detection performance.
Forging Vision Foundation Models for Autonomous Driving: Challenges, Methodologies, and Opportunities
Jan 16, 2024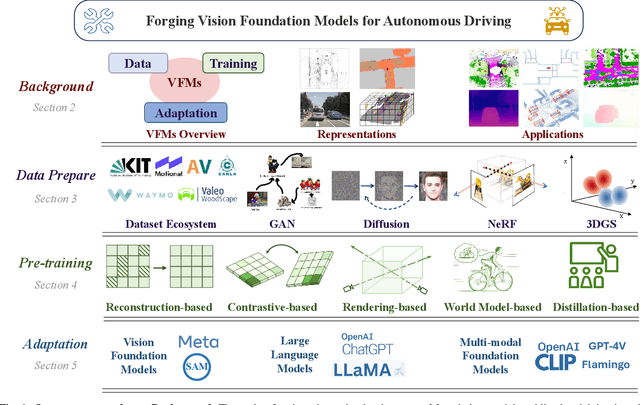
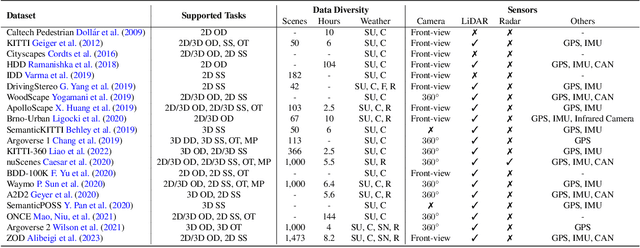
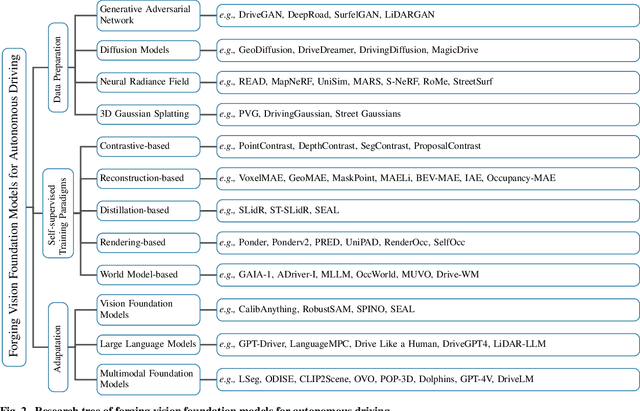

The rise of large foundation models, trained on extensive datasets, is revolutionizing the field of AI. Models such as SAM, DALL-E2, and GPT-4 showcase their adaptability by extracting intricate patterns and performing effectively across diverse tasks, thereby serving as potent building blocks for a wide range of AI applications. Autonomous driving, a vibrant front in AI applications, remains challenged by the lack of dedicated vision foundation models (VFMs). The scarcity of comprehensive training data, the need for multi-sensor integration, and the diverse task-specific architectures pose significant obstacles to the development of VFMs in this field. This paper delves into the critical challenge of forging VFMs tailored specifically for autonomous driving, while also outlining future directions. Through a systematic analysis of over 250 papers, we dissect essential techniques for VFM development, including data preparation, pre-training strategies, and downstream task adaptation. Moreover, we explore key advancements such as NeRF, diffusion models, 3D Gaussian Splatting, and world models, presenting a comprehensive roadmap for future research. To empower researchers, we have built and maintained https://github.com/zhanghm1995/Forge_VFM4AD, an open-access repository constantly updated with the latest advancements in forging VFMs for autonomous driving.
NDC-Scene: Boost Monocular 3D Semantic Scene Completion in Normalized Device Coordinates Space
Sep 27, 2023Monocular 3D Semantic Scene Completion (SSC) has garnered significant attention in recent years due to its potential to predict complex semantics and geometry shapes from a single image, requiring no 3D inputs. In this paper, we identify several critical issues in current state-of-the-art methods, including the Feature Ambiguity of projected 2D features in the ray to the 3D space, the Pose Ambiguity of the 3D convolution, and the Computation Imbalance in the 3D convolution across different depth levels. To address these problems, we devise a novel Normalized Device Coordinates scene completion network (NDC-Scene) that directly extends the 2D feature map to a Normalized Device Coordinates (NDC) space, rather than to the world space directly, through progressive restoration of the dimension of depth with deconvolution operations. Experiment results demonstrate that transferring the majority of computation from the target 3D space to the proposed normalized device coordinates space benefits monocular SSC tasks. Additionally, we design a Depth-Adaptive Dual Decoder to simultaneously upsample and fuse the 2D and 3D feature maps, further improving overall performance. Our extensive experiments confirm that the proposed method consistently outperforms state-of-the-art methods on both outdoor SemanticKITTI and indoor NYUv2 datasets. Our code are available at https://github.com/Jiawei-Yao0812/NDCScene.
FeatAug-DETR: Enriching One-to-Many Matching for DETRs with Feature Augmentation
Mar 02, 2023



