 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisually-grounded Humanoid Agents
Apr 09, 2026Digital human generation has been studied for decades and supports a wide range of real-world applications. However, most existing systems are passively animated, relying on privileged state or scripted control, which limits scalability to novel environments. We instead ask: how can digital humans actively behave using only visual observations and specified goals in novel scenes? Achieving this would enable populating any 3D environments with digital humans at scale that exhibit spontaneous, natural, goal-directed behaviors. To this end, we introduce Visually-grounded Humanoid Agents, a coupled two-layer (world-agent) paradigm that replicates humans at multiple levels: they look, perceive, reason, and behave like real people in real-world 3D scenes. The World Layer reconstructs semantically rich 3D Gaussian scenes from real-world videos via an occlusion-aware pipeline and accommodates animatable Gaussian-based human avatars. The Agent Layer transforms these avatars into autonomous humanoid agents, equipping them with first-person RGB-D perception and enabling them to perform accurate, embodied planning with spatial awareness and iterative reasoning, which is then executed at the low level as full-body actions to drive their behaviors in the scene. We further introduce a benchmark to evaluate humanoid-scene interaction in diverse reconstructed environments. Experiments show our agents achieve robust autonomous behavior, yielding higher task success rates and fewer collisions than ablations and state-of-the-art planning methods. This work enables active digital human population and advances human-centric embodied AI. Data, code, and models will be open-sourced.
Let Humanoids Hike! Integrative Skill Development on Complex Trails
May 09, 2025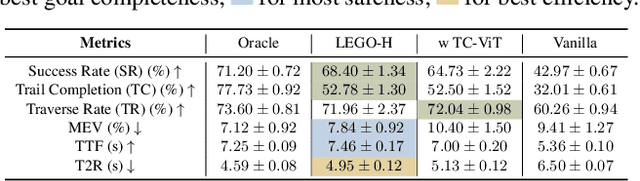
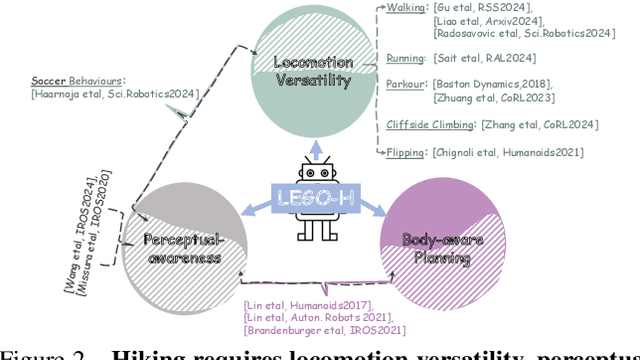
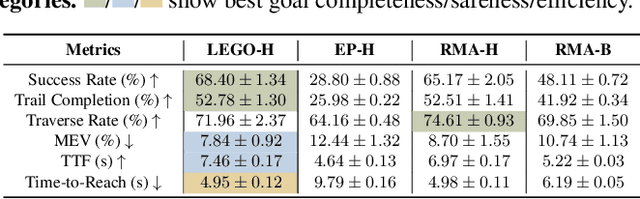
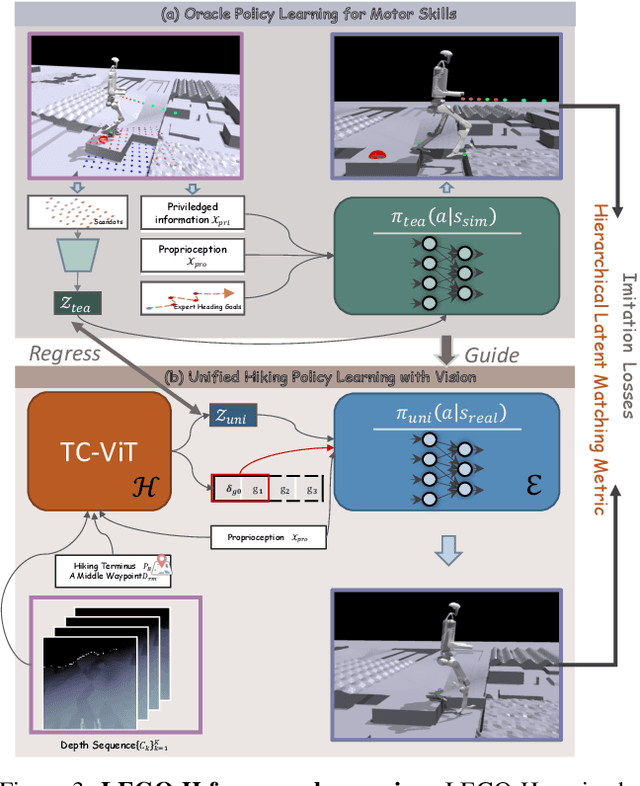
Hiking on complex trails demands balance, agility, and adaptive decision-making over unpredictable terrain. Current humanoid research remains fragmented and inadequate for hiking: locomotion focuses on motor skills without long-term goals or situational awareness, while semantic navigation overlooks real-world embodiment and local terrain variability. We propose training humanoids to hike on complex trails, driving integrative skill development across visual perception, decision making, and motor execution. We develop a learning framework, LEGO-H, that enables a vision-equipped humanoid robot to hike complex trails autonomously. We introduce two technical innovations: 1) A temporal vision transformer variant - tailored into Hierarchical Reinforcement Learning framework - anticipates future local goals to guide movement, seamlessly integrating locomotion with goal-directed navigation. 