 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Scene Completion via Integrating Instances and Scene in-the-Loop
Paper and Code



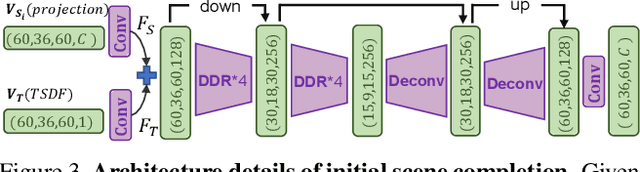
Semantic Scene Completion aims at reconstructing a complete 3D scene with precise voxel-wise semantics from a single-view depth or RGBD image. It is a crucial but challenging problem for indoor scene understanding. In this work, we present a novel framework named Scene-Instance-Scene Network (\textit{SISNet}), which takes advantages of both instance and scene level semantic information. Our method is capable of inferring fine-grained shape details as well as nearby objects whose semantic categories are easily mixed-up. The key insight is that we decouple the instances from a coarsely completed semantic scene instead of a raw input image to guide the reconstruction of instances and the overall scene. SISNet conducts iterative scene-to-instance (SI) and instance-to-scene (IS) semantic completion. Specifically, the SI is able to encode objects' surrounding context for effectively decoupling instances from the scene and each instance could be voxelized into higher resolution to capture finer details. With IS, fine-grained instance information can be integrated back into the 3D scene and thus leads to more accurate semantic scene completion. Utilizing such an iterative mechanism, the scene and instance completion benefits each other to achieve higher completion accuracy. Extensively experiments show that our proposed method consistently outperforms state-of-the-art methods on both real NYU, NYUCAD and synthetic SUNCG-RGBD datasets. The code and the supplementary material will be available at \url{https://github.com/yjcaimeow/SISNet}.