One-to-one matching is a crucial design in DETR-like object detection frameworks. It enables the DETR to perform end-to-end detection. However, it also faces challenges of lacking positive sample supervision and slow convergence speed. Several recent works proposed the one-to-many matching mechanism to accelerate training and boost detection performance. We revisit these methods and model them in a unified format of augmenting the object queries. In this paper, we propose two methods that realize one-to-many matching from a different perspective of augmenting images or image features. The first method is One-to-many Matching via Data Augmentation (denoted as DataAug-DETR). It spatially transforms the images and includes multiple augmented versions of each image in the same training batch. Such a simple augmentation strategy already achieves one-to-many matching and surprisingly improves DETR's performance. The second method is One-to-many matching via Feature Augmentation (denoted as FeatAug-DETR). Unlike DataAug-DETR, it augments the image features instead of the original images and includes multiple augmented features in the same batch to realize one-to-many matching. FeatAug-DETR significantly accelerates DETR training and boosts detection performance while keeping the inference speed unchanged. We conduct extensive experiments to evaluate the effectiveness of the proposed approach on DETR variants, including DAB-DETR, Deformable-DETR, and H-Deformable-DETR. Without extra training data, FeatAug-DETR shortens the training convergence periods of Deformable-DETR to 24 epochs and achieves 58.3 AP on COCO val2017 set with Swin-L as the backbone.
Learning a Structured Latent Space for Unsupervised Point Cloud Completion
Mar 29, 2022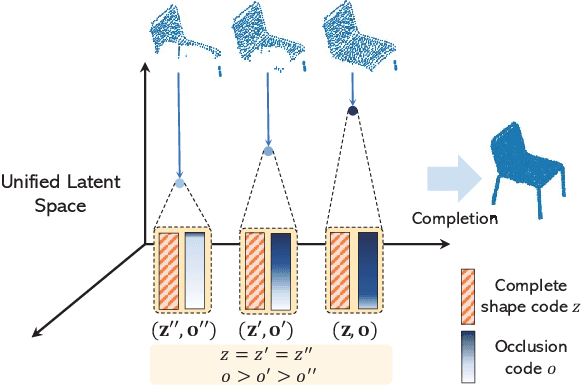

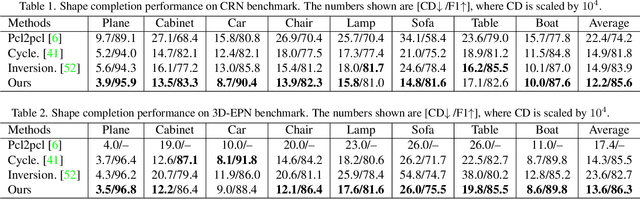
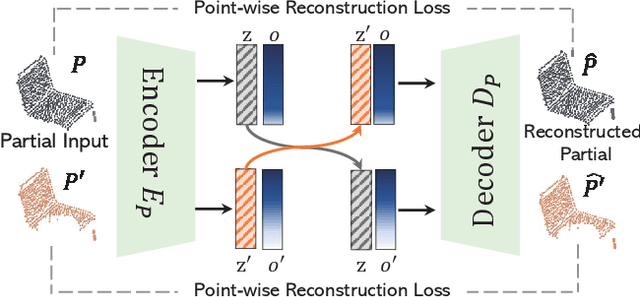
Unsupervised point cloud completion aims at estimating the corresponding complete point cloud of a partial point cloud in an unpaired manner. It is a crucial but challenging problem since there is no paired partial-complete supervision that can be exploited directly. In this work, we propose a novel framework, which learns a unified and structured latent space that encoding both partial and complete point clouds. Specifically, we map a series of related partial point clouds into multiple complete shape and occlusion code pairs and fuse the codes to obtain their representations in the unified latent space. To enforce the learning of such a structured latent space, the proposed method adopts a series of constraints including structured ranking regularization, latent code swapping constraint, and distribution supervision on the related partial point clouds. By establishing such a unified and structured latent space, better partial-complete geometry consistency and shape completion accuracy can be achieved. Extensive experiments show that our proposed method consistently outperforms state-of-the-art unsupervised methods on both synthetic ShapeNet and real-world KITTI, ScanNet, and Matterport3D datasets.
* 8 pages, 5 figures, cvpr2022
Semantic Scene Completion via Integrating Instances and Scene in-the-Loop
Apr 08, 2021


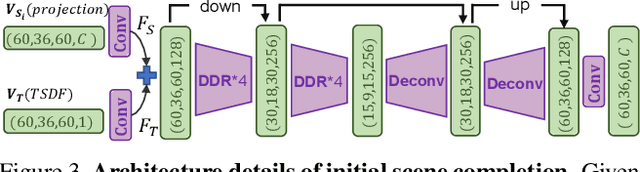
Semantic Scene Completion aims at reconstructing a complete 3D scene with precise voxel-wise semantics from a single-view depth or RGBD image. It is a crucial but challenging problem for indoor scene understanding. In this work, we present a novel framework named Scene-Instance-Scene Network (\textit{SISNet}), which takes advantages of both instance and scene level semantic information. Our method is capable of inferring fine-grained shape details as well as nearby objects whose semantic categories are easily mixed-up. The key insight is that we decouple the instances from a coarsely completed semantic scene instead of a raw input image to guide the reconstruction of instances and the overall scene. SISNet conducts iterative scene-to-instance (SI) and instance-to-scene (IS) semantic completion. Specifically, the SI is able to encode objects' surrounding context for effectively decoupling instances from the scene and each instance could be voxelized into higher resolution to capture finer details. With IS, fine-grained instance information can be integrated back into the 3D scene and thus leads to more accurate semantic scene completion. Utilizing such an iterative mechanism, the scene and instance completion benefits each other to achieve higher completion accuracy. Extensively experiments show that our proposed method consistently outperforms state-of-the-art methods on both real NYU, NYUCAD and synthetic SUNCG-RGBD datasets. The code and the supplementary material will be available at \url{https://github.com/yjcaimeow/SISNet}.