2) Latent representations of joint movement patterns, combined with hierarchical metric learning - enhance Privileged Learning scheme - enable smooth policy transfer from privileged training to onboard execution. These components allow LEGO-H to handle diverse physical and environmental challenges without relying on predefined motion patterns. Experiments across varied simulated trails and robot morphologies highlight LEGO-H's versatility and robustness, positioning hiking as a compelling testbed for embodied autonomy and LEGO-H as a baseline for future humanoid development.
TimeWalker: Personalized Neural Space for Lifelong Head Avatars
Dec 03, 2024



We present TimeWalker, a novel framework that models realistic, full-scale 3D head avatars of a person on lifelong scale. Unlike current human head avatar pipelines that capture identity at the momentary level(e.g., instant photography or short videos), TimeWalker constructs a person's comprehensive identity from unstructured data collection over his/her various life stages, offering a paradigm to achieve full reconstruction and animation of that person at different moments of life. At the heart of TimeWalker's success is a novel neural parametric model that learns personalized representation with the disentanglement of shape, expression, and appearance across ages. Central to our methodology are the concepts of two aspects: (1) We track back to the principle of modeling a person's identity in an additive combination of average head representation in the canonical space, and moment-specific head attribute representations driven from a set of neural head basis. To learn the set of head basis that could represent the comprehensive head variations in a compact manner, we propose a Dynamic Neural Basis-Blending Module (Dynamo). It dynamically adjusts the number and blend weights of neural head bases, according to both shared and specific traits of the target person over ages. (2) Dynamic 2D Gaussian Splatting (DNA-2DGS), an extension of Gaussian splatting representation, to model head motion deformations like facial expressions without losing the realism of rendering and reconstruction. DNA-2DGS includes a set of controllable 2D oriented planar Gaussian disks that utilize the priors from parametric model, and move/rotate with the change of expression. Through extensive experimental evaluations, we show TimeWalker's ability to reconstruct and animate avatars across decoupled dimensions with realistic rendering effects, demonstrating a way to achieve personalized 'time traveling' in a breeze.
Urban Architect: Steerable 3D Urban Scene Generation with Layout Prior
Apr 10, 2024
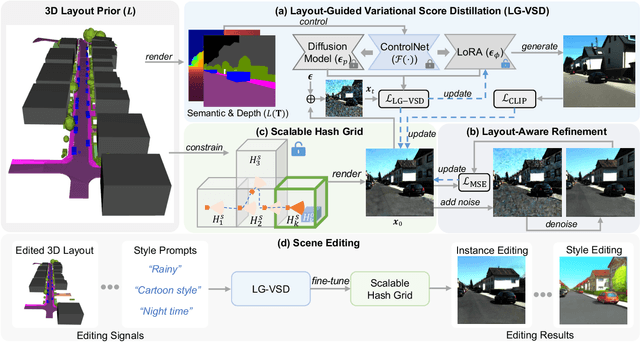
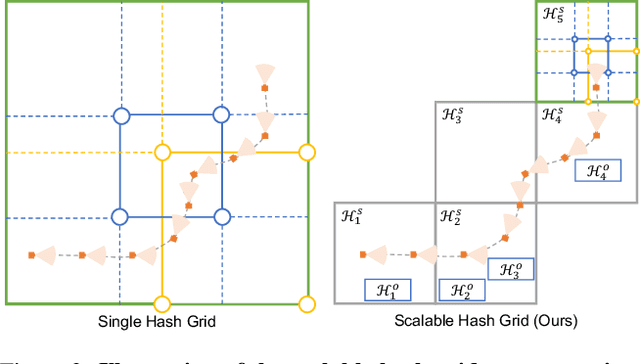

Text-to-3D generation has achieved remarkable success via large-scale text-to-image diffusion models. Nevertheless, there is no paradigm for scaling up the methodology to urban scale. Urban scenes, characterized by numerous elements, intricate arrangement relationships, and vast scale, present a formidable barrier to the interpretability of ambiguous textual descriptions for effective model optimization. In this work, we surmount the limitations by introducing a compositional 3D layout representation into text-to-3D paradigm, serving as an additional prior. It comprises a set of semantic primitives with simple geometric structures and explicit arrangement relationships, complementing textual descriptions and enabling steerable generation. Upon this, we propose two modifications -- (1) We introduce Layout-Guided Variational Score Distillation to address model optimization inadequacies. It conditions the score distillation sampling process with geometric and semantic constraints of 3D layouts. (2) To handle the unbounded nature of urban scenes, we represent 3D scene with a Scalable Hash Grid structure, incrementally adapting to the growing scale of urban scenes. Extensive experiments substantiate the capability of our framework to scale text-to-3D generation to large-scale urban scenes that cover over 1000m driving distance for the first time. We also present various scene editing demonstrations, showing the powers of steerable urban scene generation. Website: https://urbanarchitect.github.io.
CosmicMan: A Text-to-Image Foundation Model for Humans
Apr 01, 2024



We present CosmicMan, a text-to-image foundation model specialized for generating high-fidelity human images. Unlike current general-purpose foundation models that are stuck in the dilemma of inferior quality and text-image misalignment for humans, CosmicMan enables generating photo-realistic human images with meticulous appearance, reasonable structure, and precise text-image alignment with detailed dense descriptions. At the heart of CosmicMan's success are the new reflections and perspectives on data and models: (1) We found that data quality and a scalable data production flow are essential for the final results from trained models. Hence, we propose a new data production paradigm, Annotate Anyone, which serves as a perpetual data flywheel to produce high-quality data with accurate yet cost-effective annotations over time. Based on this, we constructed a large-scale dataset, CosmicMan-HQ 1.0, with 6 Million high-quality real-world human images in a mean resolution of 1488x1255, and attached with precise text annotations deriving from 115 Million attributes in diverse granularities. (2) We argue that a text-to-image foundation model specialized for humans must be pragmatic -- easy to integrate into down-streaming tasks while effective in producing high-quality human images. Hence, we propose to model the relationship between dense text descriptions and image pixels in a decomposed manner, and present Decomposed-Attention-Refocusing (Daring) training framework. It seamlessly decomposes the cross-attention features in existing text-to-image diffusion model, and enforces attention refocusing without adding extra modules. Through Daring, we show that explicitly discretizing continuous text space into several basic groups that align with human body structure is the key to tackling the misalignment problem in a breeze.
Bi-directional Deformation for Parameterization of Neural Implicit Surfaces
Oct 09, 2023The growing capabilities of neural rendering have increased the demand for new techniques that enable the intuitive editing of 3D objects, particularly when they are represented as neural implicit surfaces. In this paper, we present a novel neural algorithm to parameterize neural implicit surfaces to simple parametric domains, such as spheres, cubes or polycubes, where 3D radiance field can be represented as a 2D field, thereby facilitating visualization and various editing tasks. Technically, our method computes a bi-directional deformation between 3D objects and their chosen parametric domains, eliminating the need for any prior information. We adopt a forward mapping of points on the zero level set of the 3D object to a parametric domain, followed by a backward mapping through inverse deformation. To ensure the map is bijective, we employ a cycle loss while optimizing the smoothness of both deformations. Additionally, we leverage a Laplacian regularizer to effectively control angle distortion and offer the flexibility to choose from a range of parametric domains for managing area distortion. Designed for compatibility, our framework integrates seamlessly with existing neural rendering pipelines, taking multi-view images as input to reconstruct 3D geometry and compute the corresponding texture map. We also introduce a simple yet effective technique for intrinsic radiance decomposition, facilitating both view-independent material editing and view-dependent shading editing. Our method allows for the immediate rendering of edited textures through volume rendering, without the need for network re-training. Moreover, our approach supports the co-parameterization of multiple objects and enables texture transfer between them. We demonstrate the effectiveness of our method on images of human heads and man-made objects. We will make the source code publicly available.
UnitedHuman: Harnessing Multi-Source Data for High-Resolution Human Generation
Sep 25, 2023
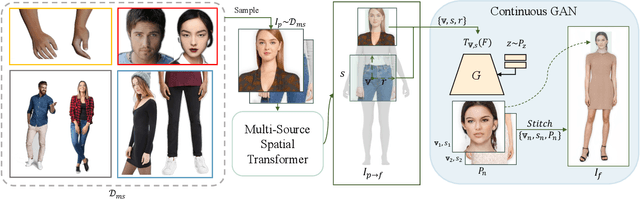

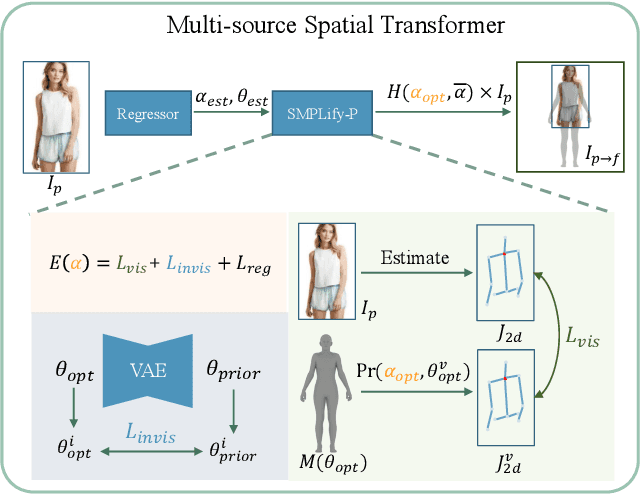
Human generation has achieved significant progress. Nonetheless, existing methods still struggle to synthesize specific regions such as faces and hands. We argue that the main reason is rooted in the training data. A holistic human dataset inevitably has insufficient and low-resolution information on local parts. Therefore, we propose to use multi-source datasets with various resolution images to jointly learn a high-resolution human generative model. However, multi-source data inherently a) contains different parts that do not spatially align into a coherent human, and b) comes with different scales. To tackle these challenges, we propose an end-to-end framework, UnitedHuman, that empowers continuous GAN with the ability to effectively utilize multi-source data for high-resolution human generation. Specifically, 1) we design a Multi-Source Spatial Transformer that spatially aligns multi-source images to full-body space with a human parametric model. 2) Next, a continuous GAN is proposed with global-structural guidance and CutMix consistency. Patches from different datasets are then sampled and transformed to supervise the training of this scale-invariant generative model. Extensive experiments demonstrate that our model jointly learned from multi-source data achieves superior quality than those learned from a holistic dataset.
Urban Radiance Field Representation with Deformable Neural Mesh Primitives
Jul 20, 2023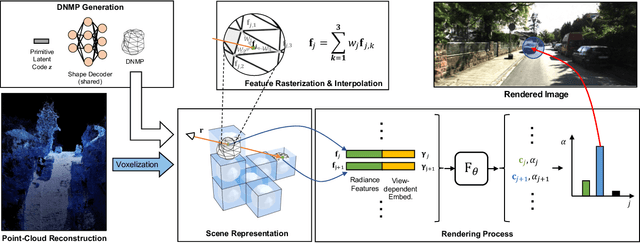

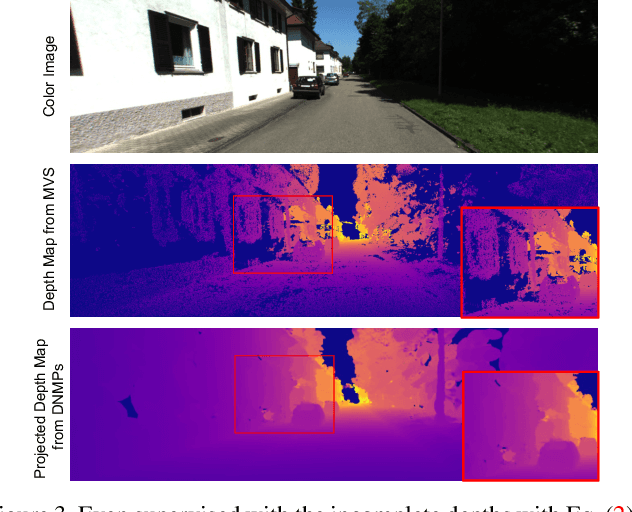

Neural Radiance Fields (NeRFs) have achieved great success in the past few years. However, most current methods still require intensive resources due to ray marching-based rendering. To construct urban-level radiance fields efficiently, we design Deformable Neural Mesh Primitive~(DNMP), and propose to parameterize the entire scene with such primitives. The DNMP is a flexible and compact neural variant of classic mesh representation, which enjoys both the efficiency of rasterization-based rendering and the powerful neural representation capability for photo-realistic image synthesis. Specifically, a DNMP consists of a set of connected deformable mesh vertices with paired vertex features to parameterize the geometry and radiance information of a local area. To constrain the degree of freedom for optimization and lower the storage budgets, we enforce the shape of each primitive to be decoded from a relatively low-dimensional latent space. The rendering colors are decoded from the vertex features (interpolated with rasterization) by a view-dependent MLP. The DNMP provides a new paradigm for urban-level scene representation with appealing properties: $(1)$ High-quality rendering. Our method achieves leading performance for novel view synthesis in urban scenarios. $(2)$ Low computational costs. Our representation enables fast rendering (2.07ms/1k pixels) and low peak memory usage (110MB/1k pixels). We also present a lightweight version that can run 33$\times$ faster than vanilla NeRFs, and comparable to the highly-optimized Instant-NGP (0.61 vs 0.71ms/1k pixels). Project page: \href{https://dnmp.github.io/}{https://dnmp.github.io/}.
DNA-Rendering: A Diverse Neural Actor Repository for High-Fidelity Human-centric Rendering
Jul 19, 2023
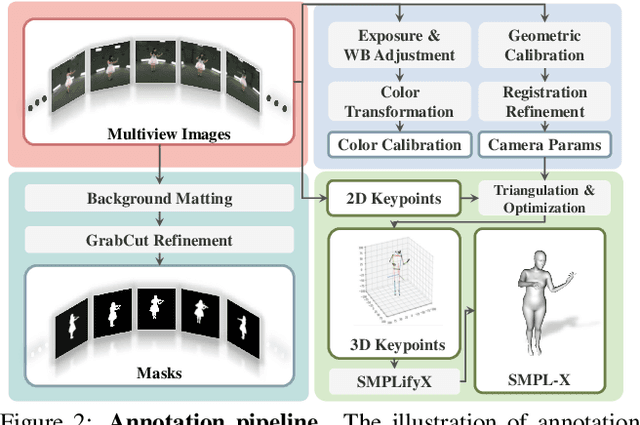
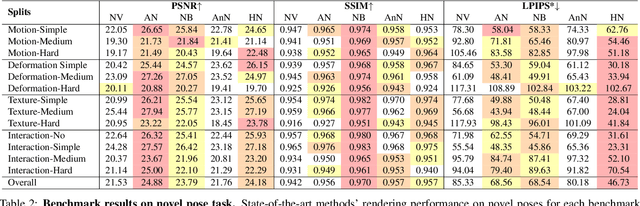

Realistic human-centric rendering plays a key role in both computer vision and computer graphics. Rapid progress has been made in the algorithm aspect over the years, yet existing human-centric rendering datasets and benchmarks are rather impoverished in terms of diversity, which are crucial for rendering effect. Researchers are usually constrained to explore and evaluate a small set of rendering problems on current datasets, while real-world applications require methods to be robust across different scenarios. In this work, we present DNA-Rendering, a large-scale, high-fidelity repository of human performance data for neural actor rendering. DNA-Rendering presents several alluring attributes. First, our dataset contains over 1500 human subjects, 5000 motion sequences, and 67.5M frames' data volume. Second, we provide rich assets for each subject -- 2D/3D human body keypoints, foreground masks, SMPLX models, cloth/accessory materials, multi-view images, and videos. These assets boost the current method's accuracy on downstream rendering tasks. Third, we construct a professional multi-view system to capture data, which contains 60 synchronous cameras with max 4096 x 3000 resolution, 15 fps speed, and stern camera calibration steps, ensuring high-quality resources for task training and evaluation. Along with the dataset, we provide a large-scale and quantitative benchmark in full-scale, with multiple tasks to evaluate the existing progress of novel view synthesis, novel pose animation synthesis, and novel identity rendering methods. In this manuscript, we describe our DNA-Rendering effort as a revealing of new observations, challenges, and future directions to human-centric rendering. The dataset, code, and benchmarks will be publicly available at https://dna-rendering.github.io/
RenderMe-360: A Large Digital Asset Library and Benchmarks Towards High-fidelity Head Avatars
May 22, 2023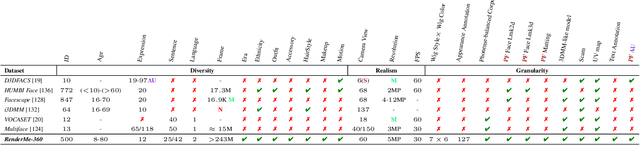
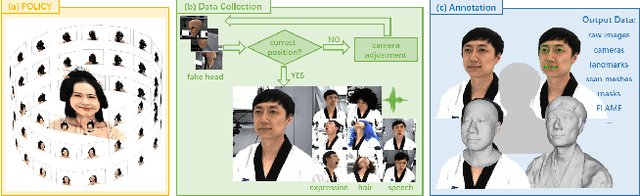


Synthesizing high-fidelity head avatars is a central problem for computer vision and graphics. While head avatar synthesis algorithms have advanced rapidly, the best ones still face great obstacles in real-world scenarios. One of the vital causes is inadequate datasets -- 1) current public datasets can only support researchers to explore high-fidelity head avatars in one or two task directions; 2) these datasets usually contain digital head assets with limited data volume, and narrow distribution over different attributes. In this paper, we present RenderMe-360, a comprehensive 4D human head dataset to drive advance in head avatar research. It contains massive data assets, with 243+ million complete head frames, and over 800k video sequences from 500 different identities captured by synchronized multi-view cameras at 30 FPS. It is a large-scale digital library for head avatars with three key attributes: 1) High Fidelity: all subjects are captured by 60 synchronized, high-resolution 2K cameras in 360 degrees. 2) High Diversity: The collected subjects vary from different ages, eras, ethnicities, and cultures, providing abundant materials with distinctive styles in appearance and geometry. Moreover, each subject is asked to perform various motions, such as expressions and head rotations, which further extend the richness of assets. 3) Rich Annotations: we provide annotations with different granularities: cameras' parameters, matting, scan, 2D/3D facial landmarks, FLAME fitting, and text description. Based on the dataset, we build a comprehensive benchmark for head avatar research, with 16 state-of-the-art methods performed on five main tasks: novel view synthesis, novel expression synthesis, hair rendering, hair editing, and talking head generation. Our experiments uncover the strengths and weaknesses of current methods. RenderMe-360 opens the door for future exploration in head avatars.